本文主要介绍了 Text2SQL 的基本概念,以及 RLHF 的概念和框架,最后结合 DB-GPT-Hub 项目,将 RLHF 方法应用于 Text2SQL 任务进行实践探索。
PART 1 Text2SQL 简介
本章主要对 Text2SQL 的基本定义、使用的开源数据集和评测指标做了介绍,同时也介绍了一些实践项目,供大家参考。
01
定义
Text-to-SQL(简写为Text2SQL),顾名思义就是把文本转化为 SQL 语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,简写为 NL)问题,转化为在关系型数据库中可以执行的结构化查询语言(Structured Query Language,简写为 SQL),因此 Text2SQL 也可以被简写为 NL2SQL。
举个例子比较直观:
·
输入:自然语言问题。
查询表t_user的所有信息,结果按id降序排序,只保留前10个数据
·
输出:SQL语句。
SELECT * FROM t_user ORDER BY id DESC LIMIT 10
·
实验:如图1所示,在 DB-GPT 项目中,直接使用原生对话,使用 Proxy LLM(GPT-3.5)提问上述问题,大模型可以准确给出 SQL 答案,这也是因为 LLM 本身语言理解能力强大,同时提问的自然语言问题比较 easy。
 图1 DB-GPT项目原生对话示意图
图1 DB-GPT项目原生对话示意图
02
数据集
公开的 Text2SQL 数据集比较多,这里仅介绍目前使用较多的几个数据集:
|
WikiSQL
|
2017年9月,Salesforce 提出的一个大型的 Text-to-SQL 数据集,数据来源于 Wikipedia,属于单领域,包含了 80654 个自然语言问题,77840 个 SQL 语句,SQL 语句形式比较简单,不包含排序、分组、子查询等复杂操作
|
|
Spider
|
2018年9月,耶鲁大学提出的多数据库、多表、单轮查询的 Text-to-SQL 数据集,也是业界公认难度最大的大规模跨领域评测榜单,包含了 10181 个自然语言问题,5693 个 SQL 语句,涉及 138 个不同领域的 200 多个数据库,难易程度分为:简单、中等、困难、特别困难。
|
|
CoSQL
|
2019年9月, 耶鲁大学和 Salesforce Research 提出了一种跨域数据库 CoSQL,它由 30k+ 轮次和 10k+ 带注释的 SQL 查询组成,这些查询是从 Wizard-of-Oz (WOZ) 集合中获得的,该集合包含 3k 个对话,查询跨越 13 个域的 200 个复杂数据库。
|
|
CHASE
|
2021年8月,西安交通大学和微软等提出了首个跨领域、多轮 Text-to-SQL 中文数据集,包含了 5459 个多轮问题组成的列表,17940 个<query, SQL>二元组。
|
|
BIRD-SQL
|
2023年5月,香港大学和阿里巴巴提出了一个大规模跨域数据集 BIRD,其中包含超过 12751 个独特的问题 SQL、95 个大数据库,总大小为 33.4 GB。它还涵盖区块链、曲棍球、医疗保健和教育等超过 37 个专业领域。
|
03
评测指标
以 Spider 数据集为例:主要有两个指标,分别是执行准确率(Execution Accuracy,简称EX)和逻辑形式准确率(Exact Match,简称EM)
|
EX
|
计算 SQL 执行结果正确的数量在数据集中的比例,结果存在高估的可能。
|
|
EM
|
计算模型生成的 SQL 和标注 SQL 的匹配程度,结果存在低估的可能。
|
在 DB-GPT 社区的子项目 Awesome-Text2SQL 项目中,列举了常见的数据以及对应的指标榜单,如图 2 所示,比如 Spider 数据集上,目前 EX 得分第一是 MiniSeek 组织提交的 91.2,EM 得分第一也是 MiniSeek 提交的 81.5,因为运用了 GPT-4 以及一些其他的 trick,所以得分最高。
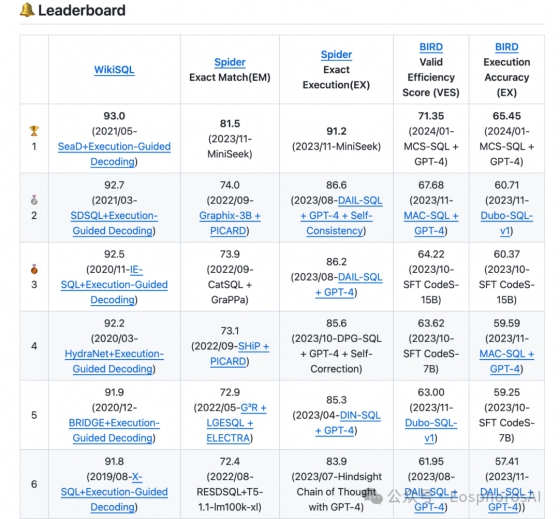
图2 Awesome-Text2SQL项目数据集得分榜单
04
实验方法
Text2SQL 研究主要有基于模版和匹配的方法、基于 Seq2Seq 框架的方法和基于模型预训练的方法,随着 LLM 的崛起,如今利用 LLM 微调完成 Text2SQL 任务也越来越常见,比如在 DB-GPT-Hub 项目中,就实现了利用各种开源模型在 Spider 数据集上进行 lora 和 qlora 方法微调,亲测好用!(方法详情可以参考代码仓库)
PART 2 RLHF 简介
本章主要介绍了 RLHF 的基本定义,以及介绍了强化学习的基础概念和 RLHF 框架。
