无显卡+纯本地跑Qwen1.5版模型!0基础闭眼部署指南!适用绝大部分开源模型!llama2+Mistral+Zephyr通杀!
在新年几天,把知识图谱和高级RAG应用干完!
干完了,我们继续干agent!干教育组项目!
接下来我们会用到纯本地的环境,做知识图谱+RAG应用!
我需要部署一个本地开源模型,完成任务!
但雄哥带回家的笔记本电脑,没有显卡!
怎么办?
刚好qwen发布了1.5 版本!而且一下更新了:0.5B, 1.8B, 4B, 7B, 14B, 72B
6个尺寸版本!
最小的尺寸仅0.5B!
就是不知能力如何!
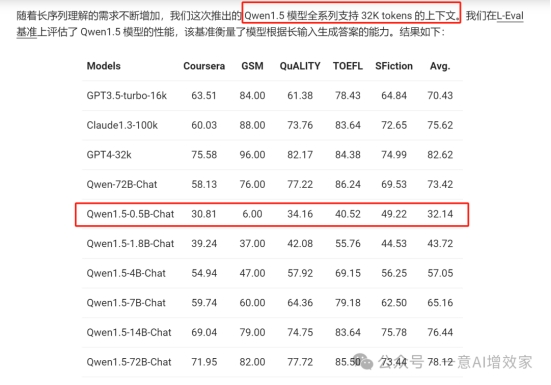
我们先看看他常规尺寸的数据,这么看,各项数据,不管放在国内外,在开源阵营中,都是非常能打的!
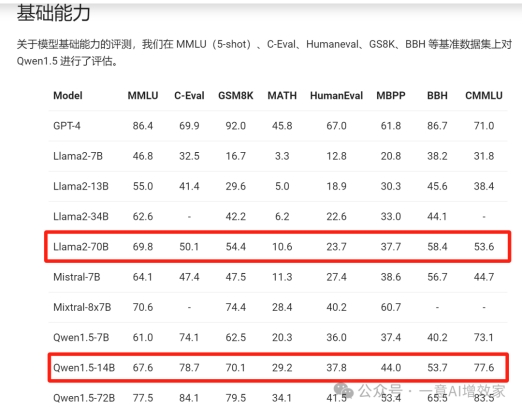
但雄哥本地没有显卡,只能用CPU来跑,而且日后接API出来做知识图谱和RAG,小尺寸模型才是我的菜!
来看看小尺寸的表现!
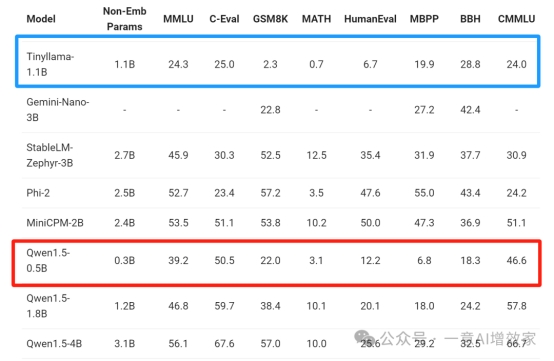
嗯!就它了!
雄哥本地没有任何显卡,只有CPU!到时跑知识图谱,那个温度+音浪~
已经有画面了!
人的专注力只有10分钟,那,话不多说!
① 部署ollama推理环境!
② 下载qwen1.5版本模型!(全)
③ 启动推理!跑起来!
价值内容,仅对知识星球会员开放,被长辈催婚,不如关门学习,快加入星球,一起打卡学习吧!
我们已经做了大模型微调、知识库+RAG、数据预处理、langchain+llama_index的内容!点击下方小程序申请加入!
第一部分:部署ollama推理环境
ollama!是一个操作简单的大模型部署工具!可以无缝接入到各大应用中!
当然!支持langchain+llama_index!来看看它的优势!
运行环境:纯本地
支持系统:Mac、linux、win系统的WSL2
算力要求:零!雄哥16G内存,0显存,照样跑!
部署方式:一条指令搞掂,无需安装依赖!
docker:完美使用!
GitHub地址:https://github.com/ollama/ollama
接下来,雄哥用win11系统的WSL和docker两种方式来部署它!
如果你是小白,没关系,你可以把ollama理解为一个手机系统,大模型就是一个APP!
只有安装了系统,我们才能启动一个APP,一样道理!
