有多种方法可以提高检索增强生成(RAG)的能力,其中一种方法称为查询扩展。我们这里主要介绍在Langchain中常用的3种方法
查询扩展技术涉及对用户的原始查询进行细化,以生成更全面和信息丰富的搜索。使用扩展后的查询将从向量数据库中获取更多相关文档。
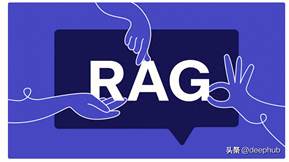
1、Step Back Prompting
Take A Step Back: Evoking Reasoning Via
Abstraction In Large Language Models
https://arxiv.org/pdf/2310.06117.pdf
这是google
deep mind开发的一种方法,它使用LLM来创建用户查询的抽象。该方法将从用户查询中退后一步,以便更好地从问题中获得概述。LLM将根据用户查询生成更通用的问题。
下面是原始查询和后退查询的示例。
{"Original_Query": "Could the members of The Police perform lawful arrests?","Step_Back_Query": "what can the members of The Police do?",
},
{"Original_Query": "Jan Sindel’s was born in what country?","Step_Back_Query": "what is Jan Sindel’s personal history?",
}
下面代码演示了如何使用Langchain进行Step Back Prompting
#---------------------Prepare VectorDB-----------------------------------# Build a sample vectorDBfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_community.vectorstores import Chromafrom langchain.embeddings import OpenAIEmbeddingsimport os
os.environ["OPENAI_API_KEY"] = "Your OpenAI KEY"# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = text_splitter.split_documents(data)# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)#-------------------Prepare Step Back Prompt Pipeline------------------------from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplatefrom langchain_core.runnables import RunnableLambdafrom langchain.chat_models import ChatOpenAI
retriever = vectordb.as_retriever()
llm = ChatOpenAI()# Few Shot Examples
examples = [
{"input": "Could the members of The Police perform lawful arrests?","output": "what can the members of The Police do?",
},
{"input": "Jan Sindel’s was born in what country?","output": "what is Jan Sindel’s personal history?",
},
]# We now transform these to example messages
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
prompt = ChatPromptTemplate.from_messages(
[
("system","""You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""",
),# Few shot examples
few_shot_prompt,# New question
("user", "{question}"),
]
)
question_gen = prompt | llm | StrOutputParser()#--------------------------QnA using Back Prompt Technique-----------------from langchain import hubdef format_docs(docs):
doc_strings = [doc.page_content for doc in docs]return "\n\n".join(doc_strings)
response_prompt = hub.pull("langchain-ai/stepback-answer")
chain = (
{# Retrieve context using the normal question"normal_context": RunnableLambda(lambda x: x["question"]) | retriever | format_docs,# Retrieve context using the step-back question"step_back_context": question_gen | retriever | format_docs,# Pass on the question"question": lambda x: x["question"],
}
| response_prompt
| llm
| StrOutputParser()
)
result = chain.invoke({"question": "What Task Decomposition that work in 2022?"})
在那个脚本中,我们的问题是
Original Query: What Task Decomposition
that work in 2022?
Step Back Prompting为
Step Back Query: What are some examples of
task decomposition in the current year?