01
定义
RLHF:Reinforcement Learning from Human Feedback,通过强化学习方式方式根据人类反馈优化语言模型,使得在一般文本数据语料库的语言模型能够和复杂人类价值观对齐。
02
强化学习基础概念
RL:指的是 Reinforcement learning。
·
强化学习是一种机器学习方法,旨在通过智能体(agent)与环境(environment)的交互学习如何在动态环境中做出决策(action)以最大化累积回报(reward)。在强化学习中,智能体通过观察环境的状态、采取行动和接收奖励来学习与环境的交互。智能体的目标是通过学习最优的策略(policy),在不断尝试和调整中,使得长期累积的奖励最大化。
·
强化学习最早在游戏中应用比较多。
·
为了更好理解强化学习,我们可以先了解一下比较常见的有监督学习(Supervised Learning, SL)。对于有监督学习而言,模型完整的训练 pipline 通常可以分成如图 3 所示:
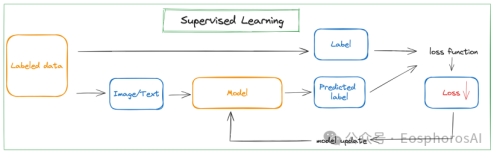
图3 有监督学习示意图
· 输入标注好的数据 labeled data(有标签 ground truth+ 原始数据)
第一步,从标签数据中获取原始数据
第二步,把原始数据拿给模型训练(比如卷积神经网络 CNN)
第三步,模型根据当前数据输出预测值 predict
第四步,通过损失函数 loss function 计算预测值和真实值之间的 loss
第五步,loss 更新给模型然后重复上述 1-5 步骤,训练模型。【优化目标:把loss变小】
· 输出训练好的模型
对于强化学习而言,模型训练的 pipline 也是类似的,如图 4 所示。
· 输入初始化的环境 environment
第一步,从环境获取当前状态
state第二步,把当前 state 拿给智能体 agent
第三步,agent 根据环境的状态输出采取的动作 action
第四步,action 和环境进行交互,通过奖励函数 reward function 计算当前奖励
第五步,奖励和状态更新给智能体 agent
然后重复上述 1-5 步骤,训练 agent。【优化目标:把 reward 变大】
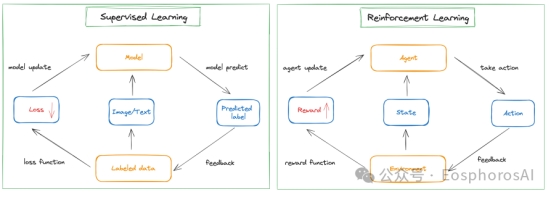
图4 有监督学习和强化学习对比示意图
由上面讲述可知,强化学习的基本组成主要由以下部分:
·
environment
·
agent
·
state
·
reward
·
action
·
policy: 策略。定义了 agent 如何根据当前的 state 来做出 action。策略主要可以分为 on-policy 和 off-policy。
·
|
On-policy
|
学习到的 agent 以及和环境进行互动的 agent 是同一个 agent ,比如 PPO 算法(eg:你在打游戏,你在实战中变强。)
|
|
Off-policy
|
学习到的 agent 以及和环境进行互动的 agent 是不同的 agent,比如 DQN 算法(eg: 你在看直播,你在观摩中变强。)
|
03
RLHF 框架
RLHF 方法最早是在 2017 年论文(Deep reinforcement learning from human preferences)提出。
·
在 2020 年的论文(Learning to summarize from human feedback)中 RM 训练使用了交叉熵损失。
·
在 2023 年 3 月 OpenAI 发表的论文(Training language models to follow instructions with human feedback)中进一步提供了 RLHF 实现的标准范式(论文中训练的模型为 InstructGPT,ChatGPT 是改进后的 InstructGPT,比如 InstructGPT 是基于 GPT-3 训练,而 ChatGPT 是基于 GPT-3.5 训练),如图 5 所示。
·
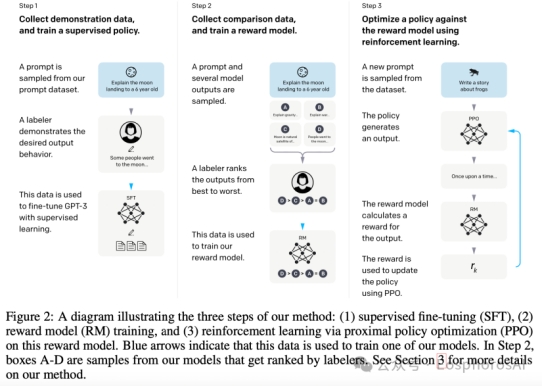 图 5 InstructGPT 论文中的 RLHF 实现范式
图 5 InstructGPT 论文中的 RLHF 实现范式
RLHF 主要流程有3步:
第一阶段:SFT
·
Supervised Fine-tuning 有监督微调,简称为 SFT。这是 InstructGPT(ChatGPT 等)训练过程中的一个重要步骤,主要采用有监督的方式对预训练的 LLM 进行微调,这个方法比较依赖于标注的数据,SFT 数据集标注质量越高(质量不等同于数据),模型的效果越好。
·
