“曼哈顿计划(Manhattan Project)是二战期间由美国莱斯利·理查德·格罗夫斯将军领导,美国物理学家罗伯特·奥本海默负责的一项历史性的原子弹研制计划。历时3年,总投资25亿美元。同时期,德国、日本、英国、加拿大、俄国也先后加入了这项军备竞赛。”
曼哈顿工程并不仅仅是一项科技挑战,它是一个集科技、人力、资源和时间于一体的复杂系统工程。结合当下大模型人工智能领域的盛况与投入,将其比喻成曼哈顿工程并不夸张。
这篇文章我计划就技术原理、数据算力和资源以及时间计划等方面聊一聊大模型训练工程相关的那些事。
01
—
技术原理
面对复杂的系统工程,科学原理和基础指导对项目的成败起到了决定性作用。正如曼哈顿工程以核裂变的链式反应为科学理论基础,业界大模型训练同样奉行一些指导性原则,我愿意称为第一性原理:
· Scaling Laws[1][2]: 这一原则基于观察到的模型训练规模与性能之间的关系,强调规模的扩大可以带来性能的提升
· Language Model is Compression: 这种理论观点,将语言模型看作是对信息进行压缩的工具
· 超大规模模型涌现能力和现象: 随着模型规模的增大,模型的能力和表现将出现一些新的、小模型上面未曾预见的特性和现象
这些原则不仅揭示了大模型训练的复杂性,也指导了该领域的研究和发展。基于这些科学的认识理解,业界铺开了训练大模型的运动。其中最有实践指导价值的是 Scaling Laws,然后是基于大模型基座能力的下游任务和流程,以及大规模分布式训练能力。
Scaling Laws
简言之,Scaling Laws 是 OpenAI 发现的一些关于计算量、模型规模、训练数据量对模型效果影响的规律。这些因素对模型效果提升具有平滑一致的幂率扩展效率。
因为训练超大规模语言模型的时间和金钱成本巨大,在给定计算资源预算的情况下,准确评估和预测模型的最佳超参和能够收敛的位置至关重要。在 Scaling Laws 的指导下,小模型上面一系列实验和拟合,可以准确地用于预估超大规模模型收敛的状态。从而进一步指导实验管理、数据管线、算力规划、效果评估、训练框架、模型设计等。
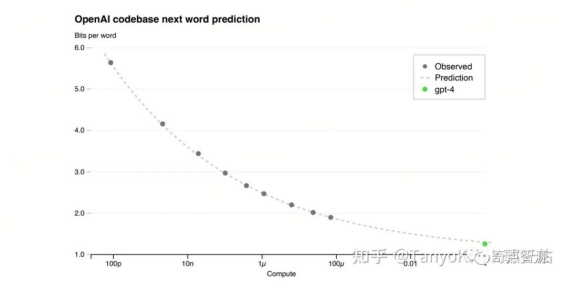
OpenAI 使用小模型拟合的幂率规律准确预测了 GPT4 最终的训练 loss
AI 模型流程与评估
在大模型相关原理的指导下,AI 模型的构建也逐渐演化出了不同的阶段和流程。
预训练、继续预训练、对齐(SFT、RLHF)
这些流程和术语对大家来说应该并不陌生。OpenAI ChatGPT 的发布,制造的最热门的技术话题便是 Alignment 和 RLHF。在我看来,预训练模型(Base 模型)始终是智能的基础,而Alignment的主要目标是实现有效的人机接口。此外,由于RLHF的高成本和相对复杂性,SFT作为其廉价替代品已经获得了广泛的应用。
虽然 Base 模型足够强大,但是在面临领域差异时难免存在数据分布的一致性问题(举例来说,中英领域的差别,给国产大模型创造了足够大的空间)。因此,在面临下游任务时基于 Base 模型结合新数据的继续预训练和 finetune 也是一种技术路径。
多模态
多模态能力是指能够处理和融合多种不同类型数据的模型能力。这些数据可以包括文本、图像、音频、视频等不同模态的数据。大语言模型仅仅赋予了模型接受语言输入的能力,多模态则想给大模型安装上眼睛和耳朵。最近 GPT-4V 和 Gemini 多模态的发布都给足了亮点。在通向 AGI 的路上,多模态还拥有很大的想象空间。
大模型的评估
针对大模型的能力,业界开发出了许多开源、闭源评测框架和榜单。其中最常见的评价指标包括, MMLU、常识推理、数学推理、阅读理解、代码能力等等。尽管出现了一些刷榜作弊的嫌疑,但是这些指标和榜单确实推进了业界大模型的进展。
分布式训练框架与效率
分布式训练框架被尤为看重的原因是,它是深度学习的操作系统,实现模型和发挥算力的基础。好在大模型时代的模型结构单一和收敛,这些操作系统上面仅需要适配少量几类模型即可覆盖绝大多数技术路径的需求。虽然支持大模型训练的分布式框架仍有不少,但是社区主流的方案主要还是
Transformers + DeepSpeed: 以 ZeRO 系列的模型并行策略著称
Megatron-LM: 支持 Tensor, Sequence, Pipeline 等多种 Parallel 并行方式
关于 DeepSpeed 和 Megatron-LM 的相关策略我这类不展开介绍,两者各有优劣,目前被采纳训练千亿模型最多的还是 Megatron-LM。那么为什么大模型训练偏爱 3D 并行呢,比如Megatron-Turing NLG(530B), Bloom(176B)?
