
在上一篇中我们了解了SD的工作原理,这篇我们来实践一下,通过提示词(prompt)的输入,让SD生成我们满意的图片。在生成图片前,我们先了解下提示词的基础原则,有了这些知识能迅速帮助各位同学构建出自己的提示词。
!基本原则!
首先,我来介绍下写提示词的基本原则。
原则一:prompt 不是越长越好
很多同学刚学习 prompt 时,会觉得 prompt 越长越好,但实际上这是不对的。精准表达你的意图才是最重要的,而不是堆积非常多无用的词语。另外,长度最好保持在 75 个单词(或约 60 个字)以内。
原则二:越重要的词放在靠前的位置
很多人在写 prompt 时,会较常忽略这一点。比如说,如果你想要生成一张狗的图片,那么你应该将「Dog」这个词放在靠前的位置,而不是放在靠后的位置。
原则三:善用符号
·
使用逗号分隔:虽然 SDXL 在语意理解上已经有了很大的提升,但是在使用 prompt 时,还是建议使用逗号来分隔不同的意图。
·
·
使用 () 调整权重:你可以输入 (keyword:weight) 方式来控制关键词的权重,比如 (hight building: 1.2 ) 就意味着 hight building 的权重变高,如果填写的权重数小于 1,则意味着这个词的权重会变低,生成的图与这个词更不相关。
·
!基本模板!
你了解完基本原则后,我们介绍下写 prompt 的模板,一般 prompt 会包含以下内容:

1. Subject:因为主体是最重要的,所以主体一般会放在首位。
2. Environment:环境包含:
o 主体周围的环境,比如说「在一片森林里」、「在一片草地上」等等。
o 光照,比如「体积光」、「自然光」等等。
o 天气,比如「晴天」、「下雪」等等。
3. Medium:媒介可以是图片的拍摄媒介,如「全景」「肖像画」,亦或者承载的媒介,比如「油画」。
4. Style:可以用 4W 记忆:
o When:什么年代的风格?
o Who:你想要谁的风格?(人或组织)
o What:什么艺术类型的风格?或者艺术运动的风格?
o Where:什么国家的风格?
以上这套模板是prompt的最基础结构。

!学习 prompt 的方法!
其实了解完 prompt 的基本原则和模板后,你就已经可以写 prompt 并生成图片了。但是,我认为绝大数人(包括我)其实很难一次就生成你脑海中满意的图片。原因是:
· 绝大多数人缺乏对美的认知:这是一个很大的问题,因为你不知道你想要的图片是什么样的,所以你也不知道该怎么写 prompt。
· 绝大多数人缺乏美术相关知识:即使你知道什么是美,但是你不知道该怎么表达出来,比如如果你根本不知道世界上有一名画家叫「莫奈」,那你不可能会在 prompt 里写出「莫奈风格」这样的词语。
·
那有没有解决方案呢?
我觉得最佳的方法是「先模仿后超越」。咋们先去抄,也不对,应该说借鉴,看看别人咋写,然后根据自己的需求进行修改,并且通过控制变量的方式去多尝试,比如一次只改一个词,这样你就能知道每个词对生成图片的影响。
那我就推荐几个不错的学习网站:
·
Civitai(https://civitai.com/images):大名鼎鼎的 C 站,这个应该是目前全球最大的 AI 图片社区,这个网站可以下载模型,看别人生成的图片作品,反正我在那学到了非常多东西。
·
PromptHero(https://learningprompt.wiki/):这也是一个很不错的 AI 图片社区,但感觉比 Civitai 小一些。
·
Learning Prompt(https://learningprompt.wiki/):里面场景案例对于学习 Stable Diffusion 依然有参考意义。
·
哩布哩布(https://www.liblib.art/): 镜像C站,国内可以浏览,下载大模型非常快。
·
!你要知道的一些知识!
当你把上面的这些原则模板方法理解了之后,那么我们继续往下看你必须知道的一些知识:
· 正向提示词:我要在图像里呈现什么;
· 反向提示词:我不要在图像里呈现什么;
· 提示词与提示词之间要用英文逗号分隔;
· 提示词之间是可以换行,但换行时也是要记得在结尾加上逗号来进行区分;
· 每个提示词自身权重默认值都是1,越靠前的提示词权重越高;
· 控制在75个单词以内;
· 小括号()代表:增加权重,1层1.1倍;
· 中括号[]代表:减少权重,1层0.9倍;
· 大括号{}代表:增加权重,1层1.05倍;
· [提示词:0-1]:整体画面采样到图像生成进程百分比的某个阶段开始计算提示词的采样;
· [提示词::0-1]:提示词的采样从一开始就计算直到数值的百分比结束;
· [提示词1:提示词2:0-1数值]:数值的百分比前计算提示词1采样,数值的百分比后计算提示词2采样。
· 基础词汇:通用的词语,主要对画质的提示,通常无论哪种图片都可以加上,也称起手式常用的有(最好的质量,超细节,杰作,精细的细节,高分辨率,8k壁纸);
· 主体词:对图像的主题进行描述的词语,比如环境描述,光线描述,构图比例,图像包含的人物,物体,场景等等。
· 细节词:对于主体更加细节的描述,比如人物年龄(小孩、青年、中年、老年)、发型(长发、短发等)、发色(红色、绿色等)、情绪表情(微笑、哭泣等)、眼睛(大小、瞳孔颜色等)、服装(紧身衣、连衣裙、西装等)、人物四肢动作(手臂动作,双腿动作等)。
·
·
上面也提到了,在你会使用prompt生成图片之后通过调整prompt来控制图片,不过呢,有时候用prompt生成图片的效果可能并不是你想要的,比如你想要生成的图片是动漫风格的,但生成的图片却是真人风格的,这时你就需要通过某些手段让 AI 生成特定风格的图片。要想调整图片风格,有多种方法:
§ 方法一:通过加载不同的 Checkpoint 模型来影响生成图片的效果,这个是最简单的做法,网址在上一节可以看到。
§ 方法二:通过 LoRA 来影响生成图片的效果。这个方法稍微复杂一些,但是相较于方法一,可用的模型会更多,而且文件也小非常多。后续我会给大家介绍一下 LoRA 的使用方法。
§
SDUI文生图主界面
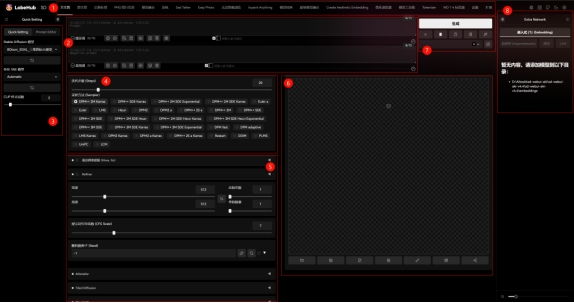
主要分为8大区域:
1.
主要功能导航栏;
2.
提示词编写区域;
3.
图像模型、VAE和CLIP设置区域;
4.
采样器选择和Septs设置;
5.
插件及画面分辨率设置区域;
6.
生成图像浏览区;
7.
生成图像主要按钮及提示词模板设置;
8.
LoRA模型、嵌入式模型、超网络模型加载区域。
!总结!
那么恭喜你,也很感谢你,看完了这些枯燥乏味的文字。其实学习完以上教程可以算入门SD了,能生成非常漂亮的图片。下一章我们按照SDUI主界面着重讲一下最重要的采样器及调配参数。
出自:https://mp.weixin.qq.com/s/XrzooW0d-dXnt7ot-2dYhA