OCRmyPDF向扫描的PDF文件添加了OCR文本层,使它们可以被搜索或复制粘贴。
·
1、ocrmypdf # 它是一个可编程的命令行程序
2、 -l eng+fra # 它支持多种语言
3、 --rotate-pages # 它可以修正方向错误的页面
4、--deskew # 它可以纠正扭曲的PDF文件!
5、 --title "My PDF" # 它可以更改输出元数据
6、--jobs 4 # 它默认使用多个核心
7、--output-type pdfa # 它默认产生PDF/A格式文件
8、 input_scanned.pdf # 接受PDF输入(或图像)
9、output_searchable.pdf # 生成经过验证的PDF输出
查看发布说明[1]以获取最新更改的详细信息。
主要特性
•从普通PDF生成可搜索的PDF/A文件
•在图像下方准确放置OCR文本,以便于复制/粘贴
•保持原始嵌入图像的确切分辨率
•在可能的情况下,将OCR信息作为“无损”操作插入,不会干扰其他内容
•优化PDF图像,通常产生的文件比输入文件小
•如果需要,可以在执行OCR之前对图像进行纠偏和/或清洁
•验证输入和输出文件
•在所有可用的CPU核心之间分配工作
•使用Tesseract OCR引擎识别超过100种语言
•保护您的私人数据安全。
•能够正确处理包含数千页的文件。
•在数百万PDF文件上经过实战测试。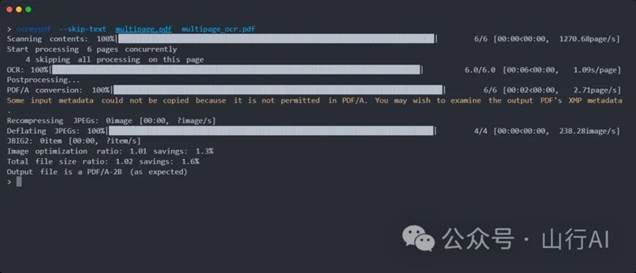
更多详情:请参阅文档[2]。
动机
我在网上搜索了一个免费的命令行工具来对PDF文件进行OCR:我找到了很多,但没有一个真正令人满意:
•要么它们生成的PDF文件中的文本放置错误(使得无法复制/粘贴)•要么它们处理不了重音和多语言字符•要么它们改变了嵌入图像的分辨率•要么它们生成了非常大的PDF文件•要么在尝试进行OCR时崩溃•要么它们没有生成有效的PDF文件•最重要的是,它们都没有生成PDF/A文件(专为长期存储而设计的格式)
...所以我决定开发自己的工具。
安装
Linux、Windows、macOS和FreeBSD都支持。也提供了x64和ARM的Docker镜像。
|
操作系统
|
安装命令
|
|
Debian, Ubuntu
|
apt install ocrmypdf
|
|
Windows子系统(Linux)
|
apt install ocrmypdf
|
|
Fedora
|
dnf install ocrmypdf
|
|
macOS (Homebrew)
|
brew install ocrmypdf
|
|
macOS (nix)
|
nix-env -i ocrmypdf
|
|
LinuxBrew
|
brew install ocrmypdf
|
|
FreeBSD
|
pkg install py-ocrmypdf
|
|
Conda
|
conda install ocrmypdf
|
|
Ubuntu Snap
|
snap install ocrmypdf
|
对于其他人,请参阅我们的文档[3]了解安装步骤。
语言
OCRmyPDF使用Tesseract进行OCR,并依赖于其语言包。对于Linux用户,您通常可以找到提供语言包的软件包:
·
# 显示所有Tesseract语言包的列表apt-cache search tesseract-ocr
# Debian/Ubuntu用户apt-get install tesseract-ocr-chi-sim # 示例:安装中文简体语言包
# Arch Linux用户pacman -S tesseract-data-eng tesseract-data-deu # 示例:安装英文和德文语言包
# brew macOS用户brew install tesseract-lang
然后,您可以传递-l LANG参数给OCRmyPDF,以提示它应该搜索哪些语言。可以请求多种语言。
OCRmyPDF支持Tesseract 4.1.1+。它会自动使用在PATH环境变量中首先找到的版本。在Windows上,如果PATH没有提供Tesseract二进制文件,我们将使用根据Windows注册表安装的最高版本号。
文档和支持
安装OCRmyPDF后,可以通过以下方式访问内置帮助,该帮助解释了命令语法和选项:
·
ocrmypdf --help
我们的文档托管在Read
the Docs[4]上。
请在我们的GitHub问题页面[5]报告问题,并遵循问题模板以获得快速响应。
要求