之前听一个大学教授的讲座,有个观点很有意思:Open AI 做大模型为什么比谷歌强,因为包括 transformer 在内的一些创新模型大多是谷歌研究的,那为什么 Open AI 在大模型领域为什么比谷歌强?答:因为 Open AI 在数据清洗,数据质量把控这方面做的很好。——所以数据是相当重要的!
第二阶段:RM
·
Reward Model 奖励模型训练,是 InstructGPT 训练过程的第二阶段,它的目标是训练一个模型来适应人类的偏好(这里主要是标注人员的偏好)。在 RM 训练阶段,输入 prompt,会使 LLM 生成多个响应 response,然后标注人员对这些响应进行排名,根据这些排名训练一个奖励模型。
·
第三阶段:RL
·
Reinforcement Learning,是 InstructGPT 训练中的最后步骤,主要是通过 PPO 策略(proximal policy optimization 近端策略优化)迭代,它通过引入奖励信号来调整模型的行为,使模型生成的内容更符合人类的偏好。输入一个标注数据,模型经过 PPO 输出一个 response ,然后 RM 模型对 response 打分,最后根据打分 score 更新 PPO 策略。
·
·
PART 3 RLHF+Text2SQL 实践探索
本章节主要结合 DB-GPT-Hub 项目代码以及一些 RLHF 代码对 Text2SQL 进行了实践探索。
01
SFT
SFT 模块的实现主要参考 DB-GPT-Hub,比如在 Spider 数据集上进行实现。
数据预处理
sh dbgpt_hub/scripts/gen_train_eval_data.sh
经过数据预处理后,可以得到 example_text2sql_train.json 和 example_text2sql_dev.json
数据格式
数据格式如下所示:
· db_id-instruction-input-output-history
·
{
"db_id": "department_management",
"instruction": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n\n",
"input": "###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:",
"output": "SELECT count(*) FROM head WHERE age > 56",
"history": []
}
·
最终经过代码后会形成为这样的格式:prompt-output
·
·
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","output": "SELECT count(*) FROM head WHERE age > 56"}
训练
·
sh dbgpt_hub/scripts/train_sft.sh
训练的基础大模型为 CodeLlama-13b-instruct,训练的参数如下所示:
·
CUDA_VISIBLE_DEVICES=0 python dbgpt_hub/train/sft_train.py \
--model_name_or_path /home/model/CodeLlama-13B-Instruct \
--do_train \
--dataset example_text2sql_train \
--max_source_length 2048 \
--max_target_length 512 \
--template llama2 \
--finetuning_type lora \
--lora_rank 64 \
--lora_alpha 32 \
--lora_target q_proj,v_proj \
--output_dir dbgpt_hub/output/adapter/CodeLlama-13B-Instruct-lora \
--overwrite_cache \
--overwrite_output_dir \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--lr_scheduler_type cosine_with_restarts \
--logging_steps 500 \
--save_steps 2000 \
--learning_rate 2e-4 \
--num_train_epochs 8 \
--plot_loss \
--bf16
预测
·
sh dbgpt_hub/scripts/predict_sft.sh
预测完成后,会生成一个 predict.sql 文件,文件中存放了 dev 集合中 1034 个 sql.
