大家新年好,今天是迎财神的日子,祝愿大家新年发发发。这里我送给大家一个小福利:介绍下如何使用so-vits-svc来变声。
so-vits-svc这个项目最初是用来进行歌声转换的,github项目地址:
https://github.com/svc-develop-team/so-vits-svc/tree/4.1-Stable

关注AI应用场景的人都知道,去年年初,用AI孙燕姿唱其他明星的歌曲非常火,就是通过这种技术来实现的。为什么要选择孙燕姿而不是其他歌星来唱呢?主要是因为孙燕姿的音色独特,吐词清晰,网络上存在她的大量歌曲,非常便于训练。
其实歌声转换不仅仅适用于歌声,普通讲话也可以,只是歌唱的音调基本能覆盖到低、中、高全域声音类型,而正常说话可能无法做到全域覆盖,但是如果在录制声音的时候能够做到覆盖多种音调类型,也可以实现声音转换。
但是无论转换哪种声音,都需要至少采集30分钟-1小时的语音干声,这对于普通讲话很好采集,只需要到一个安静的场所,比如录音棚,录制一段语音即可。如果是歌声的话,还需要使用特别软件进行人声分离,将伴奏声和人物干声分离,然后再对干声训练得到ta的声音模型。通常采集到的干声越多,质量越高,效果也就越好。所以这里就没有上限了,至于多少合适,完全取决于自己的需要和要求。
声音转换,通常需要经过以下几步:
·
1 声音处理
·
·
2 主模型训练
·
·
3 推理
·
我们一步步来介绍。
如果是小白用户,并且想训练歌曲中的人声,可以先从网上下载Slicer-gui这个软件,进行人声分离:
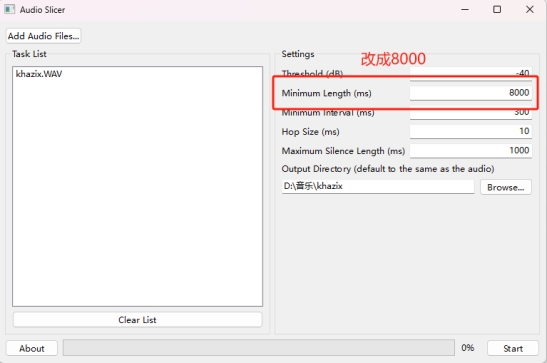
上传音频之后点击Start按钮,十几秒就切割完了。我们去我们选择的输出路径就能看到我们的文件。这里要求切割后的音频长度在5-15秒左右,不能太长或太短。
当然Slicer也有Python脚本工具,把多个音频放在指定的文件夹内,一个命令就可以自动完成切割。
注意:一定要多花时间精力处理数据,它基本决定后续效果。
然后就是训练声音主模型。
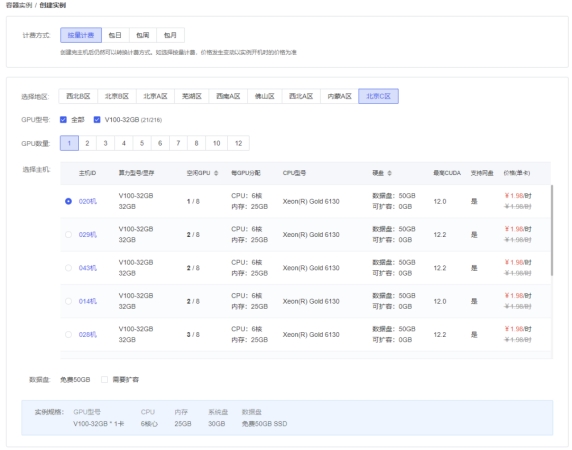
我们可以在这个网站上
https://www.autodl.com