这两个查询将用于提取相关文档,将这些文档组合在一起作为一个上下文,提供给LLM生成最终的答案。
{# Retrieve context using the normal question"normal_context": RunnableLambda(lambda x: x["question"]) | retriever | format_docs,# Retrieve context using the step-back question"step_back_context": question_gen | retriever | format_docs,# Pass on the question"question": lambda x: x["question"],
}
2、 Multi Query
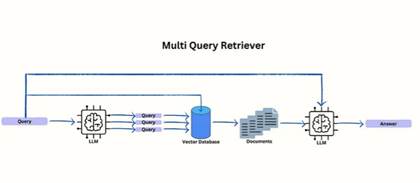
Langchain Multi Query Retriever
https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever
多步查询是一种使用LLM从第一个查询生成更多查询的技术。这种技术试图解决用户提示不是那么具体的情况。这些生成的查询将用于在矢量数据库中查找文档。
多步查询的目标是改进查询,使其与主题更加相关,从而从数据库中检索更多相关的文档。
因为Langchain
有详细的文档,我们就不贴代码了
3、Cross Encoding Re-Ranking
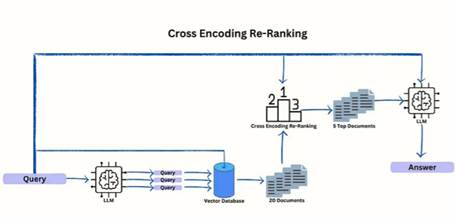
这个方法是多查询和交叉编码器重新排序的结合,当用户使用LLM生成更多的问题时,每个生成的查询都从向量数据库中提取一对文档。
这些提取的文档通过交叉编码器传递,获得与初始查询的相似度分数。然后对相关文档进行排序,并选择前5名作为LLM返回结果。
为什么需要挑选前5个文档?因为需要尽量避免从矢量数据库检索的不相关文档。这种选择确保交叉编码器专注于最相似和最有意义的文档,从而生成更准确和简洁的摘要。
#------------------------Prepare Vector Database--------------------------# Build a sample vectorDBfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_community.vectorstores import Chromafrom langchain.embeddings import OpenAIEmbeddingsfrom langchain.chat_models import ChatOpenAIimport os
os.environ["OPENAI_API_KEY"] = "Your API KEY"# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
llm = ChatOpenAI()# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = text_splitter.split_documents(data)# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)#--------------------Generate More Question----------------------------------#This function use to generate queries using LLMdef create_original_query(original_query):
query = original_query["question"]
qa_system_prompt = """
You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines."""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
("human", "{question}"),
]
)
rag_chain = (
qa_prompt
| llm
| StrOutputParser()
)
question_string = rag_chain.invoke(
{"question": query}
)
lines_list = question_string.splitlines()
queries = []
queries = [query] + lines_list
return queries#-------------------Retrieve Document and Cross Encoding--------------------from sentence_transformers import CrossEncoderfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnableLambda, RunnablePassthroughfrom langchain_core.output_parsers import StrOutputParserimport numpy as np
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')#Cross Encoding happens in heredef create_documents(queries):
retrieved_documents = []for i in queries:
results = vectordb.as_retriever().get_relevant_documents(i)
docString = format_docs(results)
retrieved_documents.extend(docString)
unique_a = []#If there is duplication documents for each query, make it uniquefor item in retrieved_documents:if item not in unique_a:
unique_a.append(item)
unique_documents = list(unique_a)
pairs = []for doc in unique_documents:
pairs.append([queries[0], doc])
#Cross Encoder Scoring
scores = cross_encoder.predict(pairs)
final_queries = []for x in range(len(scores)):
final_queries.append({"score":scores[x],"document":unique_documents[x]})
#Rerank the documents, return top 5
sorted_list = sorted(final_queries, key=lambda x: x["score"], reverse=True)
first_five_elements = sorted_list[:6]return first_five_elements#-----------------QnA Document-----------------------------------------------
qa_system_prompt = """
Assistant is a large language model trained by OpenAI. \
Use the following pieces of retrieved context to answer the question. \
If you don't know the answer, just say that you don't know. \
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
("human", "{question}"),
]
)def format(docs):
doc_strings = [doc["document"] for doc in docs]return "\n\n".join(doc_strings)
chain = (# Prepare the context using below pipeline# Generate Queries -> Cross Encoding -> Rerank ->return context
{"context": RunnableLambda(create_original_query)| RunnableLambda(create_documents) | RunnableLambda(format), "question": RunnablePassthrough()}
| qa_prompt
| llm
| StrOutputParser()
)
result = chain.invoke({"question":"What Task Decomposition that work in 2022?"})
从上面代码主要是创建了两个用于生成查询和交叉编码的自定义函数。
create_original_query用于生成查询,它将返回5个生成的问题加上原始查询。
create_documents则根据6个问题(上面的5个生成问题和1个原始查询)检索24个相关文档。这24个相关文档可能重复,所以需要进行去重。
之后我们使用
scores = cross_encoder.predict(pairs)
给出文档和原始查询之间的交叉编码分数。然后就是对文档重新排序,保留前5个文档。
总结
以上就是最常用的3种改进RAG能力扩展查询方法。当你在使用RAG时,并且没有得到正确或详细的答案,可以使用上述查询扩展方法来解决这些问题。希望所有这些技术可以用于你的下一个项目。
出自:
https://www.toutiao.com/article/7330073220861067813/?app=news_article×tamp=1706778342&use_new_style=1&req_id=20240201170542506A67B858E9CDCF3E7E&group_id=7330073220861067813&share_token=56A89F9E-2D59-4423-93CD-E78F1B9A23AA&tt_from=weixin&utm_source=weixin&utm_medium=toutiao_ios&utm_campaign=client_share&wxshare_count=1&source=m_redirect&wid=1710746725285