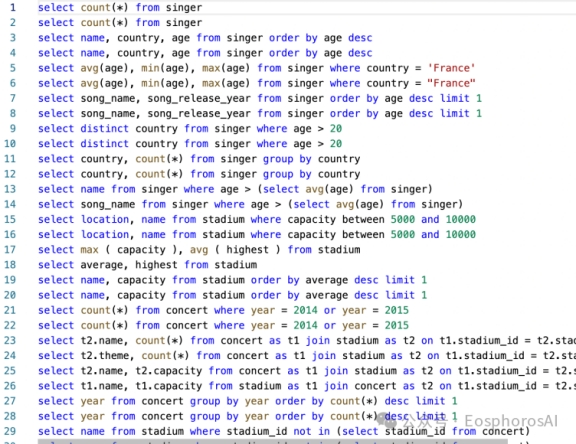
评估
测试的库为 ts 库
·
python dbgpt_hub/eval/evaluation.py --plug_value --input Your_model_pred_file
评估过程如下所示:会对每一个 sql 进行对比,对错误的 sql 进行打印输出展示。
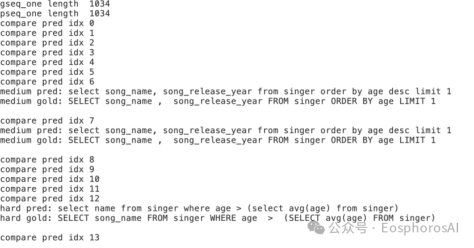
最终对1034条sql验证完成后,可以得到EX、EM精度得分。
· EX-0.746
02
RM
RM 模型训练的模型以 SFT 阶段的模型为基础,参考微软代码进行训练(Hub 项目近期也会增加RLHF功能,敬请期待),自行构建了少量 Text2SQL 的 RM 训练数据集用于测试训练。
数据格式
数据格式如下所示:
· prompy-chosen-rejected
· chosen就是在SFT阶段的ground truth
· rejected就是模型的错误输出结果
·
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","chosen": "SELECT count(*) FROM head WHERE age > 56","rejected":"SELECT COUNT(head_name) FROM head WHERE age > 56;"}
训练
比如训练 10 个 epoch 的训练结果如下:
·
deepspeed --num_gpus=$n_gpu \
main.py \
--data_path $data_path \
--data_split 2,4,4 \
--model_name_or_path $model_name_or_path \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--max_seq_len 1024 \
--learning_rate 9.65e-6 \
--weight_decay 0.1 \
--num_padding_at_beginning 0 \
--num_train_epochs 10 \
--gradient_accumulation_steps 1 \
--lr_scheduler_type cosine \
--num_warmup_steps 0 \
--seed 1234 \
--gradient_checkpointing \
--zero_stage $ZERO_STAGE \
--deepspeed \
--offload \
--lora_dim 128 \
--lora_module_name "layers." \
--output_dir $OUTPUT \
2>&1 | tee $OUTPUT/log.txt
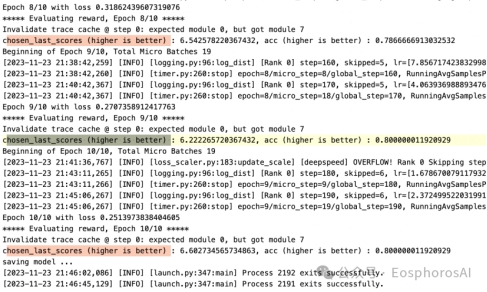
结果
训练完成后,会在制定目前生成训练好的模型,比如有以下文件:
·
config.json
·
·
log.txt
·
·
pytorch_model.bin
·
·
tokenizer.model
·

03
RM
数据格式
RL 阶段和 SFT 阶段的数据格式保持一致,以 Text2SQL 任务举例子,RL 数据可以构造为(prompt,output}的二元组,如下所示:
· prompt-otput
·
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","output": "SELECT count(*) FROM head WHERE age > 56"}
训练
训练参数
· SFT 模型即为上面训练的 SFT 模型
·
RM 模型即为上面训练的 RM 模型
·
训练 10epoch
·
·
deepspeed --master_port 12346 main.py \
