还记得前阵子ChatGPT风靡一时但一直没全量发布的高级语音功能吗?
如今,一个甚至更加强大的实时语音对话AI模型开源了!它的名字叫做:Mini-Omni。
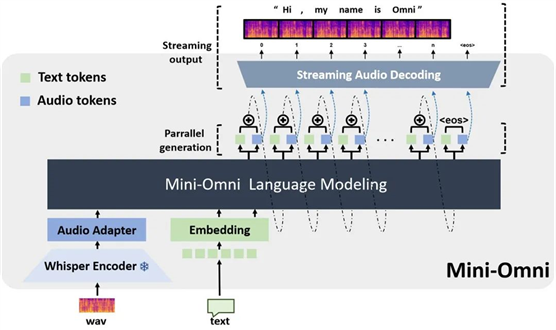
这个由gpt-omni团队开发的开源模型,可以说是语音助手界的一匹黑马。它不仅能实现实时的语音对话,更厉害的是,它还能同时生成文本和音频!
有网友兴奋不已:
"这简直就是科幻电影里的场景啊!以后我们是不是可以和AI助手进行无障碍的实时对话了?"
Mini-Omni的出现,可能会让现有的语音助手们瑟瑟发抖。
想想看,以后我们可能真的能和AI进行流畅的实时对话,就像在和真人聊天一样!
而数次跳票的ChatGPT 4o 语音功能,可能可以永久跳票了。
那么,Mini-Omni有哪些特性呢?
- 实时语音对话:这意味着你说话的同时,AI就能立即理解并回应,不再有明显的延迟。
- 同时生成文本和音频:这个功能简直太强大了!AI不仅能说,还能同步给出文字版本,对听力不好的朋友来说简直是福音。
- 流式音频输出:这个技术确保了对话的流畅性,让整个交互过程更加自然。
Mini-Omni的开源,很可能会引发语音交互领域的一场革命。它不仅能提升用户体验,还可能为听障人士带来更多便利。
想象一下,以后我们可能真的能和AI进行毫无障碍的实时对话,这是多么令人兴奋的事情啊!
对这个项目感兴趣的小伙伴们,我整理好了相关链接:
·
模型下载:https://hf.co/gpt-omni/mini-omni
·
论文地址:https://hf.co/papers/2408.16725
·
代码仓库:https://github.com/gpt-omni/mini-omni
Mini-Omni 官方介绍👇
Mini-Omni:语言模型在流式处理中的听、说、思考能力
Mini-Omni 是一个开源的多模态大型语言模型,能够在思考的同时进行听觉和对话。它具备实时的端到端语音输入和流式音频输出对话功能。
✅ 实时语音对话功能,无需额外的ASR或TTS模型。
✅ 边思考边对话,支持同时生成文本和音频。
✅ 支持流式音频输出。
✅ 提供“音频转文本”和“音频转音频”的批量推理,进一步提升性能。
,时长00:59
创建一个新的conda环境并安装所需的包:
conda create -n omni python=3.10
conda activate omni
git clone https://github.com/gpt-omni/mini-omni.git
cd mini-omni
pip install -r requirements.txt
交互式演示
conda activate omni
cd mini-omni
python3 server.py --ip '0.0.0.0' --port 60808
注意:你需要本地运行 Streamlit 并安装 PyAudio。
pip install PyAudio==0.2.14
API_URL=http://0.0.0.0:60808/chat streamlit run webui/omni_streamlit.py
API_URL=http://0.0.0.0:60808/chat python3 webui/omni_gradio.py
示例:
注意:Gradio 似乎无法立即播放音频流,因此延迟感会稍强。
,时长00:28
本地测试
conda activate omni
cd mini-omni
# 测试运行预设的音频样本和问题
python inference.py
- Qwen2[1] 作为 LLM 主干。
- litGPT[2] 用于训练和推理。
- whisper[3] 用于音频编码。
- snac[4] 用于音频解码。
- CosyVoice[5] 用于生成合成语音。
- OpenOrca[6] 和 MOSS[7] 用于对齐。
参考链接
[1]
Qwen2: https://github.com/QwenLM/Qwen2/
[2]
litGPT: https://github.com/Lightning-AI/litgpt/
[3]
whisper: https://github.com/openai/whisper/
[4]
snac: https://github.com/hubertsiuzdak/snac/
[5]
CosyVoice: https://github.com/FunAudioLLM/CosyVoice
[6]
OpenOrca: https://huggingface.co/datasets/Open-Orca/OpenOrca
[7]
MOSS: https://github.com/OpenMOSS/MOSS/tree/main
👇
👇
👇
👇
本文同步自于知识星球《AGI Hunt》