好!动起手来,跟着雄哥把系统部署下来!
1.1 安装wsl+docker
是的,雄哥是0基础教,那一定是从这个开始的!wsl和docker几乎是捆绑在一起的!
首先,我们要先安装wsl!这是win系统的linux虚拟机,完全独立于win系统!这样无需安装双系统了!
安装!对你日后的AI环境使用,都有好处,雄哥的使用率极高!
安装wsl有自动和手动两种,雄哥用自动挡,没成功~
没关系,手动安装也是一眨眼的事!
现在在开始菜单按钮右键,管理员身份运行终端!
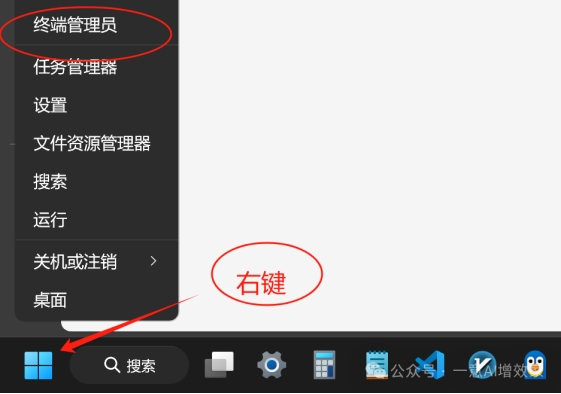
输入以下指令,回车!启动wsl功能
·
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
继续!输入以下指令,回车!启动虚拟机功能!
·
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
打开电脑的“应用商店”,搜索并安装wsl!
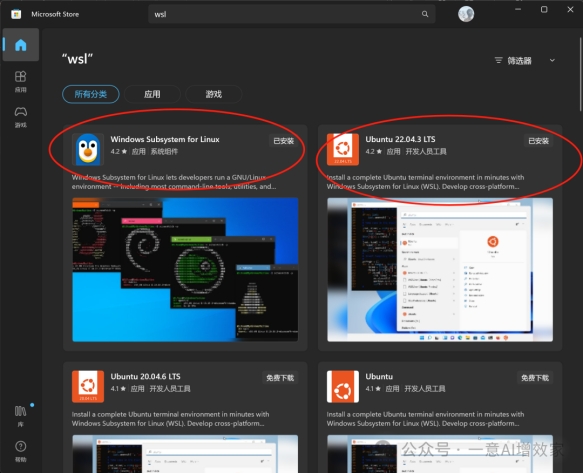
回到刚刚的窗口,看看安装成功没!输入以下指令!回车!
·
wsl --list --verbose
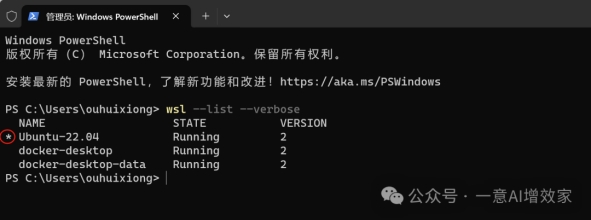
注意看!星标在不在新安装的这个版本上!
如果不在,输入以下指令,将新安装的wsl设置为默认版本!
否则是无法启动的!
·
wsl --set-default-version Ubuntu-22.04
现在,该安装docker了!
在知识星球会员盘下载docker后!直接下一步安装!
安装成功后,注意要点设置!打钩!
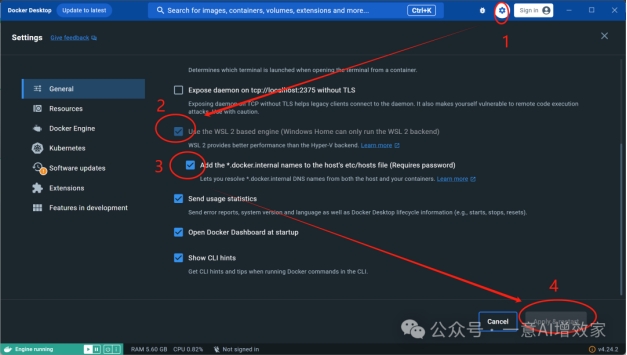
全部搞掂!
1.2 安装ollama!
打开刚刚那个WSL小企鹅!这是linux和wsl的安装指令!
一条搞掂,输入后回车!
