2024GTC大会上,黄仁勋右手B200,左手H100,理所当然地有了新人忘旧人:“我们需要更大的GPU,如果不能更大,就把更多GPU组合在一起,变成更大的虚拟GPU。”
英伟达公布的Blackwell架构的B200 GPU,亲手把网红显卡H100拍在了沙滩上。
按照黄仁勋的介绍,B200理论上的AI性能可达20PFLOPS,是H100的五倍。相比H100的800亿晶体管规模,B200的晶体管规模高达2080亿。
 图片来自:GTC 2024
图片来自:GTC 2024
一般来说,芯片算力提升的最常用方法是采用先进制程,用更高的密度在芯片里塞进更多晶体管。如摩尔定律所说:
集成电路上可以容纳的晶体管数目,大约每经过18个月到24个月便会增加一倍。
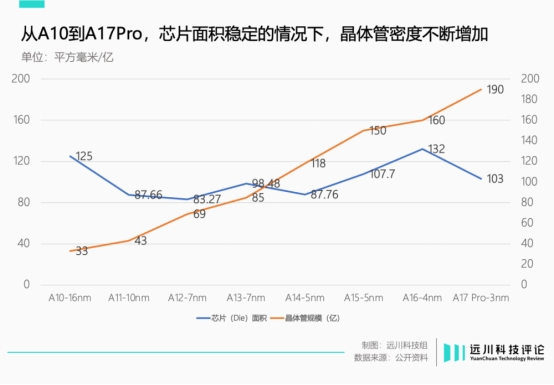
比如采用7nm工艺的A100 GPU,芯片(Die)面积为826mm² ,内有542亿晶体管;采用5nm(台积电N4)工艺的H100,芯片面积缩小为814mm² ,晶体管数量反而暴涨至800亿。
然而,B200在晶体管数量提高近三倍的同时,并没有用更先进的3nm工艺,而是采用了和H100一样的5nm工艺。黄仁勋所说的“大”和“组合”,是字面意义上的:
从技术原理看,B200其实是把两块芯片“拼”成了一个大芯片。
在英伟达的PPT演示里,两颗GPU从边缘“无缝粘合”在一起,面积X2的同时,算力翻倍。

1+1=2的方法看似简单粗暴,背后却是一场在物理学边缘的冲锋与冒险。
1+1有时候不等于2
工厂提高生产力有两种办法:一是扩建厂房,装进更多的生产线;二是升级生产线,在厂房面积不变的情况下,增加生产线数量。
芯片公司一直以来都在采用第二种方法:通过生产线创新(工艺制程),在有限的芯片面积里塞进更多晶体管,避免扩建厂房带来的房租成本上涨。
但这种方式的局限性在于,生产线创新(工艺制程)对应的研发成本越来越高,甚至有高过房租的趋势。H100采用的5nm工艺,很可能就是GPU量产的极限制程,继续下探到3nm,很可能成本上吃亏。
扩建厂房的确是一个办法,但放在芯片生产上,会遇到一个中国人很熟悉的问题:土地供应有限。
每一颗芯片都是从12寸的硅晶圆(土地)上“切”下来的,那么芯片(厂房)面积越大,每块晶圆能“切”出来的芯片就越少。
再考虑到良率和大面积芯片的散热问题(施工事故),单个芯片成本会成倍提高。
由此衍生出了第三种思路:建一个一模一样的厂房,让两个厂房同时生产,既避开了成本问题,又提高了生产效率。
这种方法听上去简单,但实践起来难于登天。
芯片在执行计算任务时需要经历两个阶段:数据传输和计算,数据传输花费时间过多,计算“空载”,就会造成算力的浪费。就像两间厂房需要一个工头传达指示,工头在A厂房发表讲话时,B厂房的工人都在摸鱼。
这就导致在一块主板上封装10颗芯片,性能非但不会提高10倍,反而很可能连两倍都不到。
