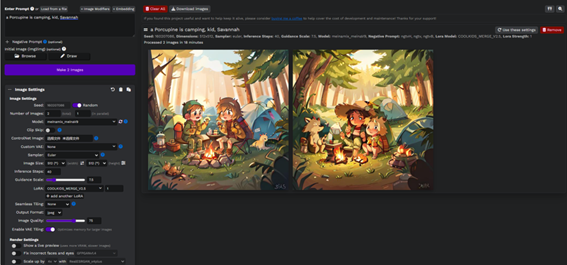
上图是老徐用的2G显存的N卡GPU设置的为low跑出来的效果
Easy Diffusion 出来已经一段时间了,当前最新版本3.0,新版本更新内容很多。
动手能力强的小伙伴已经开始各种花式出图了,是不是苦于安装的复杂、繁杂的参数设置?来吧,现在又有了一个新的选择。
Easy Diffusion 项目地址:https://github.com/cmdr2/stable-diffusion-ui
最新版3.0安装包下载地址:
Windows:https://github.com/cmdr2/stable-diffusion-ui/releases/latest/download/Easy-Diffusion-Windows.exe
MacOs:https://github.com/cmdr2/stable-diffusion-ui/releases/latest/download/Easy-Diffusion-Mac.zip
Linux:https://github.com/cmdr2/stable-diffusion-ui/releases/latest/download/Easy-Diffusion-Linux.zip
安装
硬件要求:
Windows10/11, 或 Linux/Mac/一张NVIDIA显卡,最好是4G以上显存。如果没有,它会自动使用CPU模式最低8G内存和25G硬盘空间。
像ReadMe中介绍的一样:The
easiest way to install and use Stable Diffusion on your computer!这是号称全网最容易的安装部署Stable Diffusion的项目。你可以完全不具备任何技术知识,也不需要配置什么软件环境。所有的操作只有两步:
小提示:
在WIndows10下尽量安装在顶级目录,类似 C:\EasyDiffusion 这样的。这是因为Windows10文件夹名有长度限制,如果安装目录本身过长,会导致运行的时候出错。
下载的时候会自动下载依赖的库和模型等资料。所以务必保证网络通畅。大概需要下载几个G的资料。
点击安装
双击下载的安装包,然后根据提示一直下一步即可。它会在你桌面或开始菜单上加入一个快捷方式。启动也是一键启动。
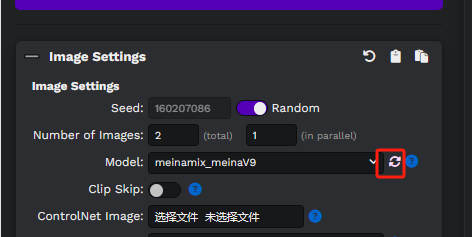
安装模型
小伙伴肯定不会使用原生模型来作图。现在谁手上还没个几百G的模型呢。那么下载的模型怎么安装呢。
下载模型后拷贝到 models\stable-diffusion目录下。
Lora类型的放到models\lora目录下。
在界面上刷新模型列表
官方特性描述
用户体验
无忧安装:不需要技术知识,也不需要预先安装软件。只需下载并运行!
简洁的用户界面:友好且简单的用户界面,同时提供许多强大的功能。
任务队列:排队等待您所有的想法,无需等待当前任务完成。
智能模型检测:自动找出要用于所选择的模型的YAML配置文件(通过模型数据库)。
实时预览:看到AI绘制图像的同时,即时预览。
图像修改器:包含许多标签的修改器库,例如“逼真”,“铅笔素描”,“ArtStation”等。快速尝试不同的样式。
多个提示文件:输入每行一个提示或通过运行文本文件排队多个提示。
将生成的图像保存到磁盘:将图像保存到您的个人电脑上!