--data_path $data_path \
--data_split 2,4,4 \
--actor_model_name_or_path $ACTOR_MODEL_PATH \
--critic_model_name_or_path $CRITIC_MODEL_PATH \
--num_padding_at_beginning 1 \
--per_device_generation_batch_size 8 \
--per_device_training_batch_size 8 \
--generation_batches 1 \
--ppo_epochs 1 \
--max_answer_seq_len 256 \
--max_prompt_seq_len 1024 \
--actor_learning_rate ${Actor_Lr} \
--critic_learning_rate ${Critic_Lr} \
--actor_weight_decay 0.1 \
--critic_weight_decay 0.1 \
--num_train_epochs 10 \
--lr_scheduler_type cosine \
--gradient_accumulation_steps 1 \
--actor_gradient_checkpointing \
--critic_gradient_checkpointing \
--offload_reference_model \
--disable_actor_dropout \
--num_warmup_steps 100 \
--deepspeed --seed 1234 \
--actor_zero_stage $ACTOR_ZERO_STAGE \
--critic_zero_stage $CRITIC_ZERO_STAGE \
--enable_hybrid_engine \
--actor_lora_dim 64 \
--critic_lora_dim 64 \
--critic_lora_module_name "layers." \
--actor_lora_module_name "layers." \
--output_dir $OUTPUT \
2>&1 | tee $OUTPUT/log.txt
训练结束
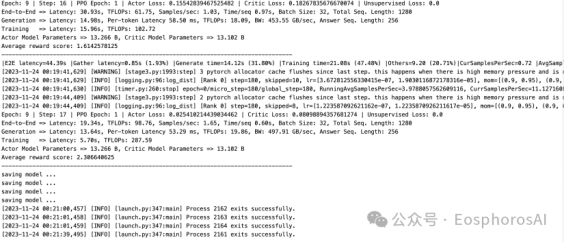
结果
训练结束会得到两个模型,actor 模型即为需要的最终评测模型。

验证
·
验证得到的模型
·
EX-0.752
·
EM-0.717
·
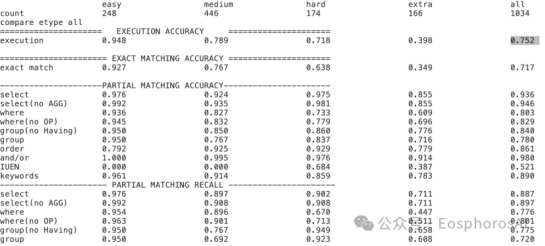
可以发现的是,RLHF 相比 SFT 方法,精度有轻微提升,主要是数据质量的问题,后续还可以进一步探索。
本文来自于征文大赛,作者 junewgl,可以点击「阅读原文」跳转查看原文。
附录
01 DB-GPT 框架
https://github.com/eosphoros-ai/DB-GPT
02Text2SQL 微调
https://github.com/eosphoros-ai/DB-GPT-Hub
03 DB-GPT 前端可视化项目
https://github.com/eosphoros-ai/DB-GPT-Web
04 DB-GPT 插件仓库https://github.com/eosphoros-ai/DB-GPT-Plugins
05 Text2SQL学习资料和前沿跟踪https://github.com/eosphoros-ai/Awesome-Text2SQL
06 中文官方文档https://www.yuque.com/eosphoros/dbgpt-docs/bex30nsv60ru0fmx
07 英文官方文档http://docs.dbgpt.site/docs/overview
出自:https://mp.weixin.qq.com/s/_v_Hi7ksynZfGYDO2AgM_w