2011年,英伟达发布了GTX590显卡,最大特点是在一个PCB板上装了两颗GPU芯片。
但在具体的游戏中,想同时调用两颗GPU的算力,不仅需要专门的软件支持,性能也只有单颗芯片的130%左右。
原因就在于,大量的算力被低效的数据传输浪费了。
 GTX590显卡里有两颗GPU芯片
GTX590显卡里有两颗GPU芯片
为了解决产线工人趁着工头不在消极怠工的问题,英伟达团队在2017年发表论文,提出了名为“可组合封装GPU”的架构,核心在于将多颗GPU集成在同一个芯片封装内。
传统的芯片封装是“先封再拼”,即两颗芯片封装完毕,再用导线连接。英伟达的方案是“先拼再封”,先把两颗芯片拼成一个大芯片,再封装到一起。
把芯片(厂房)之间的物理距离缩减到0,工头传递指示,两边的工人同时学习贯彻,降低数据传输时间,实现1+1=2。
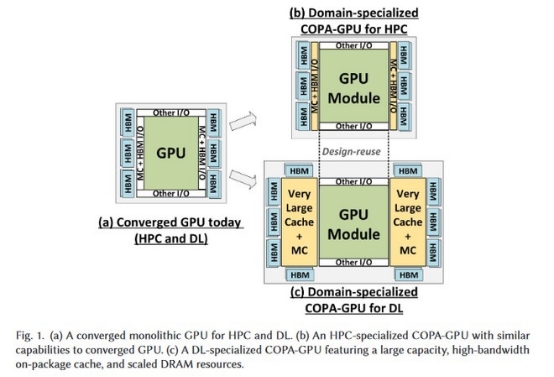
几个月后,老对手AMD表示论文谁不会写,刊发论文展示了4颗GPU集成在同一封装内的设计,宣称其性能比当时的最强GPU还要高45.5%,并且coming soon。
但无论是英伟达还是AMD,都没能把这个方案真正“soon”出来。
第一个让1+1=2的,是苹果。
苹果的超能力就是有钱
2022年,苹果发布了M1 Ultra芯片,其最大特点是直接将两颗M1 Max芯片“粘合”在一起,变成一张大芯片,业内戏称“胶水大法”。
1+1=2的意义正如苹果在新闻稿中所说:
M1 Ultra 在工作时依然表现出一枚芯片的整体性,也会被所有软件识别为一枚完整芯片,开发者无需重写代码就能直接运用它的强大性能。这在史上从无先例。

M1 Ultra由两颗一模一样的M1 Max芯片拼接而成
苹果之前,几乎所有的“缝合”方案,都无法解决芯片在连接过程中产生的损耗,使得性能往往“1+1<2”。M1 Ultra的背后,是一个名为UltraFusion的“缝合技术”。
按照苹果官方的说法,Ultra Fusion由苹果与台积电共同研发。但从经验看,苹果发挥的最大作用,是以“技术冠名费”的方式,报销了台积电的研发开支。
两颗芯片的缝合,核心是要解决芯片间的数据传输问题。
为了实现“无缝粘合”,苹果用上了台积电最昂贵、最先进的封装技术——第五代CoWoS-S。[2]
传统的传输方式是将两颗芯片封装在一块基板上,芯片之间的传输由引线解决。CoWoS方案在基板和芯片之间加了一层硅中介层,通过在硅中介层里布线,间接将两颗小芯片连接起来,连接密度是现有技术的两倍。
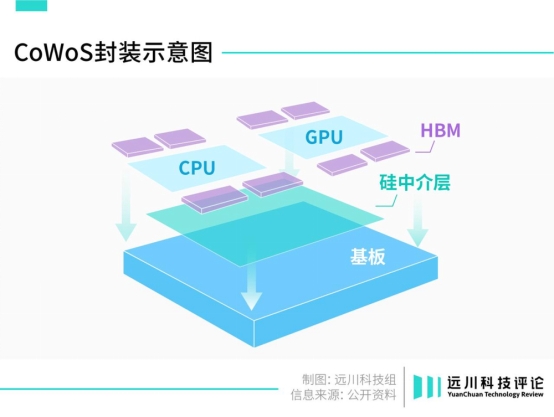
这个技术的关键就在于硅中介层,也是烧钱的根源。
硅中阶层本质上是一片硅晶圆,也就是“切”芯片的原材料。仅仅为了做连接,就要另加一层硅晶圆的费用,这手笔恐怕只有苹果做得出来。
后来,英伟达在H100上采用了更成熟的CoWoS,成本仍超过4000美元。苹果作为最初的试错者,成本只会更高。