相信对大模型训练感兴趣的同学,都会熟悉和了解一些使用分布式训练的具体策略和 tricks。我们不如来算一笔账,看看这些 tricks 是为什么。
大语言模型训练过程中对显存的占用,主要来自于 optimizer states, gradients, model parameters, 和 activation 几个部分。
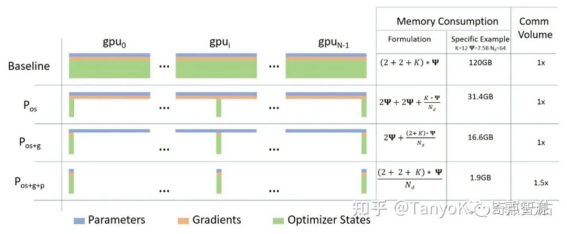
DeepSpeed ZeRO1-3 策略侧重于对 Optimizer, Gradients 和 Model States 在 data-parallel 维度切分
DeepSpeed 的 ZeRO 系列主要是对 Optimizer, Gradients 和 Model 的 State 在数据并行维度做切分。优点是对模型改动小,缺点是没有对 Activation 进行切分。
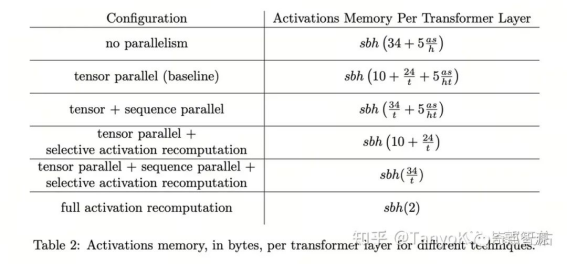
截图来自https://arxiv.org/pdf/2205.05198.pdf
Megatron-LM 拥有比较完备的 Tensor 并行和 Pipeline 并行的实现。上面的表格罗列了 Megatron-LM 不同并行策略对 Activation 显存占用的预估。
借助 ZeRO 策略我们可以将模型按照 DP 并行维度切分,借助 TP 对 activation 和 model 参数进行切分。假设使用 1024 张 A100 训练 Llama 65B,采用 ZeRO2 + TP8 + DP 128 + FlashAttention2 分布式策略,Batch 设为 4M tokens。对显存预估的公式如下:
Per GPU Activation Memory = L * s * b * h * 34 / N(GPUS) = 87.04 GiB
Per GPU Model States = 2 * size(Model)/ TP + 14 * size(Model) / DP = 23.35 GiB
这个预估还不包括 PyTorch CacheAllocator 和 NCCL 通信 buffer 的显存开销,但是已经超出了 80GiB 显存。在不考虑 Pipeline 并行的前提下,通常还需要考虑一些其他的显存节省策略如:
activation recomputation
gradient accumulation
然而,我们还知道 full recomputation 引入的额外计算开销约为 30-40%。这种策略在计算集群规模小的时候可以接受。但是在计算资源充沛的情况下,意味着更大的浪费。
因此在超大规模的情况下还会考虑到 Pipeline 并行,它的主要优点这里不展开了。总结一下,Pipeline 策略进一步分割了 Activation Memory,从而避免使用 Recomputation 策略;另外,拓扑网络感知的 TP 和 PP,DP 策略能够更好地利用 NvLink 和 RoCE 网络带宽。
总结下千卡千亿模型的训练效率相关的 tricks:
ZeRO-Offload 和 ZeRO-3 增加了带宽的压力,变得不可取
使用 3D 并行来降低每卡显存占用,避免 recomputation
GA>1,主要是为了 overlap 和减少 bubble
