一个适合初学者的介绍,附带 Python 代码。前半部分原理,后半部分代码。
大模型的最大的作用就是取代人工, 进行降本增效,而很多时候,类似于自动客服, 自动回复用户的提问, 或者作为自动客服,回复网友/用户的评价,就会是一个重要的应用场景(虽然客服不算贵,但千千万万的客服就比较贵了), 本文讨论如何使用RAG技术来进行youtube的自动评论回复。
我们可以对 Mistral-7b-Instruct 进行了微调,以使用 QLoRA 来回应 YouTube 评论。尽管经过微调的模型成功地捕捉到了我在回应观众反馈时的风格,但它对技术问题的回答却与我的解释不相符。
在这里,我将讨论如何通过检索增强生成(即 RAG)来提高 LLM 的性能。


大型语言模型(LLMs)已经展示出了令人印象深刻的能力,可以存储和部署大量知识以响应用户查询。
虽然这使得创建像 ChatGPT 这样强大的 AI 系统成为可能,但以这种方式压缩世界知识两个关键限制:
第一,LLM 的知识是静态的,即在新信息可用时不会更新。
第二,大模型可能对在其训练数据中并不突出的小众和专业信息有着不足的“理解”。这些限制可能导致对用户查询产生不良(甚至是虚构的)模型响应。
一种我们可以减轻这些限制的方法是RAG, 例如客户常见问题解答、软件文档或产品目录。这使得我们可以更健壮和适应性更强的AI系统。
检索增强生成, or 或RAG, 是这样一种方法。本文中,我提供了对 RAG 的高级介绍,并分享了使用 LlamaIndex 实现 RAG 系统,并且给出示例 Python 代码。
什么是 RAG?
LLM 的基本用法包括输入Promt并获得回复/Response
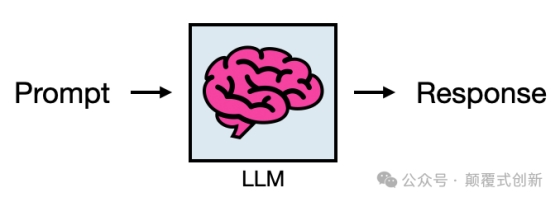
RAG 通过向这个基本过程添加一步来实现
即,执行检索步骤,根据用户的提示,从外部知识库中提取相关信息,并将其注入到提示中,然后传递给 LLM。在这里需要重点说明:我们在做搜索的过程中面临的所有技术难点, 在RAG中都会碰到,搜索相关的内容也可以参见: 在高德吃喝玩乐!LBS信息的AI技术应用
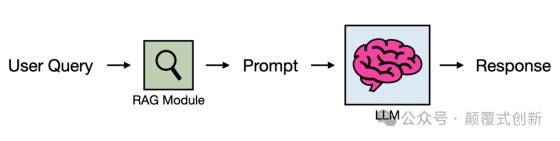
变与不变?
请注意,RAG 并没有从根本上改变我们使用 LLM 的方式;它仍然输入:prompt-in 和输出:response-out. RAG 简单地增强了这个过程(因此得名)。
这使得RAG 是一种灵活且(相对)直接的方式,可以改进基于 LLM 的系统. 另外,由于知识存储在外部数据库中,更新系统知识就像在表中添加或删除记录一样简单。
为什么微调会失效?
在这个系列的先前文章中讨论了fine-tuning, 这适应了现有模型的特定用例。虽然这是为 LLM 赋予专业知识的另一种方式,但从经验上看,微调似乎比 RAG 效果要差
如何RAG工作
RAG 系统有两个关键要素:检索器/Retriver和一个知识库/Knowledge Base
检索器
一个检索器接受用户提示并从知识库中返回相关项目。这通常使用所谓的方式为embedding 文本在概念空间中的数值表示。
换句话说,这些是数字代表着含义给定文本的。
文本嵌入可以用于计算用户查询与知识库中每个项目之间的相似度分数。这个过程的结果是一个每个项目与输入查询的相关性排名。
检索器然后可以取出前 k 个(比如 k=3)最相关的项目,并将它们注入到用户提示中。然后将这个增强的提示传递给 LLM 进行生成。
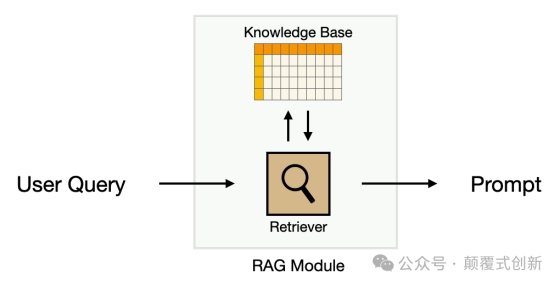
知识库
RAG 系统的下一个关键要素是知识库。包含您想要提供给 LLM 的所有信息. 虽然有无数种构建 RAG 知识库的方法,但在这里我将专注于从一组文档中构建知识库。
这个过程可以分解为4 个关键步骤
1.