除了CoWoS,苹果的钱还烧在了“缝合”技术上[2]。
芯片制造的本质,是在硅晶圆上刻画复杂电路。但在实际制造过程中,电路不是直接刻在硅晶圆上的,而是先刻在一个掩膜版上,再通过光刻和刻蚀把电路“转移”到硅晶圆上。
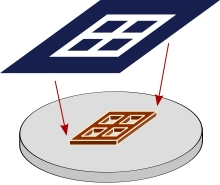
英伟达当年遇到的问题是,GPU芯片本身面积就大,一旦两颗GPU拼接,就会超过正常掩膜版的大小(H100的面积已经接近台积电5nm掩模版的极限),电路就无法被完整地刻画。
苹果提出的解决方案是,1个掩膜版不够,咱直接上四个吧。
通过四个掩膜版“缝合”,将电路刻画的面积增加到2500mm² ,是英伟达同期GPU的3倍多(815mm²)。
在芯片制造中,很大一部分成本就来自掩膜版制作。
掩膜版生产需要Mask Writer(掩膜版写入机),精密程度堪比光刻机。而且Mask Writer只在掩膜版制作时使用,每种芯片只做一次,难以摊薄成本。
除此之外,由于Ultra Fusion用到了大量新技术,比如连接芯片的高纵横比硅通孔(TSV)技术,用于散热的新型非凝胶型热界面材料(TIM)等[2],台积电都是拿着发票找苹果报销的。
M1 Ultra发布时,业界都没有准确的成本推算。不是研究员水平不到位,实在是技术过于先进,算不出来。
高科技产业最关键的问题不是技术如何实现,而是谁来掏钱把论文和实验室里的数据变成可以量产的产品。不知道看着M1 Ultra的拼接示意图,会不会有久远的记忆攻击黄仁勋。
技术狂人的商业冒险
最早试图解决的1+1<2问题的,既不是英伟达也不是苹果,而是台积电元老蒋尚义。
2009年,回归台积电的张忠谋请回已经退休的蒋尚义。在后者带领下,台积电以“后闸级”技术路线成功超越三星率先量产28nm工艺。但在研发过程中,蒋尚义发现晶体管单位制造成本不降反升,制程升级提升性能的性价比开始降低。
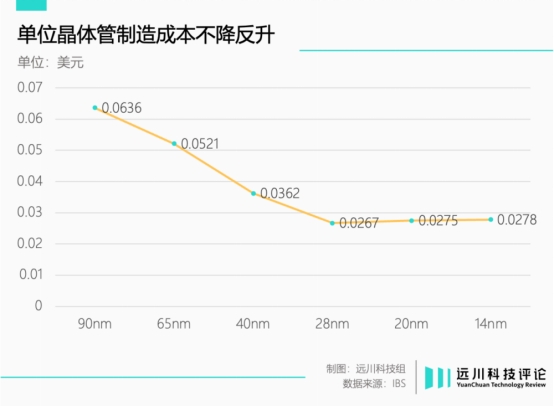
拿着张忠谋批的1亿美元预算和400多人的工程师团队,蒋尚义带队开始了“超越摩尔计划”。
传统互联技术下,传输速率已经触及天花板。蒋尚义开始尝试一种新思路:
把两颗芯片放到一起封装,物理距离缩短了,传输速度自然提高。为了区别于传统封装,蒋尚义将其命名为“先进封装”。
2011年,台积电得到FPGA大厂赛灵思订单,凭借CoWoS以及共同开发的硅通孔(TSV)等技术,成功将4个28nm FPGA芯片拼接在一起,推出了史上最大的FPGA芯片。
然而,大部分客户对CoWoS兴致寥寥,赛灵思的订单杯水车薪。
不是台积电技术不够好,实在是先进封装太贵了。
老客户高通的高管在与蒋尚义共进午餐时直白表示,CoWoS技术很好,但“我只愿意为它花费1美分/平方毫米”,而台积电当时的售价是7美分/平方毫米[3]。
据说英伟达也是台积电CoWoS的第一批目标客户之一,因为数据传输的瓶颈一直是困扰GPU计算的核心问题。但听到台积电的报价后,英伟达当场表示,老技术还能再凑合几年[3]。
