我每天有大量的信息要处理,我收藏的信息也越来越多。仅这三年,电子书一本一本下载了近5000本(看过的可能不超过500本),印象笔记里剪藏的文章已经攒到了 19815 篇。因此,我每天要阅读大量文章:电子书里摘的、微信群里发的、邮箱里订的、百度搜的…
但我并不会为此感到焦虑,这些文档资料已经交由我的“私人AI顾问”去阅读学习了。当我需要的时候,我只需要问它就可以了。

在没有 AI 之前,我的文章处理步骤是这样的:
1.一篇篇快速浏览,筛选信息
2.集合筛选过的信息,详细突击阅读其中内容
3.整理摘抄读过后认为重要的观点、论证、金句、笔记
4.不断重复……
有了大语言模型(LLM) 以后,AI可以帮助我处理这海量的文档,提高筛选文章和阅读文档的效率。
下面我将介绍我使用 AI 来帮助我提高文档阅读效率的方法。
我称之为「AI超级阅读法」
一开始,我选择大模型工具是 Kimi Chat
1.第一免费使用,支持 Web、H5、APP、微信小程序等多终端,方便使用。
2.对比海外大模型,如 Claude、ChatGPT ,Kimi Chat 中文支持更好。
3.对比国内大模型,Kimichat 的长文本能力最强,内测支持200万字上下文输入了。
后来,我在自己笔记本电脑上用“Ollama+AnythingLLM”搭建了一个本地化的大模型知识库,和自己的知识库交互,信息安全,内容可靠,不用上网,无限使用。
第一步,我们可以将相关电子文档整理出来(比如将印象笔记导出为一个文件),上传到 AnythingLLM(或kimichat,以下皆可),让大模型帮我们读一遍,分析文档信息。
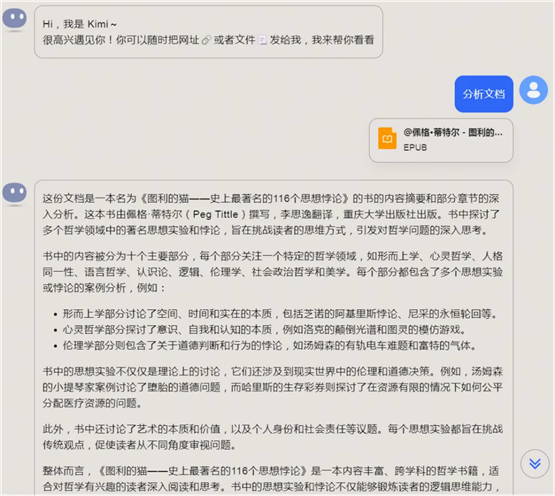
在第一步的 prompt 里,为了更好地了解内容,我让 大模型帮我总结了书籍的元数据,包括标题、作者和标签;一句话总结内容,再写了摘要,我只要阅读这部分,就可以大概知道文档讲的是什么。详细列举书籍的大纲,通过大纲的阅读,就可以知道书籍的结构。
使用以下 prompt 发给 AnythingLLM
让我们一步一步思考,阅读我提供的内容,并做出以下操作:
第一步,提取文档的元数据
(阅读文章内容后给文章打上标签,标签通常是领域、学科或专有名词)
第二步、一句话总结这份文档;
第三步,总结内容并写成摘要;
第四步,越详细地列举文档的大纲,越详细越好;
得到结果:
第二步 详读文档
在阅读了第一步的结果的基础上,紧接着继续追问
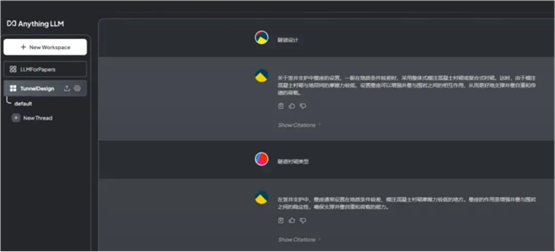
第二步骤里,我还是让大模型帮我:
1.详细总结文档每一部分的内容
2.总结文档的结论
3.告诉我阅读这篇文档我可以学到什么?
提供阅读文档的过程中,读者可能会有的疑问。
帮助我更好地进行第三步的进阶阅读。
总结得不错,
第一步,请详细叙述大纲中每一部分的内容,
第二步,总结文档的结论;
第三步,列举读这篇文档,我可以学到哪些知识?
第四步,针对文档的内容,提出三个用户在阅读的过程中可能会有的疑问。
因为在上下文有”大纲“的情况下,LLM 可以更好地理解工作,总结效果更好。所以我特地将列举大纲和总结详细内容分为了两步。
第三步 个性化进阶阅读
有了前面的内容在了解文档的详细信息后,我们对文档内容有了基本的了解。而接着就是对文档内容的进一步理解,这一步是非常个性化的,你可以根据你的需要,向 大模型发出指令。
下面是我提供的5个步骤,基本上可以解决大部分阅读问题:
01 分析文档内容与结构,提取文章大意和写推荐语
分析文档内容与结构,提取文章大意和写推荐语。提取金句和写推荐语,方便向朋友们推荐文档。
02一句话快速获取文中最独特的知识
看文章的时候,我们通常会学到一些大家都知道的“常识”。但更厉害的是,有时候我们还能从文章里读到作者独到的见解,那些跟“常识”不一样的观点。这就像是捡到了宝,因为这些“反常识”的东西,往往都是作者亲身体验后总结出来的。而我们呢,只需要读读文章,就能学到别人的经验,多划算啊!更妙的是,这些独到的见解经常能和我们已经知道的知识碰撞出火花,让我们有更多的想法。
03 更进一步,这个知识、见解、证据在文中的原文是什么?