加载文档- 这包括收集一系列文件,并确保它们处于可解析的格式(稍后详细介绍)
2.
分块文档—由于 LLM 具有有限的上下文窗口,因此必须将文档分割成较小的块。(e.g.,256 或 512 个字符长)。
3.
嵌入式块- 使用文本嵌入模型将每个块翻译成数字。
4.
加载到向量数据库— 将文本嵌入加载到数据库中(也称为向量数据库)。
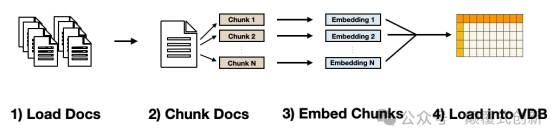
一些细微差别
构建 RAG 系统的步骤在概念上很简单,但是一些细微之处可能会使得在现实世界中构建一个系统变得更加复杂(类似于搜索,思路很简单, 就是匹配,但在落地的过程中细节非常多)
文档准备:RAG 系统的质量取决于从源文件中提取有用信息的能力。例如,如果一个文件没有格式并且充满了图片和表格,那么解析它将会比解析格式良好的文本文件更加困难。
选择合适的块大小:我们已经提到了由于 LLM 上下文窗口的需要进行分块。然而,还有两个额外的分块原因:
第一, 它可以降低(计算)成本。您向提示中注入的文本越多,生成完成所需的计算量就越大,而且通常成本越高,毕竟很多大模型的时候都是以input/output 的 tokens数量收费的。第二,性能。特定查询的相关信息往往局限在源文件中(通常,只有 1 句话就能回答一个问题)。分块有助于最小化传入模型的无关信息量
改善搜索- 尽管文本嵌入使得搜索变得强大且快速,但并不总是按照人们期望的方式工作。换句话说,它可能返回与用户查询“相似”的结果,但并不有助于回答查询,例如,"洛杉矶的天气如何?"可能返回"纽约的天气怎么样?".
通过良好的文档准备和分块是缓解这个问题的最简单方法。然而,对于一些使用情况,可能需要额外的改进搜索策略,例如使用meta-tags对于每个块,采用混合搜索,结合了基于关键词和嵌入式的搜索,或者使用一个reranker, 这是一个专门计算两个输入文本相似度的模型。
示例代码
使用 RAG 改进 YouTube 评论回复程序
具有对 RAG 工作原理的基本理解后,让我们看看如何在实践中使用它。我将在以下示例基础上进行构建。先前的文章, 在这里我对 Mistral-7B-Instruct 进行了微调,使用 QLoRA 来回复 YouTube 评论。我们将使用 LlamaIndex 来为之前微调的模型添加一个 RAG 系统。
该示例代码可以免费获取。Colab 笔记本, 可在提供的(免费)T4 GPU 上运行。此示例的源文件可在以下位置找到:GitHub 代码库。

Input
我们首先安装和导入必要的 Python 库。
·
!pip install llama-index
!pip install llama-index-embeddings-huggingface
!pip install peft
!pip install auto-gptq
!pip install optimum
!pip install bitsandbytes
# if not running on Colab ensure transformers is installed too
·
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings, SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.postprocessor import SimilarityPostprocessor
建立知识库
我们可以通过定义嵌入模型、块大小和块重叠来配置我们的知识库。在这里,我们使用了约 33M 参数。bge-small-en-v1.5来自 BAAI 的嵌入模型,可在 Hugging Face hub 上获得。其他嵌入模型选项也可在此处获得。文本嵌入排行榜。
·
# import any embedding model on HF hub
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
Settings.llm = None # we won't use LlamaIndex to set up LLM
Settings.chunk_size = 256
Settings.chunk_overlap = 25
接下来,我们加载我们的源文件。在这里,我有一个名为“XXX”的文件夹。文章,"其中包含我撰写的 3 篇关于中等文章的 PDF 版本"fat tails. 如果在 Colab 中运行此操作,您必须从文章文件夹中下载。GitHub 仓库并手动上传到您的 Colab 环境。
对于此文件夹中的每个文件,下面的函数将从 PDF 中读取文本,根据之前定义的设置将其分割成块,并将每个块存储在一个名为列表中。文档。
·
documents = SimpleDirectoryReader("articles").load_data()
由于这些博客是直接从 Medium 以 PDF 形式下载的,它们更像是网页而不是格式良好的文章。因此,一些部分可能包含与文章无关的文本,例如网页标题和 Medium 文章推荐。
在下面的代码块中,我会精炼文档中的块,删除文章主要内容前后的大部分块。
·
print(len(documents)) # prints: 71
for doc in documents:
if"Member-only story" in doc.text:
documents.remove(doc)
continue
if"The Data Entrepreneurs" in doc.text:
documents.remove(doc)
if" min read" in doc.text:
documents.remove(doc)
print(len(documents)) # prints: 61
最后,我们可以将精炼的块存储在向量数据库中。
·
index = VectorStoreIndex.from_documents(documents)
设置Retriver
有了我们的知识库,我们可以使用 LlamaIndex 创建一个检索器。VectorIndexRetreiver()返回用户查询的前 3 个最相似的片段。
·
# set number of docs to retreive
top_k = 3
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=top_k,
)