除了需要的Python版本(3.8+)之外,OCRmyPDF还需要外部程序安装Ghostscript和Tesseract OCR。OCRmyPDF是纯Python编写的,几乎可以在任何系统上运行:Linux、macOS、Windows和FreeBSD。
媒体报道
•使用OCRmyPDF实现无纸化[6]
•将扫描文档转换成可压缩的可搜索PDF,并进行涂改[7]
•c't 1-2014, 第59页[8]: 在德国领先的IT杂志c't中详细介绍OCRmyPDF v1.0
•heise开源,09/2014:
使用OCRmyPDF进行文本识别[9]
•heise创建可搜索的PDF文档与OCRmyPDF[10]
•优秀工具:OCRmyPDF[11]
•Linux用户使用OCRmyPDF和Scanbd自动化文本识别[12]
•Y Combinator讨论[13]
商业咨询
没有公司和用户选择支持功能开发和咨询查询,OCRmyPDF就不会成为今天的软件。我们乐于讨论所有咨询,无论是扩展现有功能集,还是将OCRmyPDF整合到更大的系统中。
许可
OCRmyPDF软件根据Mozilla公共许可证2.0(MPL-2.0)授权。此许可允许将OCRmyPDF与其他代码(包括商业和封闭源代码)集成,但要求您发布对OCRmyPDF所做的源代码级修改。
OCRmyPDF的一些组件有其他许可证,如标准SPDX许可证标识符或DEP5版权和许可信息文件所示。一般来说,非核心代码在MIT下许可,文档和测试文件在Creative Commons ShareAlike 4.0(CC-BY-SA 4.0)下许可。
免责声明
该软件是在“原样”基础上分发的,不提供任何形式的明示或暗示的保证或条件。
引用
更多信息请参考:https://github.com/ocrmypdf/OCRmyPDF?tab=readme-ov-file
References
[1] 发布说明: https://ocrmypdf.readthedocs.io/en/latest/release_notes.html
[2] 文档: https://ocrmypdf.readthedocs.io/en/latest/
[3] 文档: https://ocrmypdf.readthedocs.io/en/latest/installation.html
[4] Read the
Docs: https://ocrmypdf.readthedocs.io/en/latest/
[5] GitHub问题页面: https://github.com/ocrmypdf/OCRmyPDF/issues
[6] 使用OCRmyPDF实现无纸化: https://medium.com/@ikirichenko/going-paperless-with-ocrmypdf-e2f36143f46a
[7] 将扫描文档转换成可压缩的可搜索PDF,并进行涂改: https://medium.com/@treyharris/converting-a-scanned-document-into-a-compressed-searchable-pdf-with-redactions-63f61c34fe4c
[8] c't 1-2014, 第59页: https://heise.de/-2279695
[9] heise开源,09/2014: 使用OCRmyPDF进行文本识别: https://heise.de/-2356670
[10] heise创建可搜索的PDF文档与OCRmyPDF: https://www.heise.de/ratgeber/Durchsuchbare-PDF-Dokumente-mit-OCRmyPDF-erstellen-4607592.html
[11] 优秀工具:OCRmyPDF: https://www.linuxlinks.com/excellent-utilities-ocrmypdf-add-ocr-text-layer-scanned-pdfs/
[12] Linux用户使用OCRmyPDF和Scanbd自动化文本识别: https://www.linux-community.de/ausgaben/linuxuser/2021/06/texterkennung-mit-ocrmypdf-und-scanbd-automatisieren/
[13] Y Combinator讨论: https://news.ycombinator.com/item?id=32028752
出自:https://mp.weixin.qq.com/s/flDO1Yf7tFUNd6MXR0iuug