
来围观初代教父唱《野狼disco》
之前全网刷屏的阿里明星项目 EMO 终于正式开放了!
简单来说,EMO 可以使人像照片“动起来”。
不管是唱歌视频,还是讲话视频,只要提供一张肖像照片,外加一段音频,算法就会自动生成一段口型完全能对上、画面生动的视频出来。
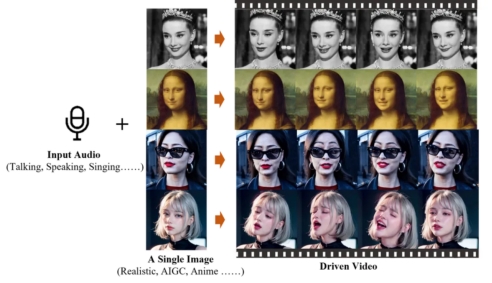 输入音频和一张图片,EMO就能生成对应的视频
输入音频和一张图片,EMO就能生成对应的视频
目前,用户直接下载登录通义千问,就能免费体验到 EMO 。
洗脑,让教父口嗨Rap的视频来了!
点开通义千问,「四木相对论」选择用Stable Diffusion和EMO结合,来试试视频效果。
把这张由Stable Diffusion 生成的 AI 小姐姐照片,丢进EMO操作界面,我们得到了下面这段视频:
,时长00:14

整体来说,视频的质量还是比较高的,不论是同步口型、人物眨眼、还是头部运动,都表现得不错。
当然视频中还是存在“一眼假”的地方,比如完全静止的大海和天空背景、似乎是悬浮在画面上的眉毛、忽大忽小的鼻孔和瞳孔等。
再来看看初代教父上演一段激情的《野狼disco》 RAP。
,时长00:30


上传的素材原图
成品视频一共30秒,需要等待 45 分钟来完成生成。
整体效果还是不错的,充满了洗脑感。
但除了初代教父的霸气与rap的完美结合、凶狠的眼神和近乎完美的口型匹配(尤其是最后那一句“哎呀我去”)之外,成品视频其实还有几秒的残次画面。

成品视频里出错的画面
我们看到,视频左上角的人脸会有膨胀收缩的变化,远景中的另外一只手出现了残影。更夸张的是,画面右侧在 25 秒左右的时候出现了一团漂浮的幻影。
出现这种现象的原因可能是,这张图片并不符合官方要求,只是侥幸通过了机审判定。
官方要求是,单人、大头照、没有手部。而这张图片有手,还有两个人,或许EMO的模型还没办法处理这么多的元素,所以出现了上述Bug。
自定义功能有限,生成需数十分钟
目前,用户直接下载登录通义千问,就能免费体验到 EMO 。
从打开通义千问App,到进入生成等待页面,用户会经历三个步骤:找到功能入口、找到生成视频入口、上传素材图片。

EMO功能的宣传页
打开通义千问后,直接在下方对话框中输入 “EMO”,就能直接跳转至 EMO 功能。
通义千问初始页面
EMO在通义千问中的名字叫「全民唱演」,点击底部的「立即体验」后,就能跳转至全民唱演的功能页面。
全民唱演首页
进入全民唱演模块,首页会有一些官方的热门模板,包含歌曲演唱、影视台词、及表情包。
全民唱演的首页,其实没有新建生成视频的入口,用户需要点击进入某个模板示例,才能找到对应的生成入口。
这也意味着用户无法自行上传音频内容,只能通过官方创建好的模板来上传图片,生成固定音频内容的视频。
换句话说,全民唱演目前还不支持定制化生成视频内容。
目前,官方模板库中有 22 首歌曲片段,42 个影视台词片段,27 个表情包素材。等于,用户现在只能体验一共 91 种不同的视频模版。

官方热门模板中排在首位的视频
进入首页某一个视频模板后,点击右下角的“演同款”,即可开始使用该模板来上传图片进行创作。
而上传图片的限制,可能会让用户进行多次尝试——系统会校验图片像素大小、人脸清晰程度、非多人、版权风控、画风检测、不能有头部倾斜、露出手部等条件。
根据模板创作的上传照片页面
如果上传的图片不符合某一个要求,比如尝试上传一张动漫画风的图片,系统会进行报错。