接下来,我们定义一个查询引擎,该引擎使用检索器和查询来返回一组相关的片段。
·
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever, node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.5)],
)
使用查询引擎
现在,有了我们的知识库和检索系统设置好了,让我们使用它来返回与查询相关的块。
·
·
query = "What is fat-tailedness?"
response = query_engine.query(query)
查询引擎返回一个包含文本、元数据和相关块的索引的响应对象。下面的代码块返回这些信息的更可读版本。
·
# reformat response
context = "Context:\n"
for i inrange(top_k):
context = context + response.source_nodes[i].text + "\n\n"
print(context)
·
Context:
Some of the controversy might be explained by the observation that log-
normal distributions behave like Gaussian for low sigma and like Power Law
at high sigma [2].
However, to avoid controversy, we can depart (for now) from whether some
given data fits a Power Law or not and focus instead on fat tails.
Fat-tailedness - measuring the space between Mediocristan
and Extremistan
Fat Tails are a more general idea than Pareto and Power Law distributions.
One way we can think about it is that "fat-tailedness" is the degree to which
rare events drive the aggregate statistics of a distribution. From this point of
view, fat-tailedness lives on a spectrum from not fat-tailed (i.e. a Gaussian) to
very fat-tailed (i.e. Pareto 80 – 20).
This maps directly to the idea of Mediocristan vs Extremistan discussed
earlier. The image below visualizes different distributions across this
conceptual landscape [2].
print("mean kappa_1n = " + str(np.mean(kappa_dict[filename])))
print("")
Mean κ (1,100) values from 1000 runs for each dataset. Image by author.
These more stable results indicate Medium followers are the most fat-tailed,
followed by LinkedIn Impressions and YouTube earnings.
Note: One can compare these values to Table III in ref [3] to better understand each
κ value. Namely, these values are comparable to a Pareto distribution with α
between 2 and 3.
Although each heuristic told a slightly different story, all signs point toward
Medium followers gained being the most fat-tailed of the 3 datasets.
Conclusion
While binary labeling data as fat-tailed (or not) may be tempting, fat-
tailedness lives on a spectrum. Here, we broke down 4 heuristics for
quantifying how fat-tailed data are.
Pareto, Power Laws, and Fat Tails
What they don't teach you in statistics
towardsdatascience.com
Although Pareto (and more generally power law) distributions give us a
salient example of fat tails, this is a more general notion that lives on a
spectrum ranging from thin-tailed (i.e. a Gaussian) to very fat-tailed (i.e.
Pareto 80 – 20).
The spectrum of Fat-tailedness. Image by author.
This view of fat-tailedness provides us with a more flexible and precise way of
categorizing data than simply labeling it as a Power Law (or not). However,
this begs the question: how do we define fat-tailedness?
