通常情况下,我们使⽤更好的基础模型、更⼤的数据集⼤⼩以及更⾼质量的数据来提升⼤型语⾔模型(LLM)微调性能。但在这篇NEFTune: Noisy Embeddings Improve Instruction Finetuning中,研究⼈员尝试了⼀种不同且更简单的⽅法:在训练过程中向嵌入向量添加均匀随机噪声,可以显著改善语⾔模型微调的效果!

一.引用
在LLaMA2-7B这样的原始LLM中使⽤带有噪⾳嵌入进⾏微调时,其在AlpacaEval上的性能从29.8%提⾼到64.7%(图1)。NEFTune导致在对话任务的性能上出现了显著的⻜跃,同时保持了对事实性问题回答基线的性能。
这种技术似乎对LLM微调来说是⼀个零代价的策略!
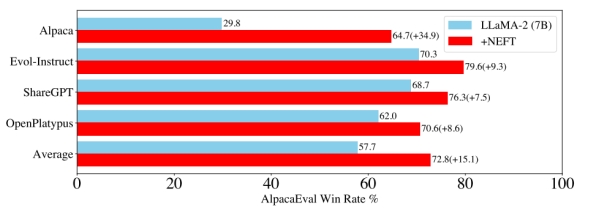
图1:LLaMA2-7B模型在数据集微调时,使⽤和不使⽤NEFTune的AlpacaEval胜率百分比。
二. NEFTUNE:
Noisy Embeddings Improve Instruction Finetuning
1. 核⼼⽅法:
输入经过Embedding层后,再加入⼀个均匀分布的噪声,噪声的采样范围为 $$ [-\frac{L}{\sqrt{d α}} ,\frac{L}{\sqrt{d α}}] $$ 其中,α为可调节参数,L为输入⻓度,d为Embedding层的维度,具体如下: $$热点文档2.mdX_{emb}^{‘}=X_{emb}+Uniform(-\frac{L}{\sqrt{d α}} ,\frac{L}{\sqrt{d α}}) $$ 算法1详细描述了此⽅法。

核⼼⽅法的代码如下:
|
from torch.nn import functional as F
def NEFTune(model, noise_alpha=5)
def noised_embed(orig_embed, noise_alpha):
def new_func(x):
# during training, we add noise to the embedding
# during generation, we don't add noise to the embedding if model.training:
embed_init = orig_embed(x)
dims = torch.tensor(embed_init.size(1) * embed_init.size(2)) mag_norm = noise_alpha/torch.sqrt(dims)
return embed_init + torch.zeros_like(embed_init).uniform_(- mag_norm, mag_norm)
else:
return orig_embed(x)
return new_func
##### NOTE: this is for a LLaMA model #####
##### For a different model, you need to change the attribute path to the embedding #####
model.base_model.model.model.embed_tokens.forward =
noised_embed(model.base_model.model.model.embed_tokens, noise_alpha) return model
|
2. 对NEFTune的评估结果:
改善了文本质量
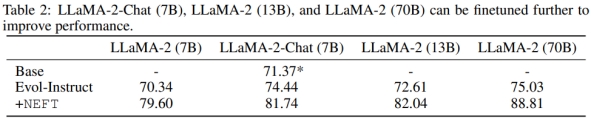
从表1中可以看出,在7B规模下,所有数据集都有所增加,平均增幅为15.1%。这表明,通过AlpacaEval的评估,使⽤NEFT进⾏训练显著提⾼了对话能⼒和回答质量。此外,从图2中可以看出,我们还可以看到在LLaMA-1和OPT等旧模型上也有改进。有趣的是,根据ChatGPT的评估,我们在ShareGPT上的改进程度较其他数据集低⼀些。然⽽,这在GPT-4的评估中并没有反映出来。从表2中可以看出,在70B参数的Evol-Instruct模型中添加NEFTune后,胜率从75.03%上升到88.81%(增加13.78%)。

