在这个新的冒险中,我们将深入研究使用开源大型语言多模态(LLMM)构建检索增强型生成(RAG)系统的过程。值得注意的是,我们的重点是在不依赖LangChain或Llama索引的情况下实现这一点;相反,我们将利用ChromeDB和Hugging Face框架。
这篇文章探索和了解如何创建一个高效的RAG系统,结合ChromeDB和Hugging Face等开源技术在大型语言多模态应用中的力量。
RAG是什么?
检索增强型生成(RAG):提升人工智能理解和输出能力
在人工智能领域,检索增强型生成(RAG)作为一种变革性技术脱颖而出,优化了大型语言模型(LLMs)的能力。本质上,RAG通过允许模型从外部来源动态检索实时信息,增强了AI响应的特异性。
大型语言模型,如GPT-3,擅长生成类似人类的语言,但在提供最新或特定领域的信息方面存在限制。RAG通过整合检索机制解决了这个问题,从外部知识库中提取相关事实,确保回答在语言上正确且在事实上准确。
该架构将生成能力和动态检索过程无缝结合,使AI能够适应不同领域中不断演变的信息。与广泛的重新训练不同,RAG提供了一种经济高效解决方案,使AI保持最新和相关性,而无需对整个模型进行彻底改造。
换句话说
想象你有一个超级聪明的机器人朋友。这个机器人朋友擅长交谈,会说聪明的话,但有时它并不知道一切。现在,我们有一个特殊的技巧叫做检索增强型生成(Retrieval-Augmented Generation),简称RAG。
RAG通过在需要回答问题或谈论特定事物时从一本事实大书中查找信息,帮助机器人朋友变得更聪明。因此,它不再只是从自己的大脑中说出事情,而是可以检查这本大书,以确保提供最好和最准确的答案。这就像为机器人朋友拥有一本很酷的百科全书一样,使它与我们聊天更加令人敬畏。
为什么选择RAG?
1. 增强的准确性和可靠性:RAG通过将大型语言模型(LLMs)重定向到权威的知识来源,解决了其不可预测性的问题。它降低了呈现虚假或过时信息的风险,确保了更准确和可靠的回答。2. 提高透明度和信任度:生成式AI模型(如LLMs)通常缺乏透明度,使得难以信任其输出结果。RAG引入了透明度,使组织能够对生成的文本输出拥有更大的控制权,解决了关于偏见、可靠性和合规性的担忧。3. 减少幻觉:LLMs容易产生幻觉响应——连贯但不正确或编造的信息。RAG通过确保回答基于权威来源来帮助解决这个问题,减少了在金融等关键领域中出现误导性建议的风险。4. 改善高风险环境中的决策制定:在金融等准确性、可信度和及时性至关重要的领域,RAG显著提高了性能。实时更新和依赖权威来源减少了决策过程中灾难性损失、监管问题或代价高昂的错误的可能性。
5. 成本效益的适应性:RAG提供了一种经济高效的方法来改进AI输出,而无需进行广泛的重新训练/微调。组织可以通过根据需要动态获取特定细节来保持最新和相关性,确保AI能够适应不断演变的信息。
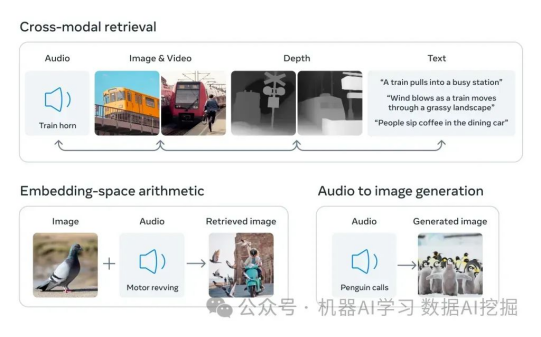
6. 什么是多模态?亲爱的冒险家,请考虑一下:当你听到某人的声音时,你能认出这个人,而当你看到他们时,你也知道他们是谁。本质上,多模态涉及有两个输入——音频和视觉——并产生一个单一的输出,从而实现更丰富和全面的理解。
以CLIP为例的更详细的解释
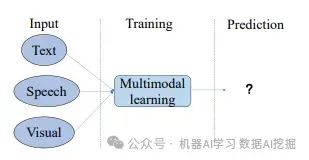
简单来说,多模态学习涉及教导计算机/AI模型理解和学习不同类型的信息,如图像、文本或语音。这很有用,因为它使模型能够做出更好的预测,模仿人类学习的方式。
该模型对不同的输入做出相同(非常相似)的嵌入向量,这些向量表示相同的事情。
像
Image2Text:这部分重点在于使用基于transformer的架构来改进复杂图像的字幕生成。Text2Image:在这里,想法是使用文本输入来生成视觉表示。自然语言处理(NLP)的进步使得可以将文本编码为嵌入向量,从而指导图像生成过程。Images supporting Language Models专注于将视觉元素整合到纯文本语言模型中。传统的模型假设单词的意义仅来自文本上下文,而这个任务则探索了将视觉维度纳入以增强语言模型。
OpenAI的CLIP模型通过自然语言监督学习视觉概念。只需提供要识别的视觉类别的名称,CLIP就可以应用于任何视觉分类基准测试,类似于“零次学习”。
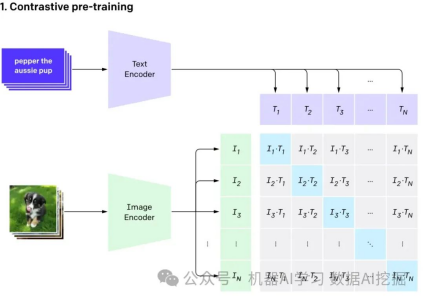
简单来说,它为一张猫的图片和单词“猫”生成了相同的(非常相似的)向量。
MLLM(多模态大型语言模型)是一种探索将各种数据类型(包括图像、文本、语言、音频等)整合到一起的多模态语言模型。虽然像GPT-3、BERT和RoBERTa这样的大型语言模型在基于文本的任务上表现出色,但在理解和处理其他数据类型时面临挑战。为了解决这个限制,多模态模型结合了不同的模态,使得对多样化的数据有更全面的理解。
多模态大型语言模型(MLLM)代表了自然语言处理中的一个范式转变,超越了传统的基于文本的方法。这些模型以GPT-4为代表,可以无缝地处理多种数据类型,包括图像和文本,从而实现对信息的更全面的了解。MLLM通过整合各种模态解决了纯文本模型的限制,并在基准测试中展示了人类水平的性能。
构建 RAG pipeline?
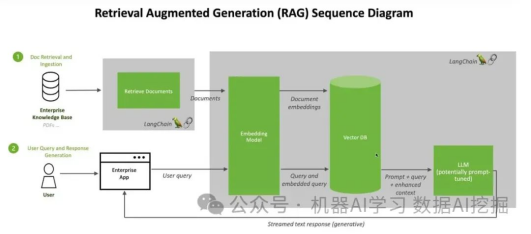
我们计划创建RAG管道,其中涉及使用CLIP嵌入图像和文本。接下来,我们打算将这个嵌入的数据存储在ChromDB向量数据库中。最后,我们将利用Hugging Face的MLLM根据检索到的信息参与用户聊天会话。
我们将使用Kaggle上的图像和维基百科上的信息创建一个花专家聊天机器人。
1. 安装所需软件包
·
! pip install -q timm einops wikipedia chromadb open_clip_torch!pip install -q transformers==4.36.0!pip install -q bitsandbytes==0.41.3 accelerate==0.25.0
2. 预处理数据
在这个步骤中,你应该自己完成,但我将图像和文本放在一个文件夹中,像这样:
1.
创建向量数据库;请随意使用任何工具,但我建议使用ChromaDB。
2.
3.1 首先,您需要确定嵌入函数。我将使用默认的嵌入函数并向您展示如何创建一个自定义的嵌入函数。
·
import chromadb
from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunctionfrom chromadb.utils.data_loaders import ImageLoaderfrom chromadb.config import Settings
client = chromadb.PersistentClient(path="DB")
embedding_function = OpenCLIPEmbeddingFunction()image_loader = ImageLoader() # must be if you reads from URIs