如果你对总结里的某个知识点、见解、案例挺感兴趣的,想了解一下原文是怎么描述的,你可以自己读读原文。不过,如果你觉得这样太麻烦,也可以告诉大模型,让它帮你把文档中那个观点的原话找出来,这样你就不用费心去找了。
04 辅导阅读,对不懂的部分、高深专业名词进行追问
如果你在阅读文档时遇到了困惑,比如看《图利的猫——史上最著名的116个思想悖论》这本书的总结时,感觉有些部分不太对劲,那就不要犹豫,直接问大模型:“喂,这里是不是哪里出了问题啊?”
如果遇到一些不熟悉的名词,也可以随时向大模型请教:“嘿,这个词是什么意思啊?”建议直接把名词放到问题里,让大模型来解释一下。
05 还不懂,可要求改写,用高中生可以听懂的语言解释
当你还是读得一头雾水,感觉作者的文字像是来自外太空,完全不知道他在说啥时,怎么办?别担心,我有个超赞的小技巧分享给你!试试这样告诉大模型:“嘿,能不能用高中生都能懂的话给我解释下这个XXX?”这样一来,大模型就会用简单明了的方式给你提示,让你秒懂!当然啦,这个“高中生”只是个比喻,如果你觉得内容太简单或太复杂,也可以换成“大学生”或“小学生”。不过通常来说,“高中生”是个不错的平衡点,既不会过于简单,也不会让你感到压力山大。
完成这5个步骤后,文档的内容基本上就了解得七七八八,你还发现了好多相关的有趣内容。不过,如果你觉得还是有些地方没太懂,那就再去原文里找找答案,加深一下理解。
大模型阅读虽然很牛,但也不是完美的。它现在还存在一些问题:
首先,大模型有时候会判断错误。比如,有篇文档里面举了很多错误案例。但大模型可能会误以为这些案例是在支持某个观点,结果总结出来的内容和文档的真实意思完全相反。这就像我们看一个魔术,有时候会被魔术师骗到,大模型也是这样,会被文字骗到。
其次,不同的大模型在总结同样的东西时,可能会给出不同的答案。这就像我们问不同的人同一个问题,他们可能会给出不同的答案一样。不过,随着大模型越来越聪明,这种问题应该会越来越少。
还有,大模型在处理一些不那么正式的文字时,比如访谈、会议记录之类的,可能会有点吃力。因为这些文字比较随意,没有固定的格式,所以大模型在理解和总结时可能会有点困难。为了解决这个问题,我们可能需要找一些特别的方法或技巧来帮助大模型更好地处理这类文字。
总的来说,虽然大模型阅读还有一些不足,但它的潜力是巨大的。随着技术的进步,这些问题应该会慢慢得到解决,让我们期待大模型阅读在未来的表现吧!
总结
在此文中,我分享了我的个人经验与具体操作流程,为各位提供了一种新的阅读方法——“AI超级阅读法”。通过运用AnythingLLM工具,结合“AI超级阅读法”,能有效提升了阅读的效率。
在数字化时代,阅读大量文档已成为我们日常工作和学习中不可或缺的一部分。然而,随着信息量的爆炸式增长,传统的文档阅读方法已难以满足高效处理大量文档的需求。
第一步:大模型的文档预处理。用强大的AI大模型,我们可以将文档阅读提升到一个全新的水平。在这一步中,我们将文档输入给大模型,让其进行深度解析。大模型能够迅速提取文档的元数据,如作者、日期、关键词等;同时,它还能生成一句话总结,快速把握文档的核心内容。此外,大模型还能为我们撰写摘要,并列举出文档的大纲,帮助我们更好地理解和梳理文档结构。
第二步:大模型的文档深度解析。在第一步的基础上,我们将进一步利用大模型进行文档的深度解析。大模型能够详细总结文档内容,提炼出关键信息,并为我们总结结论。此外,它还能列举出从文档中学到的知识点,帮助我们更好地吸收和记忆。更重要的是,大模型还能提出可能的疑问,引导我们深入思考,挖掘文档中的更多价值。
第三步:个性化的进阶阅读。在完成了前两步的文档处理后,我们已经对文档有了较为全面的了解。然而,每个人的需求和关注点都有所不同。因此,在第三步中,我们将根据个人需要,向大模型发出指令,进行个性化的进阶阅读。例如,我们可以追问不懂的问题,让大模型为我们提供详细的解答;我们还可以要求大模型解释专有名词,帮助我们更好地理解文档中的专业术语;此外,大模型还能简化复杂概念,使其更易于理解和消化。
尽管AI大模型在阅读过程中存在一些局限性,如理解偏差、信息遗漏等问题,但随着技术的不断进步和模型的持续优化,这些问题有望得到解决。随着AI技术的不断发展,我们可以期待一个更加智能、高效的文档处理时代。
“AI超级阅读法”为我们提供了一种全新的文档处理方法,极大地提高了处理和阅读大量文档的效率。通过大模型的预处理、深度解析以及个性化的进阶阅读,我们可以更加高效、深入地理解和利用文档信息。在未来的日子里,让我们携手共进,共同探索AI技术在文档处理领域的更多可能性。
出自:https://mp.weixin.qq.com/s/tAdI1alY7PxKIz0tfpGggg