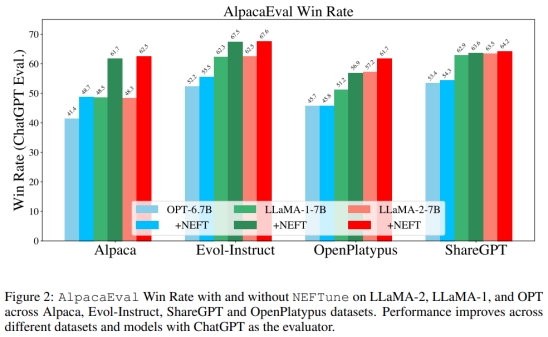
可以改善对话模型
从表2中可以看出,进⼀步对LLaMA-2-Chat(7B)模型在Evol-Instruct上进⾏指令微调可以提⾼LLaMA-2-Chat的性能3%。这个模型已经经过了⼴泛的调优,使⽤了多轮的RLHF。然⽽,通过NEFTune,我们看到了额外的10%的性能提升,尽管我们注意到这个检查点模型的⼀些能⼒可能会受到影响,比如避免输出有害⾏为的能⼒。
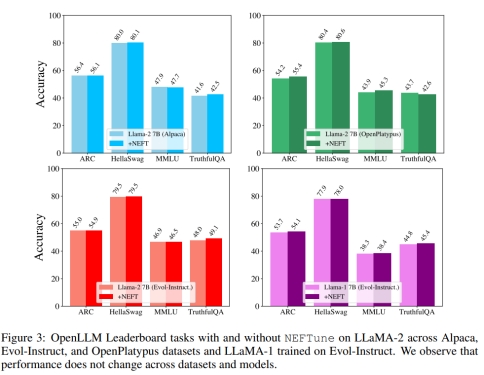
保留了模型的能⼒
⼀个潜在的担忧是,NEFTune只是以牺牲其他经典技能为代价来提⾼对话能⼒。作者使⽤MMLU、ARC、HellaSwag和TruthfulQA在OpenLLM Leaderboard上进⾏评估。图3显⽰得分保持稳定,NEFTune保留了模型的能⼒。
适⽤于QLORA
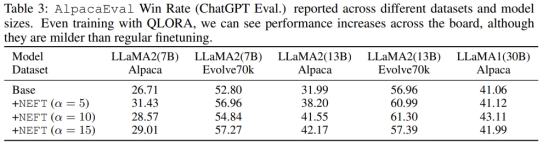
本文亦展⽰了NEFTune通过使⽤Quantized Low Rank Adapters (QLORA) 在受限资源环境中提⾼性能的能⼒。表3显⽰,当使⽤QLORA进⾏训练时,AlpacaEval的性能在所有研究的模型规模和数据集上都有提升。
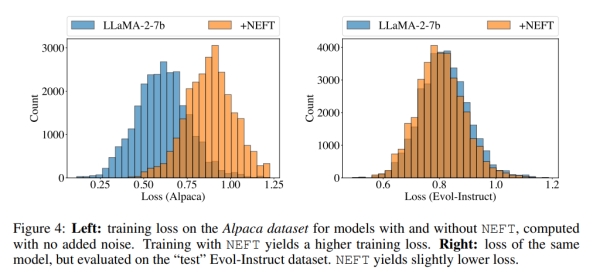
降低过拟合程度
将重点放在LLaMA-2-7B模型上,这些模型在Alpaca数据集上进⾏了使⽤和不使⽤NEFTune的训练。检查了这两个模型在Alpaca数据集上的训练损失(都没有添加噪声),以及在Evol-Instruct数据集上的“测试”损失。如图4所⽰,与没有使⽤NEFTune的基础模型相比,NEFTune模型的训练损失显著更⾼,但测试损失略低。这表明使⽤NEFTune时过拟合程度较低,泛化能⼒更好。
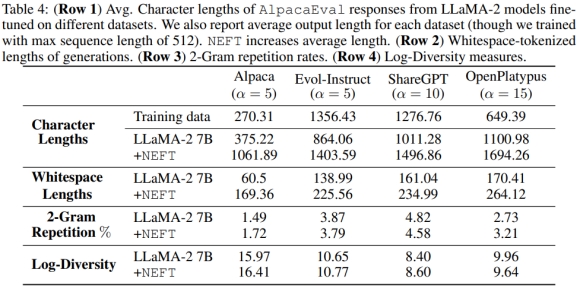
⻓度与标记多样性的比较
在表4和表6中,我们可以看到NEFT模型⽣成的输出比其对应的模型更⻓。然⽽,我们还可以看到,使⽤NEFT和不使⽤NEFT训练的模型的2-gram重复率以及整体的标记对数多样性⼏乎相同,这提供了证据表明更⻓的回答并没有以重复为代价,⽽是提供了额外的细节。
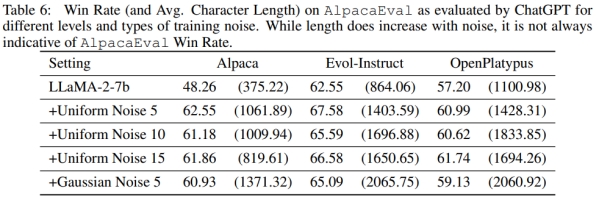
研究⻓度与性能之间的关联性
迫使标准模型⽣成与NEFT⼀样⻓的答案可以导致相对于标准微调的微⼩改进,⻅表5。对NEFT算法中使⽤均匀噪声和⾼斯噪声进⾏了消融实验,发现⾼斯噪声会导致更⻓的输出,但并不会带来性能上的改进,⻅表6。虽然更⻓的⽣成语句得分更⾼,但我们可以看到在⽣成过程中没有任何策略能够接近NEFTune模型的性能。

⼈⼯研究
作者还进⾏了⼀项⼩规模的⼈⼯研究。对于来⾃AlpacaEval的140个指令的⼦样本,以随机顺序向注释者展⽰了⼀个由使⽤NEFT在Alpaca数据上微调的LLaMA-2模型⽣成的回答,以及⼀个由不使⽤NEFT训练的模型⽣成的回答。⼈⼯注释者在88个实例中更喜欢NEFT,22个实例则是平局。这相当于使⽤AlpacaEval公式(88/(140-22))得出的74.6%的胜率得分。接下来,进⾏了⼀次修改版的AlpacaEval测试,这次测试呈现了标准微调模型和相同模型的NEFT版本的回答对,胜率得分⾼达92.80%。
三. 结论和局限性
NEFTune⽅法可以缓解模型在指令微调阶段的过拟合现象,可以更好的利⽤预训练阶段的知识内容。NEFTune的成功指出了算法和正则化对LLM训练的重要性! 但此研究还存在⼀些局限性,比如:受到单个评判者(GPT-4)的偏⻅影响,计算资源有限导致未在多个数据集上验证NEFTune在更⼤的70B变体上的成功等。
参考链接:
论文链接:https://arxiv.org/pdf/2310.05914v2.pdf
代码链接: https://github.com/neelsjain/NEFTune
-End-
出自:https://mp.weixin.qq.com/s/C2Fcz-MTLWWBsf0qgKDU6A