另一方面,先进制程还在稳步推进,先进封装的理念显得过于超前,毕竟领导还在开卡罗拉,你就别急着换宝马了。
因此,先进封装团队在台积电内部的一度边缘化,甚至被当做老干部疗养院。后来跳槽三星的梁孟松,就认为自己被调往先进封装业务属于“下放”。
随后,台积电开始给CoWoS做减法,掏出了替代方案“InFO”,将昂贵的硅中介层换成其他材料,牺牲了连接密度,但成本大幅下降。
紧接着,台积电遇到了可以靠一己之力改变供应商命运的超级甲方:苹果。
2013年前后,由于与三星在手机市场的竞争,苹果开始将芯片代工交由台积电。
凭借InFO方案,台积电在16nm工艺的基础上,制造出了比三星14nm性能更强的A10处理器,贡献了历代iPhone中第二轻薄的iPhone 7[5]。
有了苹果的大单的,台积电的先进封装业务迅速盘活,并在2022年拿出了震惊业界的M1 Ultra芯片。2024年开年,这个攻坚十多年的“胶水大法”,又被用在了英伟达的新核弹B200上。英伟达顺势拿下冠名权,将这项技术命名为“NV-HBI”。
先进封装方案依然昂贵,但对今天的英伟达来说,成本两个字怎么写,他们可能已经忘了。
尾声
除了CoWoS,另一个被生成式AI带火的技术HBM,其探索同样可以追溯到十年前。
CoWoS拿到赛灵思的第一笔订单时,蒋尚义大喜过望,但赛灵思的动机却让他有些哭笑不得:把四个老芯片拼在一起,直接当成新产品加价卖,就不用自己开发新产品了[3]。
在美国计算机历史博物馆的采访中,蒋尚义回忆道[3]:“我开发技术的初衷是解决性能瓶颈问题,在我看来,我的创新并没有被用在好的地方”。
科技革命很难推动技术创新,反而是技术创新让科技革命成为可能。创造历史的人,永远无法预见自己在历史进程中的坐标。
在我们不曾踏足的物理学的边境,还有无数伟大的创新尚在不为人知的角落。
参考文章:
[1] NVIDIA Blackwell Architecture and B200/B100 Accelerators Announced: Going Bigger With Smaller Data,Anandtech
[2] 苹果UltraFusion技术,厦门云天半导体
[3] 蒋尚义万字自述,披露台积电的登顶之路,新芽
[4] 台积电的先进封装是这样炼成的,天下杂志
[5] 苹果iPhone 7 A10处理器的新封装在技术和商业上都产生了巨大的影响,Yole Development
[6] 苹果M1 Ultra解密:业内首个GPU裸片集成,如何实现,集微网
[7] Apple Will Help TSMC to Be in the Leading Position in the Next Era,utmel
本文来自微信公众号:远川科技评论 (ID:kechuangych),作者:何律衡,编辑:李墨天
https://mp.weixin.qq.com/s/A63GU5X3J_S076X7Jtg7Mw