·
curl https://ollama.ai/install.sh | sh
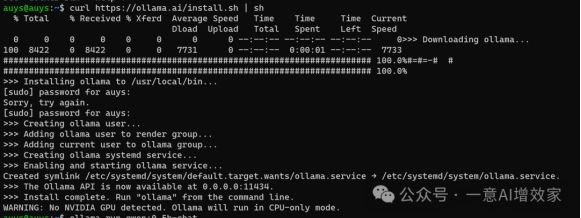
整个下载几分钟搞掂!因为雄哥本地的笔记本,没有显卡,只有CPU,所以它提示我,会用CPU来运行模型!
没关系!
下载完了,这个系统就搞掂了!
之后运行模型只需要一条指令!
是不是很简单?
甚至不用安装依赖!
上面已经安装好了!不需要再做任何操作了!
当然,你也可以用docker安装,如果你还想拓展更多花活,你就可以玩docker了,也是一条指令搞掂!
两个系统是独立的,一个在docker,一个在wsl中!
·
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama

第二部分:下载模型!(全)
雄哥实在太爱这个工具了,下载模型只需要一条指令!无需魔法!
首先!雄哥要下载qwen1.5版本的模型,ollama专门做了一个模型商店!
上面有绝大部分的开源模型!以下是qwen1.5版本仓库的商店链接!
·
https://ollama.ai/library/qwen/tags
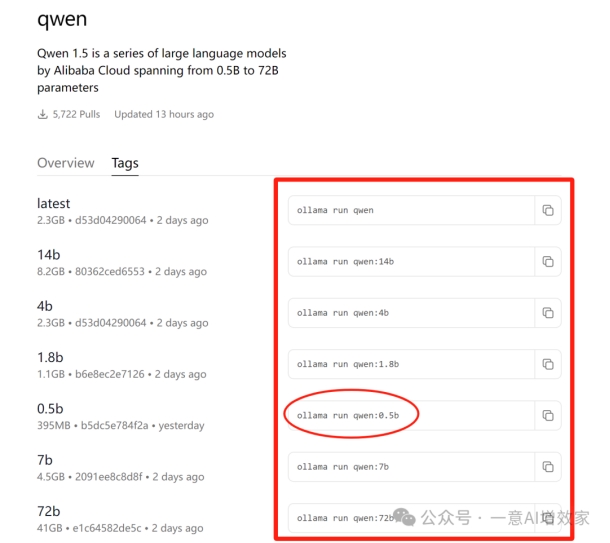
直接在wsl窗口输入以下指令,回车!
·
ollama run qwen:0.5b

这是支持的所有开源模型的商店链接!
客观您慢慢挑~
https://ollama.ai/library
注意!在docker中的操作是完全不同的!
使用以下命令。
仅 CPU
·
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
有英伟达GPU的
1.
安装 Nvidia 容器工具包。
2.
3.
在 Docker 容器中运行 Ollama
4.
·
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
运行模型
现在,您可以在容器内运行类似 qwen1.5_0.5b 的模型。
·
docker exec -it ollama ollama run qwen:0.5b
第三部分:启动推理!跑起来!
跑起来!
一条指令!
·
ollama run qwen:0.5b-chat
没错!还是它!
如果你下载完,会自动进入chat,退出后,也可以用它来启动!

你有什么问题在,直接在窗口就可以跟它对话,CPU,也非常快!
简单问了两个问题!
问1:树上有10只鸟,开 枪打死一只,树上还有几只鸟?
答1:当开枪打死一只之后,树上可能会剩下9只鸟。但请注意,这只是一个假设的计算,并没有考虑到所有可能的情况。
问2:你是谁
答2:我是来自阿里云的大规模语言模型——通义千问。我不仅能够理解和生成高质量的文字,而且还能进行深度对话和知识查询,为用户提供更便捷的服务。
整个回答,还算简洁,没什么多余的话,这只是0.5B的!跑完了这个,我感觉我的电脑可以跑4B的,16G显存,马上下载试试!
反正一条指令干完所有事,大家也动起手来
qwen1.5系列,全系都是32K,真的好评!
雄哥好好玩下
后续我们要用它来部署纯本地的LLM,接API来做知识图谱+RAG应用!
出自:https://mp.weixin.qq.com/s/Hx0C0GG63iHm6W_PlQdhJw