Flash Attention2 (显存的节省上面等效于 Selective Activation Recompute)
ZeRO1 Data Parallel + Tensor Parallel(Sequence Parallel) + Interleave Pipeline Parallel
为什么不用 ZeRO2,因为在 GA 的基础上面 Gradient 切分反而多了通信次数
FP16/BF16/FP8 训练,通信压缩
Overlapped distributed optimizer
除此之外,还有一个非常重要的事情。就是训练集群故障的监测和自动恢复,备机也很重要(因为现在的分布式训练框架和算法并没有那么灵活,计算节点的掉线而不能恢复,通常意味着训练长时间的中断)。毋庸置疑,集群的稳定性能够节省机时的浪费,快速可恢复能够保障训练的迭代顺利进行。
训练框架重要性的基础逻辑就是在有限的时间和硬件上,充分发挥更多的算力。
02
—
数据、算力和资源
Scaling Laws 揭示了数据规模、模型规模和计算资源对AI模型性能的影响规律。在其影响下,实践中数据算力和资源的配置也明显呈现出相应趋势。
数据
使用更大规模的训练数据成为了基本的实践常识,总的经验是数据越多越好,质量越高越好 @黄文灏。
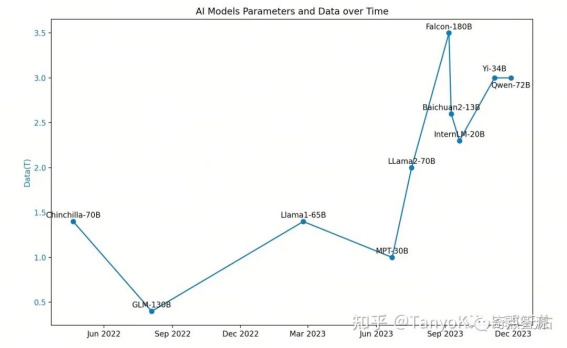
虽然,互联网上面拥有海量的文本数据。但是据统计通过筛选、去重之后的高质量数据在几十 T tokens 这个数量级。获取数据来源、收集可用数据和清洗更大规模的高质量数据也成为了工程中必备的一部分。另外在 RLHF 环节,也需要耗费大量的人力用于数据标注与评估。
算力
你说为啥大模型创业公司动辄独角兽,融资上亿美金。除了前景被看好之外,确实是个销金窟。据悉,OpenAI 拥有数万的 GPU 算力资源储备,然而 GPU 持有量超过 5 万枚的企业不超过 5 家。按目录价向云服务每年租用 5000 卡 A800 差不多也接近 1 亿美金了。还需要考虑公司的人力和运营成本。
面对美国的禁令,芯片行业产能的限制,国产大模型领域存在着显著算力供需矛盾。算力的短缺,应该就是当前算力成本高企的客观真实原因。比较具有标志性意义的事件是,今年 8 月 Coreweave 这家以挖矿起家的公司以 Nvidia GPU 作为抵押获得了 23 亿美元的巨额债务融资。国内也有不少该领域的算力供应商紧锣密鼓地加紧上市步伐。
在此背景下,大模型公司的”算力租赁出海”和”算力储备安全”和”算力国产替代“成为了不得不被重视的问题。
争夺AI入场券:BAT、字节美团们竞逐GPU
李开复在 Yi 模型发布时称已经准备好未来 18 个月所需的算力
科大讯飞回应美国AI芯片出口管制:华为昇腾910B能力基本可对标英伟达A100
但是大范围的铺开使用,国产算力还是远水解不了近渴,其中的关键点包括产能受限、软件适配和生态还不够成熟。在面对很强的时间成本和风险压力的情况下,大模型初创公司很难将生家性命赌在这上面。
融资
数据需要钱、算力需要钱、顶级人才需要钱、公司运营需要钱;造就了该领域疯狂资本融资的盛况。其他领域 Pre-A 轮融资可能是千万人民币;而大模型领域的 Pre-A 轮融资通常是以亿美元计。完全不在一个数量级上面。这也规定了大模型领域的商业逻辑将与其他领域的不同。