对用户上传图片的要求及错误示例
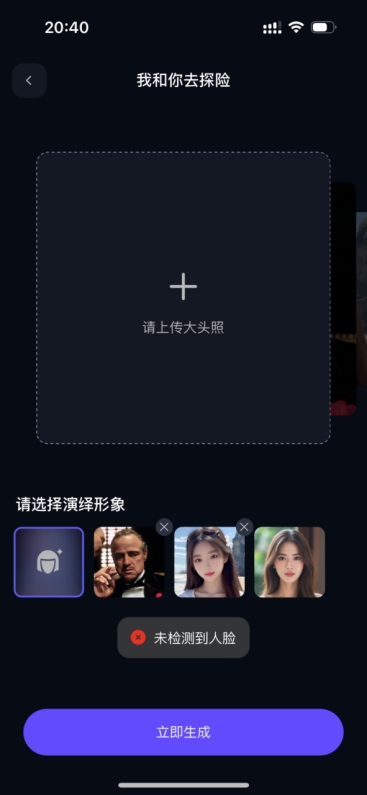
动漫画风图片无法检测到人脸
除了不符合画风、角度等的限制条件外,图片上传功能还加入了风控检测逻辑。
我们尝试上传了一张高清的蒙娜丽莎图片,就被直接拦截,提示“图片内容存在风险,请重新上传”。

上传图片命中了风控拦截逻辑
如果成功上传符合要求的图片,下一步EMO会让用户对图片进行手动截取,保证脸部完整出现在画面中。

手动调整人脸位置的操作
最后,确认调整脸部位置之后,点击右下角的“完成”,就能开始生成。
此时,页面中会显示该条任务的剩余处理时间。以本次体验选中的大约 14 秒的歌曲片段为例,生成视频的时间大约为 20 分钟。
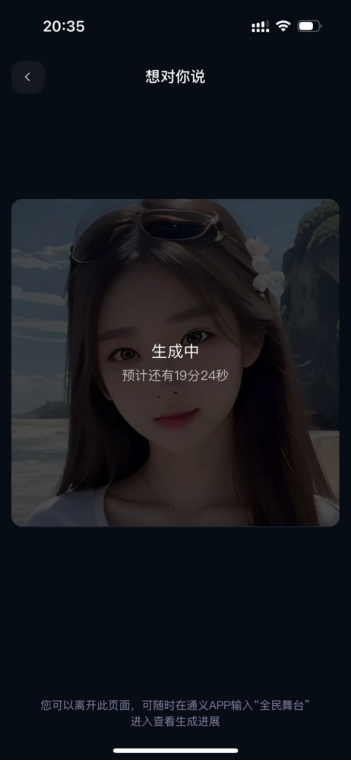
生成视频的等待页面
暂时还只是“玩具”
经过初步体验,EMO 的主要优缺点表现明显:
优点:
·
口型能够做到近乎完美的同步;
·
人物主体能够自然地进行眨眼、头部运动等;
·
缺点:
·
强制使用模板,不支持定制;
·
生成所需的等待时间太长;
·
从生成视频的质量来说,EMO 确实令人惊艳。
但它的缺点也非常明显,就是不支持定制。
而不支持定制主要体现在,EMO目前不允许用户自行上传音频。
这或许有几个考量:
首先,过于定制化的音频内容,可能会影响生成的视频质量。比如,如果用户上传相对比较小众的方言,由于模型训练数据不足的问题,口型生成可能会出错,导致最终的视频里口型与音频对不上。
此外,还有风控和版权方面的问题。
相比于图片,音频的风控拦截会更困难,而一旦拦截失败,违规的音频所生成的成品视频可能会带来非常大的负面影响。
比如上方小姐姐唱歌的视频最后,系统会自动拼接通义千问的 Logo 页面。
这就意味着一旦用户想办法规避了风控规则,很可能会生成一条包含品牌名称的问题视频。
最后,算力和存储的消耗也是非常重要的考量因素。
目前通义千问上的全民唱演,是允许用户免费进行体验的。
如果用户上传时间过长的音频文件,无论是存储音频,还是后续的算法生成视频所消耗的算力,都将是一笔高昂成本。
视频生成所需的长时间等待,也可能是在限制用户的整体生成次数,从而降低整体的算力消耗。
再加上,EMO结合固定的短时长模板,能将全民唱演的算力消耗控制在一个可以接受的体量内。
当然,也存在模型推理速度本身就比较慢的可能性。不过相比而言,控制算力消耗还是更有可能一些。
考虑到以上几个问题,EMO短期内完全放开限制看似不太可能。
如果它想被应用在更广阔的场景中(比如短视频、电影素材制作),可能只能寄希望于阿里能够早日将代码开源了。
出自:https://mp.weixin.qq.com/s/2VM9bZWkrnSIRULVilxDHw