租用一台服务器实例,24G的GPU即可,每小时1元钱左右:
同时选择最新的镜像:
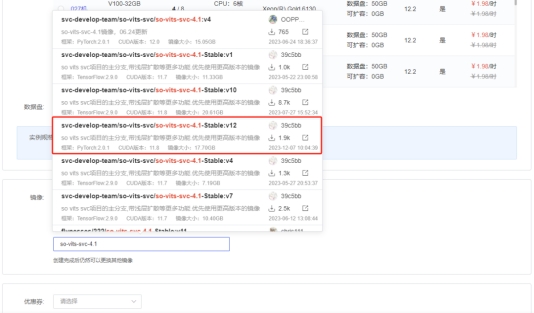
在社区镜像中,搜so-vits-svc-4.1。在弹出来的搜索联想框中,选用v12版本,在此文发出后,镜像依然可能会持续升级,如果在你使用的时候,出现了比v12还要高的版本,请使用你能看到的最高的版本。
完事后,点立即创建。
你就会看到你的云机器在创建过程了,第一次创建拉取云上的镜像时间会久一点点,多等等就好。
当机器状态变成运行中的时候,点JupyterLab,进入操作系统。

启动后,点JupyterLab,进入系统:
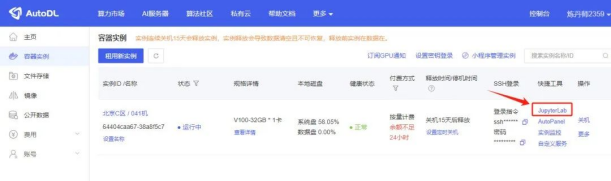
第一次打开后,自动打开这几个tab页面,作为入门,我们选择quickly这个页面,它去掉了一些冗余、暂时不需要的脚本内容,使用默认配置的脚本命令,适合快速使用。

首先在dataset_raw文件夹下随意创建一个文件夹,名字是声音的名称,将我们处理后的音频(wav格式),上传到dataset_raw文件夹下声音名称对应的文件夹下:
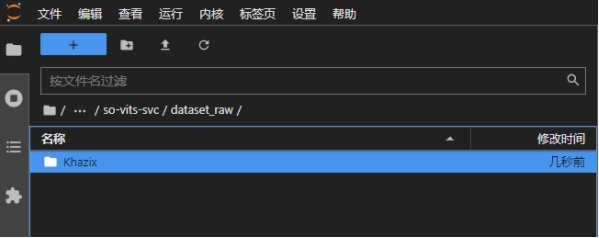
接下来就按照notebook中的注释说明,一步步操作到底即可。主要过程就是训练,其中命令是:
·
python train.py -c configs/config.json -m 44k
这个命令既可以在notebook中执行,也可以在控制台中执行。通常训练过程持续几小时到几十个小时不等,在notebook中执行可能会因为长时间执行导致页面不动等问题,所以建议在控制台执行。如果在控制台执行,可以这样操作:

然后在弹出的窗口中执行上述命令。
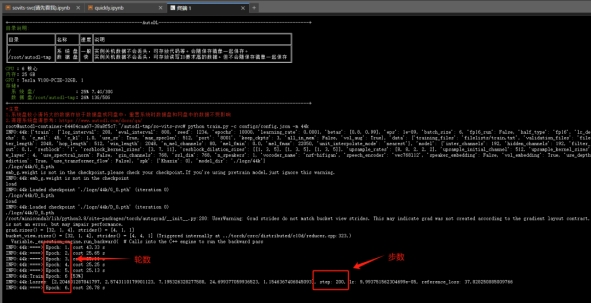
正式训练后,就长这个样子,左边的那些Epoch是轮数,没啥大用,主要看右边的步数,1w步左右可以去听,2w步差不多就可以用了,最多不要超过6w步:
最后是模型推理,也就是进行声音转换。两种方式:webui页面和脚本命令,如果是webui,执行:
