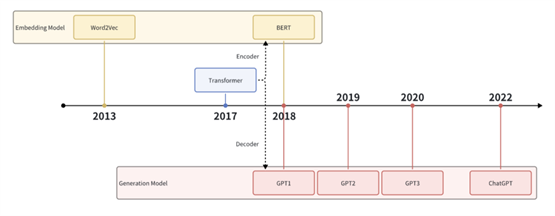
今天我们继续剖析 RAG,将为大家详细介绍 RAG 背后的例如 Embedding、Transformer、BERT、LLM 等技术的发展历程和基本原理,以及它们是如何应用的。
01.
什么是
Embedding?
Embedding 是将离散的非结构化数据转换为连续的向量表示的技术。
在自然语言处理中,Embedding
常常用于将文本数据中的单词、句子或文档映射为固定长度的实数向量,使得文本数据能够在计算机中被更好地处理和理解。通过 Embedding,每个单词或句子都可以用一个实数向量来表示,这个向量中包含了该单词或句子的语义信息。这样,相似的单词或句子就会在嵌入空间中被映射为相近的向量,具有相似语义的词语或句子在向量空间上的距离也会较近。这使得在进行自然语言处理任务时,可以通过计算向量之间的距离或相似度来进行词语或句子的匹配、分类、聚类等操作。

§
Word2Vec
§
Word2Vec 是 2013 年由谷歌提出了一套词嵌入方法。Word2vec 是 Word Embedding 方式之一,这种方式在 2018 年之前比较主流。Word2Vec 作为词向量的经典算法之一,被广泛应用于各种自然语言处理任务。它通过训练语料库来学习单词之间的语义和语法关系,将单词映射到高维空间中的稠密向量。Word2Vec 的问世开创了将单词转化为向量表示的先河,极大地促进了自然语言处理领域的发展。
Word2vec 模型可用来映射每个词到一个向量,可用来表示词对词之间的关系。下图是展示一个
2 维的向量空间的例子(实际可能是比较高的维度)。
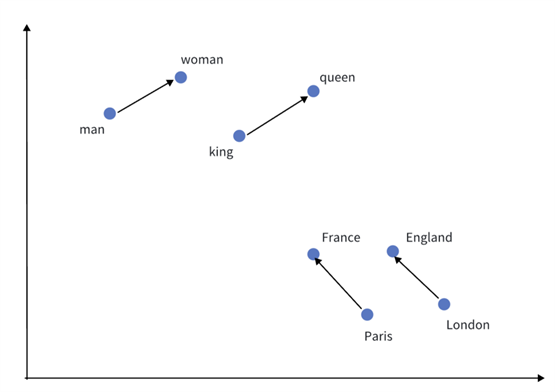
从图中可以看到,在这个 2 维空间内,每个 word 的分布有明显的特征。比如从 man到 woman,要加上一个向右上方向的向量,可以认为这个向量是一种“把男性转换到女性的向量”。如果把 king 也加上这个向量,可以得到 queen 的位置。在图中可以看到从 Paris 到 France 也有一种像是“从国家变为首都”的结构向量。
这一神奇的现象表明了向量在 embedding 内空间并不一是个杂乱无章随意的分布。在哪个区域表示哪些类别,区域和区域之间的差异,这些都有明显的特征。这样可以推出一个结论:向量的相似度代表的就是原始数据的相似度。所以向量的搜索实际上代表的就是原始数据的语义搜索。这样,我们就可以用向量搜索来实现很多语义相似搜索的业务。
然而,作为一种早期的技术,Word2Vec 也存在一定的局限性:
由于词和向量是一对一的关系,所以多义词的问题无法解决。比如下面这几个例子的 bank 就不全是同样一个意思。
...very useful to protect banks or slopes from being washed away by river or rain...
...the location because it was high, about 100 feet above the bank of the river...
...The bank has plans to branch throughout the country...
...They throttled the watchman and robbed the bank...
Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化。
§
Transformer 的变革
§
虽然
Word2Vec 在词向量的表示上有不错效果,但它并没有捕捉到上下文之间的复杂关系。为了更好地处理上下文依赖和语义理解,Transformer 模型应运而生。
Transformer 是一种基于自注意力机制(self-attention)的神经网络模型,最早在 2017 年由 Google 的研究员提出并应用于自然语言处理任务。它能够对输入句子中不同位置的单词关系进行建模,从而更好地捕捉上下文信息。Transformer 的提出标志着神经网络模型在自然语言处理领域的一次重大革新,使得文本生成、机器翻译等任务取得了显著的性能提升。
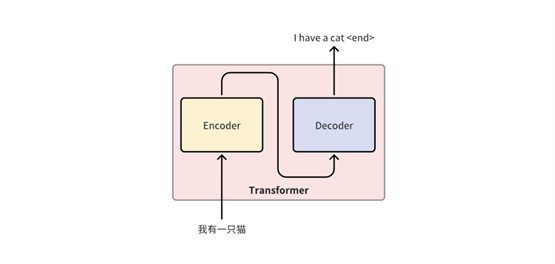
最初,Transformer
被提出来用于机器翻译任务,并取得了显著的性能提升。这个模型由“编码器(Encoder)”和“解码器(Decoder)”组成,其中编码器将输入语言序列编码为一系列隐藏表示,解码器则将这些隐藏表示解码为目标语言序列。每个编码器和解码器由多层自注意力机制和前馈神经网络组成。
Transformer 与传统的 CNN(卷积神经网络)和 RNN(循环神经网络)相比,Transformer 可以实现更高效的并行计算,因为自注意力机制使得所有位置的输入都可以同时计算,而 CNN 和 RNN 需要按顺序进行计算。传统的 CNN 和 RNN 在处理长距离依赖关系时会遇到困难,而 Transformer 通过使用自注意力机制可以学习长距离的依赖关系。
由于原始
Transformer 模型在大规模任务上表现出色,研究人员开始尝试调整模型的大小以提高性能。他们发现,在增加模型的深度、宽度和参数数量的同时,Transformer 可以更好地捕捉输入序列之间的关系和规律。
Transformer 的另一个重要发展是大规模预训练模型的出现。通过在大量的无监督数据上训练,预训练模型可以学习到更丰富的语义和语法特征,并在下游任务上进行微调。这些预训练模型包括 BERT(Bidirectional Encoder Representations
from Transformers)、GPT(Generative
Pre-trained Transformer)等,它们在自然语言处理的各个任务上都取得了巨大的成功。
Transformer 的发展给人工智能带来了巨大的变革,比如 encoder 部分发展为 BERT 系列,随后发展成各类 Embedding 模型。而 decoder 部分发展为 GPT 系列,从而引发了后面 LLM 的革命,包括现在 ChatGPT。
§
BERT 和 sentence embedding
§
Transformer 的 Encoder 部分发展为 BERT。
BERT 使用了两个阶段的预训练方法,即 MLM(Masked Language
Model) 完型填空和 NSP(Next Sentence Prediction)。MLM 阶段让 BERT 预测被遮挡词汇,以帮助它理解整个序列的上下文;NSP 阶段让 BERT 判断两个句子是否是连续的,以帮助它理解句子之间的关系。这两个阶段的预训练使得 BERT 具备了强大的语义信息学习能力,并能够在各种自然语言处理任务中取得优秀性能。
BERT 的一个非常重要的应用就是句子嵌入,即通过一句话生成 embedding 向量。这个向量可以用于多种下游自然语言处理任务,如句子相似度计算、文本分类、情感分析等。通过使用句子嵌入,可以将句子转换为高维空间中的向量表示,从而实现了计算机对句子的理解和语义表达。
相比传统的基于词嵌入的方法,BERT 的句子嵌入能够捕捉到更多的语义信息和句子级别的关系。通过将整个句子作为输入,模型能够综合考虑句子内部词汇的上下文关系,以及句子之间的语义相关性。这为解决一系列自然语言处理任务提供了更为强大和灵活的工具。
§
为什么
Embedding 搜索比基于词频搜索效果好?
§
基于词频搜索的传统算法包括如 TF-IDF、BM25。词频搜索只考虑了词语在文本中的频率,而忽略了词语之间的语义关系。而 Embedding 搜索通过将每个词语映射到一个向量空间中的向量表示,可以捕捉到词语之间的语义关系。因此,当搜索时,可以通过计算词语之间的相似度来更准确地匹配相关的文本。
词频搜索只能进行精确匹配,对于近义词或者语义关联词的搜索效果较差。而 Embedding 搜索可以通过计算词语之间的相似度,实现对近义词和语义关联词的模糊匹配,从而提高了搜索的覆盖范围和准确性。Embedding 搜索能够更好地利用词语之间的语义关系,提高搜索结果的准确性和覆盖范围,相对于基于词频搜索,具有更好的效果。
使用基于词频的搜索方法,如果我们查询"cat",那么结果中可能会将包含"cat"词频较高的文章排在前面。但是这种方法无法考虑到"cat"与其他动物的语义关系,比如与"British
Shorthair(英国短毛猫)"、"Ragdoll(布偶猫)"等相似的动物。而使用 Embedding 搜索方法,可以将单词映射到高维空间中的向量,使得语义相似的单词在空间中距离较近。当我们查询"cat"时,Embedding 搜索可以找到与"cat"语义相似的单词,如"British
Shorthair"、"Ragdoll"等,并将这些相关文章排在结果的前面。这样就能提供更准确、相关性更高的搜索结果。
02.
