今天分享一个来自同济大学Haofen Wang的关于检索增强生成的报告:《Retrieval-Augmented Generation (RAG): Paradigms, Technologies, and Trends》。质量不错,推荐阅读!
大语言模型的局限性和实际应用面临的问题

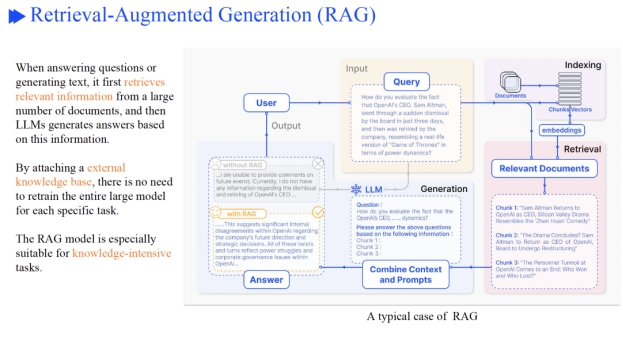
RAG指的就是检索相关信息来辅助大模型回答
优化大模型的性能通常可以从提示工程、RAG或者微调入手

RAG对比微调

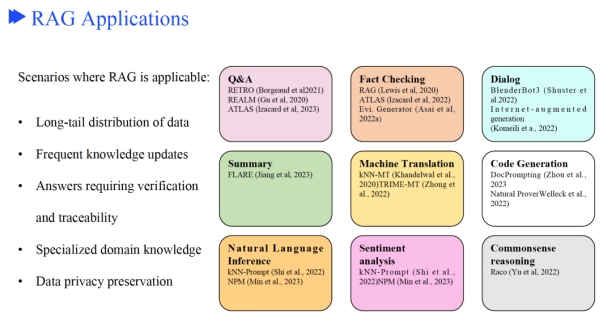
RAG的应用场景
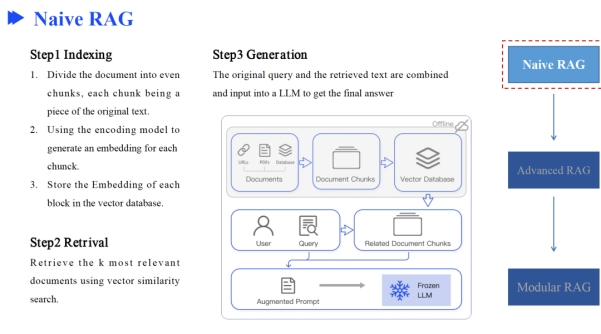
Naive RAG就是建索引、召回、生成三步走
进阶的做法还会考虑索引优化、召回前后做一些额外处理

模块化RAG考虑了更多更全的模块

三类RAG的对比

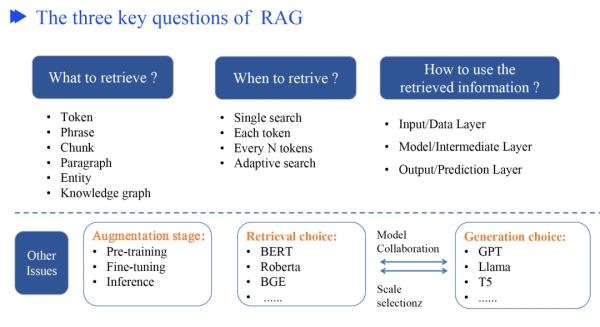
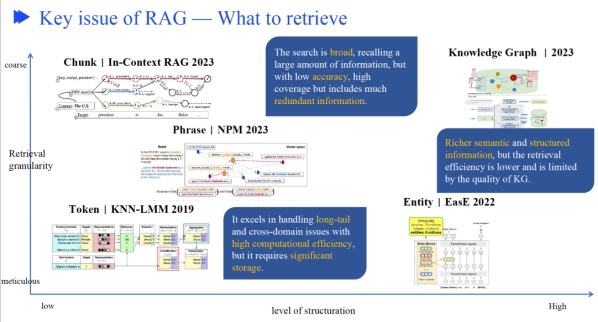
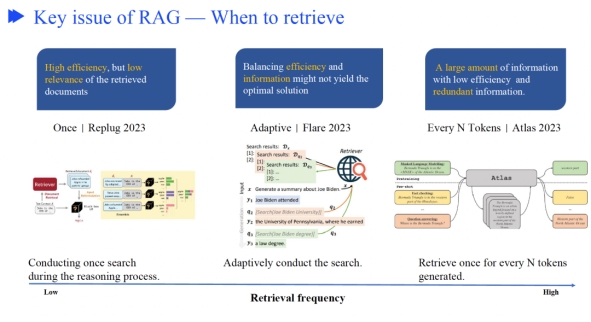
做RAG经常考虑的三个问题,召回什么、什么时候召回、如何利用召回的信息