·
python app.py
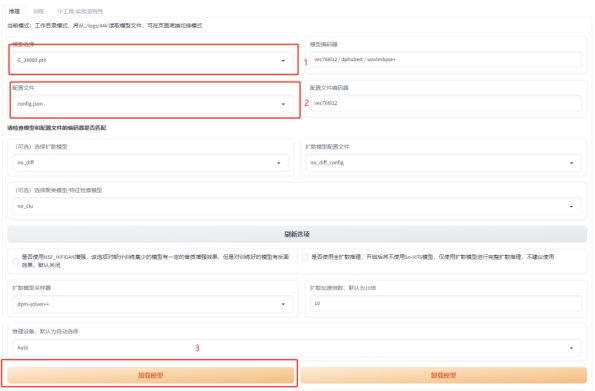
打开http://127.0.0.1:6006,下图中的3个红框挨个点,模型那块选择具体是哪个模型。配置文件默认是 no_config,不要忘了点开换成config.json。最后再点一下加载模型。
成功加载模型后,会显示模型相关的信息:
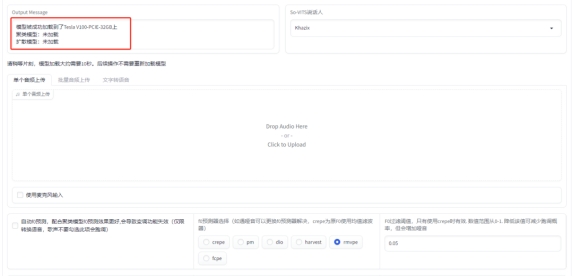
扩散模型和聚类模型是两个扩展模型,聚类模型你炼说话模型时有用,会增加咬字,唱歌模型没啥大用,不用管,浅扩散模型可以修复部分哑音,但是会出现一些音色泄露问题,你数据集弄好。也不用管。
推理的时候 上传干净的音频即可,24G的显存,5分钟的歌曲音频也没事。
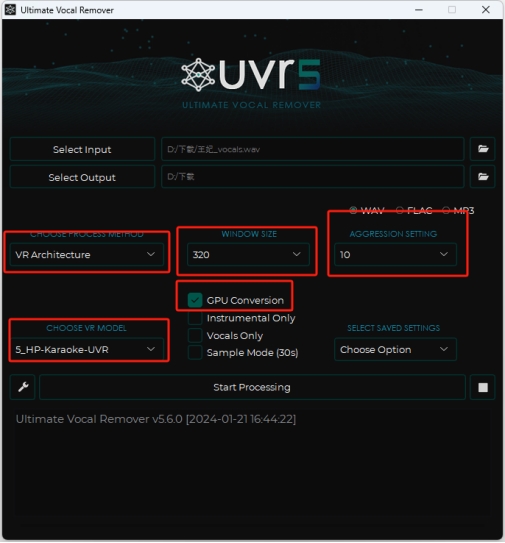
注意:推理上传的歌曲同样需要进行人声分离,离线工具可以考虑UVR5,在线服务可以选择,但是每天有1-2次免费机会:
https://vocalremover.org/zh/cutter
推理完成后,再把伴奏上加上即可。
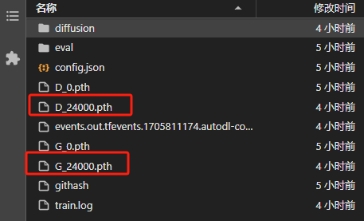
训练的主模型在目录下:
·
autodl-tmp/so-vits-svc/logs/44k
推理只需要保留模型文件和配置文件:G开头的模型文件和config.json。
命令行推理使用命令:
·
·
# Example
python inference_main.py -m "logs/44k/G_30400.pth" -c "configs/config.json" -n "君の知らない物語-src.wav" -t 0 -s "nen"
其中 -m和-c参数指定模型和配置文件,可以是绝对路径。
-n 需是相对raw文件夹的相对路径,即把推理音频放在raw文件夹下,且是wav格式。
-s 是声音的名称,也可以在config.json中找到。
以上就是本次分享的教程,enjoy yourself!
出自:https://mp.weixin.qq.com/s/9B1tnfjwbS9KezhNc0llsg