用户界面主题:根据您的喜好自定义程序。可搜索的模型下拉列表:将您的模型组织成子文件夹,并在用户界面中进行搜索。
图像生成
生成方式:文生图、图生图、图像修复
ControlNet:用于对图像进行高级控制,例如通过设置姿势或绘制AI要填充的轮廓
16个采样器:`PLMS`, `DDIM`, `DEIS`, `Heun`, `Euler`, `Euler Ancestral`, `DPM2`,
`DPM2 Ancestral`, `LMS`, `DPM Solver`, `DPM++ 2s Ancestral`, `DPM++ 2m`, `DPM++
2m SDE`, `DPM++ SDE`, `DDPM`, `UniPC`。
稳定扩散XL和2.1:使用最新的稳定扩散XL型号生成更高质量的图像。
文本反转嵌入:用于强烈引导人工智能走向特定概念。
简单绘图工具:绘制基本图像以指导人工智能,无需外部绘图程序。
面部矫正(GFPAGAN)升级(RealESRGAN)
环回:使用输出图像作为下一个图像任务的输入图像。
否定提示:指定要删除的图像方面。
注意力/强调:提示中的“+”会增加模型的注意力
加权提示:在提示中使用特定单词的权重来更改其重要性,例如e.g. (red)2.4
(dragon)1.2
提示矩阵:快速创建提示的多种变体,例如“宇航员骑马的照片|插图|电影照明
提示集:快速创建多种提示变体,例如“宇航员在月球、地球上的照片"
单击放大/面部校正:在图像生成后放大或校正图像。
制作相似的图像:单击可生成生成图像的多个变体。
NSFW设置:UI中用于控制*NSFW内容*的设置。
JPEG/PNG/WEBP输出:多种文件格式。
与stable-diffusion-webui区别
安装完成后就可以运行了。第一次运行,会自动安装一波依赖库。
然后就会自动打开默认浏览器,进入界面。
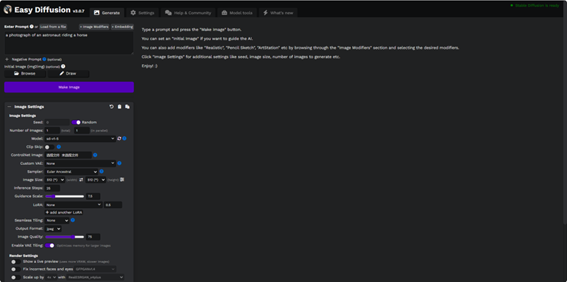
不得不说,默认界面设计还挺好看。不过目前老徐还未对其进行汉化。估计应该后面会支持。
大致看了一下,和stable-diffusion-webui对比,确实对新手相当友好。这里列举几个例子吧。
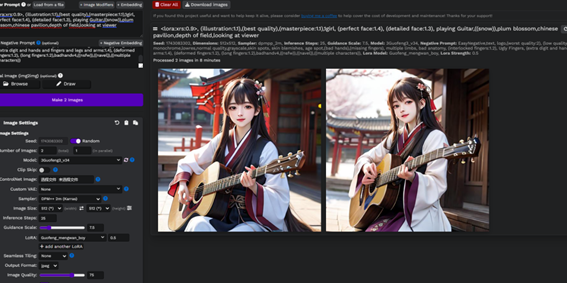
流式展示工作流
不同于webui项目,这里生成的图就像MidJourney一样滚动在右侧的区域展示。鼠标移动到图片上,还可以浮现若干针对这个图的操作工具按钮。例如脸部修复、生成类似照片、下载参数的json文件等。
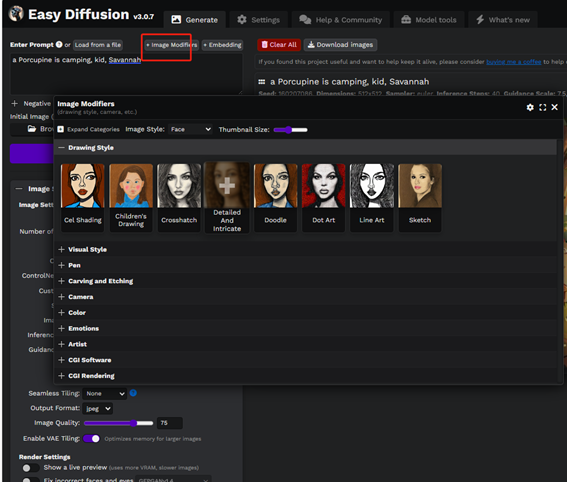
图示化的方式展示图像修饰
webui这一块完全靠自己去记录prompt,而EasyDiffusion可以以图形化的方式选择需要的图像修饰。类似风格、色调等。
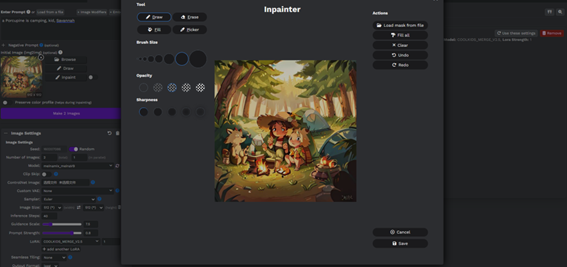
更方便的InPainting界面
这个inpaiting界面比webui更方便,具备更细致的绘制工具。可以定义笔刷的粗细、透明度以及笔刷羽化。
可以保存最后的生成参数
之前每次重启以后,之前设置的成图参数都需要重新设定一遍。不管是从图形信息里调取还是什么方法,总归是比较麻烦。这个可以保存全部参数,保证下次启动扔使用上次最后的设置。
、 
小提示(Tips):在启动过程中会检测下载一些内容,建议采用绿色上网的形式,否则可能会出现下载内容失败的情况。启动是cmd命令窗口,使用代理的时候CMD不会默认走你的本地代理,可在执行脚本中加入:set https_proxy=http://127.0.0.1:xxxx,改成你自己的代理地址来尝试。
出自:https://mp.weixin.qq.com/s/VdguSEYpXa4Ei3AhtTf-ng