自定义嵌入函数
·
from chromadb import Documents, EmbeddingFunction, Embeddings
class MyEmbeddingFunction(EmbeddingFunction): def __call__(self, input: Documents) -> Embeddings: # embed the documents somehow or images return embeddings
3.2 我们将创建两个集合,一个用于文本,另一个用于图像
·
collection_images = client.create_collection( name='multimodal_collection_images', embedding_function=embedding_function, data_loader=image_loader)
collection_text = client.create_collection( name='multimodal_collection_text', embedding_function=embedding_function, )
# Get the ImagesIMAGE_FOLDER = '/kaggle/working/all_data'
image_uris = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if not image_name.endswith('.txt')])ids = [str(i) for i in range(len(image_uris))]
collection_images.add(ids=ids, uris=image_uris) #now we have the images collection
我们使用Clip,可以使用文本像这样检索图像
·
from matplotlib import pyplot as plt
retrieved = collection_images.query(query_texts=["tulip"], include=['data'], n_results=3)for img in retrieved['data'][0]: plt.imshow(img) plt.axis("off") plt.show()

·
from PIL import Imageimport numpy as np
query_image = np.array(Image.open(f"/kaggle/input/flowers/flowers/daisy/0.jpg"))print("Query Image")plt.imshow(query_image)plt.axis('off')plt.show()
print("Results")retrieved = collection_images.query(query_images=[query_image], include=['data'], n_results=3)for img in retrieved['data'][0][1:]: plt.imshow(img) plt.axis("off") plt.show()

3.3 文本集合
·
# now the text DBfrom chromadb.utils import embedding_functionsdefault_ef = embedding_functions.DefaultEmbeddingFunction()
text_pth = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if image_name.endswith('.txt')])
list_of_text = []for text in text_pth: with open(text, 'r') as f: text = f.read() list_of_text.append(text)
ids_txt_list = ['id'+str(i) for i in range(len(list_of_text))]ids_txt_list
collection_text.add( documents = list_of_text, ids =ids_txt_list)
3.4 检索文本。我们在嵌入过程中也使用了CLIP,因此我们可以通过文本或嵌入来获取信息
·
results = collection_text.query( query_texts=["What is the bellflower?"], n_results=1)
results
{'ids': [['id0']], 'distances': [[0.6072186183744086]], 'metadatas': [[None]], 'embeddings': None, 'documents': [['Campanula () is the type genus of the Campanulaceae family of flowering plants. Campanula are commonly known as bellflowers and take both their common and scientific names from the bell-shaped flowers—campanula is Latin for "little bell".\nThe genus includes over 500 species and several subspecies, distributed across the temperate and subtropical regions of the Northern Hemisphere, with centers of diversity in the Mediterranean region, Balkans, Caucasus and mountains of western Asia. The range also extends into mountains in tropical regions of Asia and Africa.\nThe species include annual, biennial and perennial plants, and vary in habit from dwarf arctic and alpine species under 5 cm high, to large temperate grassland and woodland species growing to 2 metres (6 ft 7 in) tall.']], 'uris': None, 'data': None}