市场上面融资比较容易看起来有两种途径,一种是已经有了阶段性成果的,一种是靠大佬刷脸的。因此当前领域内创业公司大佬云集。也不能埋怨各家初创公司跳的很欢,各种渠道宣发。因为,这个领域前期竞争游戏确实烧钱。几亿美金可能也就能烧个一年半载,之后则必须进入下一轮融资或自我造血。
由此大模型如何进行商业化是相关企业必须要面对的问题。在 ToC 领域,使用大模型创建的 Super APP 被认为具有巨大的商机。在 ToB 领域,基于自研大模型进行生态和软件服务建设也很有前景。现在大模型赛道这么卷,无论何种形式,让大模型被使用起来,让各种飞轮运转起来都是企业要头等重要考虑的事情。
03
—
时间计划
接下来,大模型的训练迭代和大模型的应用同等重要。

截图来自: https://mp.weixin.qq.com/s/Wd0NiIZPJMZk52UneGTyfQ
根据当前业界大模型发布的情况来看,国内再有一年估计要有一批大模型公司掉队。
先不考虑显存和分布式框架及策略的制约,假设你拥有一个与 Llama2 训练效率一样的训练集群(A100x2048 RoCE)。根据 OpenAI Scaling Laws 的 ”Universality of overfitting” 规律如下:

将模型从 70B 扩展到 140B 和 280B,分别需要 3.5T tokens 和 5T tokens 的训练数据。类 Llama 的模型结构的训练的计算量使用公式 C=6ND 来估计。按照上面的假设和分析估计得到各种规模模型训练完成的时间如下图:
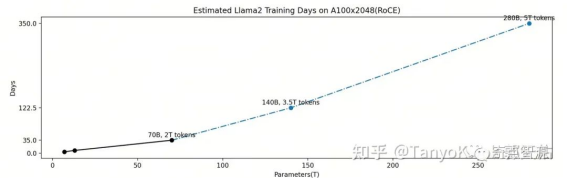
不难看出,在一个 A100x2048(RoCE) 的集群上面训练一个 140B 的模型大概需要 4 个月时间,而280B 的模型则大约需要一年。意味着在资源规划合理的情况下,再有一年半载的时间,大模型推高到 280B 将很有可能是一个常态。大胆假设,国内第一梯队的大模型团队需要按照这个时间来倒推计划。
考虑到训练数据越多越好,质量越高越好,结合最近社区新发布模型的训练数据量来看,很可能还需要更多的数据来训练大规模的模型。这种情况下,训练完成的总机时成倍地增长完全有可能。为了跟上这种节奏就不得不紧锣密鼓地进行
算力的扩展(构建 4k 集群,万卡集群)
探索更高效的模型训练方式(比如 MoE 训练)
展示模型的差异化能力(超长上下文的效果,多模态的效果)
国内头部大模型团队已经过了一段时间的磨合,赛道内的游戏也迅速迈过了爬坡期,深水区的问题才更具挑战性,也更能见出分晓。
04
—
总结
正如曼哈顿计划一样,AGI 是一项科技挑战,它是一个集科技、人力、资源和时间于一体的复杂系统工程。在 OpenAI ChatGPT 的引领下,在资本的催化下,在 Scaling Laws 的指导下,国内大模型领域风风火火地走过了快速发展的一年。
曼哈顿计划给科技、政治、文化带来深远的影响。今天,AGI 领域的技术发展会给社会带来什么样的影响呢?我想这个问题留给大家回答。从技术人的视角和偏好来说,我期待在这波资本洪流中,大模型一线的团队不要被资本裹挟走,而是真的能够制造出来产业变革。对于产业里面的其他伙伴来说,我非常看好遍布产业上下游的机会。希望有一天,大模型真的像操作系统一样开放和基础,就这个话题可以再写一篇。不管怎样致敬 AI Alliance。
出自:https://mp.weixin.qq.com/s/R9yfPrdZL9NnRwu0k03W-Q