4 Ways to Quantify Fat Tails
将 RAG 添加到 LLM 中
首先通过 Hugging Face hub下载精调模型
·
# load fine-tuned model from hub
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "TheBloke/Mistral-7B-Instruct-v0.2-GPTQ"
model = AutoModelForCausalLM.from_pretrained(model_name,
device_map="auto",
trust_remote_code=False,
revision="main")
config = PeftConfig.from_pretrained("shawhin/shawgpt-ft")
model = PeftModel.from_pretrained(model, "shawhin/shawgpt-ft")
# load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
作为基准,我们可以看到模型如何在没有任何文章上下文的情况下对技术问题做出响应。为此,我们使用一个 lambda 函数创建一个提示模板,该函数接受一个观众评论并返回一个 LLM 的提示。
·
# prompt (no context)
intstructions_string = f"""ShawGPT, functioning as a virtual data science \
consultant on YouTube, communicates in clear, accessible language, escalating \
to technical depth upon request. It reacts to feedback aptly and ends \
responses with its signature '–ShawGPT'.
ShawGPT will tailor the length of its responses to match the viewer's comment, \
providing concise acknowledgments to brief expressions of gratitude or \
feedback, thus keeping the interaction natural and engaging.
Please respond to the following comment.
"""
prompt_template = lambda comment: f'''[INST] {intstructions_string} \n{comment} \n[/INST]''' comment = "What is fat-tailedness?"
prompt = prompt_template(comment)
print(prompt)
[INST] ShawGPT, functioning as a virtual data science consultant on YouTube, communicates in clear, accessible language, escalating to technical depth upon request. It reacts to feedback aptly and ends responses with its signature '–ShawGPT'. ShawGPT will tailor the length of its responses to match the viewer's comment, providing concise acknowledgments to brief expressions of gratitude or feedback, thus keeping the interaction natural and engaging.
Please respond to the following comment.
What is fat-tailedness?
[/INST]
使用下面的代码将这个提示传递给模型。
·
model.eval()
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"),
max_new_tokens=280)
print(tokenizer.batch_decode(outputs)[0])
这是模型的回应(没有上下文)。
·
Great question!
Fat-tailedness is a statistical property of a distribution. In simple terms,
it refers to the presence of extreme outliers or heavy tails in the
distribution.
For instance, consider the distribution of heights in a population. A normal
distribution would have most people clustered around an average height with a
few people deviating slightly from the mean. However, in a fat-tailed
distribution, you would observe a larger number of people being significantly
taller or shorter than the average.
In finance, fat-tailedness is often used to describe the presence of extreme
market moves or outliers in financial returns. It's an important concept in
risk management and financial modeling.
I hope this explanation helps! Let me know if you have any questions.
尽管响应的风格和格式很棒,但模型对尾部厚重性的解释与我在我的定义中的不同。
让我们看看当我们包含适当的上下文时,模型的响应会发生什么。为此,我们创建另一个提示模板,该模板还可以从 RAG 系统中获取上下文。
·
# prompt (with context)
prompt_template_w_context = lambda context, comment: f"""[INST]ShawGPT, functioning as a virtual data science consultant on YouTube, communicates in clear, accessible language, escalating to technical depth upon request. \
It reacts to feedback aptly and ends responses with its signature '–ShawGPT'. \
ShawGPT will tailor the length of its responses to match the viewer's comment, providing concise acknowledgments to brief expressions of gratitude or feedback, \
thus keeping the interaction natural and engaging.
{context}
Please respond to the following comment. Use the context above if it is helpful.
{comment}
[/INST]
"""
接下来,我们将使用查询引擎和视图评论中的上下文来传递提示给模型。
·
prompt = prompt_template_w_context(context, comment)
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=280)
print(tokenizer.batch_decode(outputs)[0])
这是新的响应(带有上下文)
·
Great question!
Fat-tailedness is a property of a distribution that describes how much the
presence of extreme values (rare events) affects the overall statistics of the
distribution.
In the context of the video, the author discusses how Mediocristan and
Extremistan distributions differ in terms of fat-tailedness. Mediocristan
distributions have a relatively small impact from extreme values, while
Extremistan distributions are heavily influenced by extreme values.
The author also mentions that fat-tailedness is a more general concept than
specific distributions like Pareto or Power Laws. Instead, it lives on a
spectrum ranging from thin-tailed (Gaussian) to very fat-tailed (Pareto 80-20).
I hope that helps clarify things a bit! Let me know if you have any questions.
–ShawGPT
这样做比无上下文的回答更好地捕捉了我对 fat tails 的解释,甚至指出了 Mediocristan 和 Extremistan 的小众概念。
出自:https://mp.weixin.qq.com/s/rWm-vfOJEcONbYgw3oTf9Q