Embeddings
·
query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg'raw_image = Image.open(query_image)
doc = collection_text.query( query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0]
4. 现在我们应该加载MLLM
我根据它的存储库使用了一个小型的,这就是我们如何使用它的方法。
·
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="visheratin/LLaVA-3b", filename="configuration_llava.py", local_dir="./", force_download=True)hf_hub_download(repo_id="visheratin/LLaVA-3b", filename="configuration_phi.py", local_dir="./", force_download=True)hf_hub_download(repo_id="visheratin/LLaVA-3b", filename="modeling_llava.py", local_dir="./", force_download=True)hf_hub_download(repo_id="visheratin/LLaVA-3b", filename="modeling_phi.py", local_dir="./", force_download=True)hf_hub_download(repo_id="visheratin/LLaVA-3b", filename="processing_llava.py", local_dir="./", force_download=True)
·
·
from modeling_llava import LlavaForConditionalGenerationimport torch
model = LlavaForConditionalGeneration.from_pretrained("visheratin/LLaVA-3b")model = model.to("cuda")
·
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("visheratin/LLaVA-3b")
·
from processing_llava import LlavaProcessor, OpenCLIPImageProcessor
image_processor = OpenCLIPImageProcessor(model.config.preprocess_config)processor = LlavaProcessor(image_processor, tokenizer)
让我们使用它
·
·
question = 'Answer with organized answers: What type of rose is in the picture? Mention some of its characteristics and how to take care of it ?'
query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg'raw_image = Image.open(query_image)
doc = collection_text.query( query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0]
plt.imshow(raw_image)plt.show()imgs = collection_images.query(query_uris=query_image, include=['data'], n_results=3)for img in imgs['data'][0][1:]: plt.imshow(img) plt.axis("off") plt.show()

现在让我们准备好模型的输入。
·
prompt = """<|im_start|>systemA chat between a curious human and an artificial intelligence assistant.The assistant is an exprt in flowers , and gives helpful, detailed, and polite answers to the human's questions.The assistant does not hallucinate and pays very close attention to the details.<|im_end|><|im_start|>user<image>{question} Use the following article as an answer source. Do not write outside its scope unless you find your answer better {article} if you thin your answer is better add it after document.<|im_end|><|im_start|>assistant""".format(question='question', article=doc)
·
inputs = processor(prompt, raw_image, model, return_tensors='pt')
inputs['input_ids'] = inputs['input_ids'].to(model.device)inputs['attention_mask'] = inputs['attention_mask'].to(model.device)
·
from transformers import TextStreamer
streamer = TextStreamer(tokenizer)
·
·
%%timeoutput = model.generate(**inputs, max_new_tokens=300, do_sample=True, top_p=0.5, temperature=0.2, eos_token_id=tokenizer.eos_token_id, streamer=streamer)
·
·
print(tokenizer.decode(output[0]).replace(prompt, "").replace("<|im_end|>", ""))
出自:https://mp.weixin.qq.com/s/TS2TSwcg8n6PpIinwOI4Fw