RAG的发展总览

数据索引怎么优化

结构化语料库

对召回的来源进行优化

知识图谱作为召回的数据源

对查询进行优化

对文本嵌入进行优化

对检索的过程进行优化,比如可以迭代召回

还可以把RAG跟微调进行结合
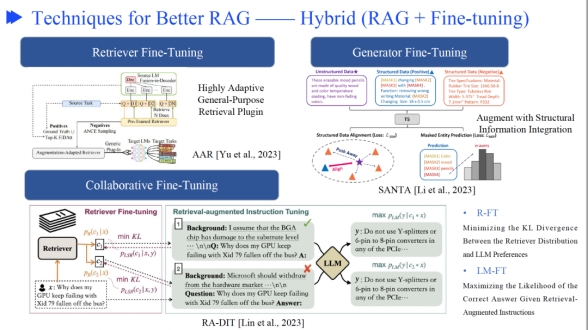
相关研究总结

评价RAG的有效性
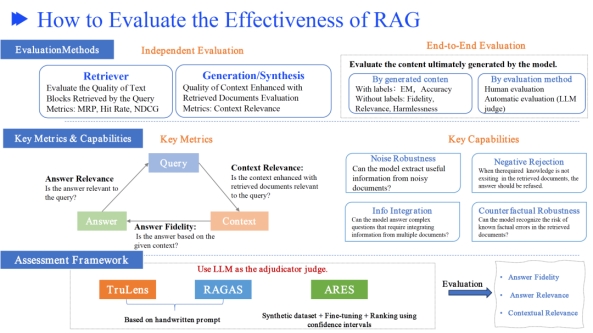
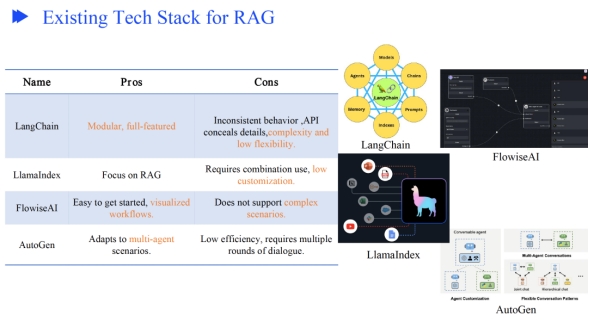
一些常用的RAG框架
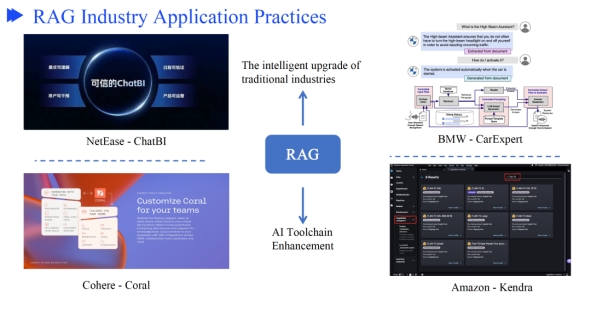
工业应用
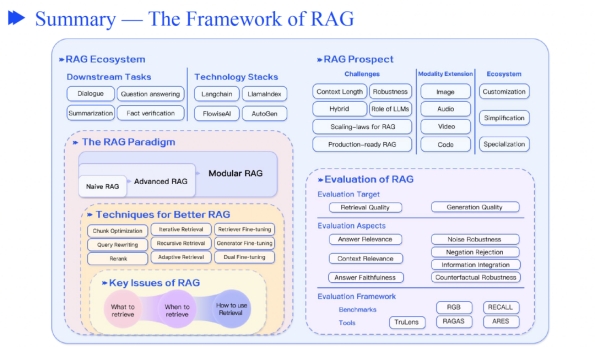
RAG总结
三大趋势
 存在的挑战
存在的挑战

扩展到多模态
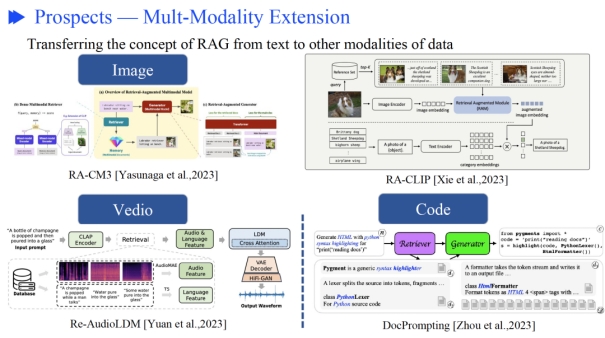
生态发展

出自:https://mp.weixin.qq.com/s/K62uaJJlW8BSD_90Sat5Zw