LLM 的发展
目前,大多数大型语言模型(LLMs)都是基于 “仅解码器”(decoder-only)的 Transformer 架构的衍生版本,比如GPT。相比于 BERT 这种只用
Transformer 的 encoder 的结构,LLM 这种只用 decoder 的结构可以用于生成具有一定上下文语义的文本。
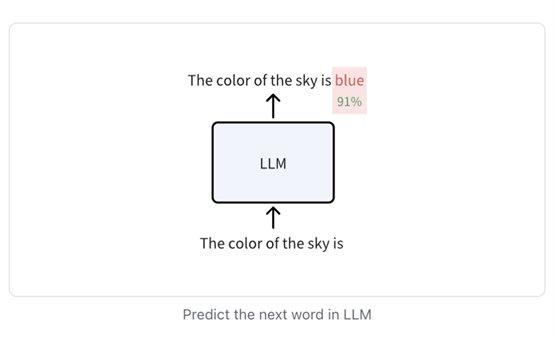
Language Model 的训练任务是基于历史上下文来预测下一个词的出现概率。通过不断循环预测和添加下一个词,模型可以获得更准确、流畅的预测结果。这样的训练过程可以帮助语言模型更好地理解语言规律和上下文信息,从而提高其自然语言处理的能力。
§
从 GPT-1 到 GPT-3
§
§
GPT 系列是由 OpenAI 从
2018 年以来,持续迭代和改进的 LLM 模型。
最早的 GPT-1
在生成长文本时容易出现语义上的不连贯或重复的问题。GPT-2 是于 2019 年发布的改进版本,在GPT-1 的基础上进行了多项改进,包括使用更大规模的训练数据、更深层的模型结构,以及更多的训练迭代次数。GPT-2 在生成文本的质量和连贯性方面有了显著提升,并且引入了零样本学习(zero-shot
learning)的能力,可以对未曾见过的任务进行推理和生成文本。GPT-3 则是在GPT-2 的基础上进一步增强并扩展了模型规模和能力。GPT-3 模型拥有1750亿个参数,它具备了强大的生成能力,可以生成更长、更具逻辑性和一致性的文本。GPT-3
还引入了更多的语境理解和推理能力,可以对问题进行更加深入的分析,并能够提供更准确的答案。

从 GPT-1 到 GPT-3,OpenAI 的语言生成模型在数据规模、模型结构和训练技术上都有了重大的改进和提升,从而实现了更高质量、更具逻辑性和一致性的文本生成能力。发展到 GPT-3 时,已经显现出了一些和以往 LLMs 不同的效果,GPT-3 主要有下面这些能力:
语言续写:给定一个提示词(prompt),GPT-3 可以生成补全提示词的句子。
上下文学习
(in-context learning): 遵循给定任务的几个示例,GPT-3 可以参考它们,并为新的用例生成类似的解答。一般也可以称作 few-shot learning。
世界知识:包括事实性知识 (factual knowledge) 和常识 (commonsense)。
§
ChatGPT
§
2022年11月,OpenAI 发布 ChatGPT,这是一个可以为你回答几乎任何问题的你聊天机器人。它的效果出奇的好,你可以让他帮你总结文档,翻译,写代码,写任何文案。搭配上一些 Tools,你甚至可以让它帮你点外卖,订机票,帮助接管你的电脑,完成各种你之前无法想象的事情。
这强大的功能背后,是从人类反馈中强化学习(Reinforcement Learning from Human Feedback,RLHF)等技术的支持,通过这些技术使得它和人类的对话更让人满意。RLHF是一种通过人类反馈来强化学习的方法,旨在使模型的输出与人类的偏好相一致。具体操作流程包括:模型根据给定的提示生成多个潜在答案,人类评估者对这些答案进行排序,然后使用这些排序结果来训练一个偏好模型,该模型学习如何给出反映人类对答案偏好程度的评分,最后,利用偏好模型对语言模型进行进一步微调。所以这也是为什么你觉得 ChatGPT 这么好用的原因。相比于 GPT-3,ChatGPT 更进一步,解锁了强大的能力:
o
响应人类指令:GPT-3
的输出一般是接着提示词往下说,如果提示词是一个指令,GPT-3可能会续写更多的指令,而ChatGPT则能够很好地回答这些指令。
o
o
o
代码生成和代码理解:模型使用大量的代码训练过,因此可以使用ChatGPT来生成高质量,可运行的代码。
o
o
o
利用思维链
(chain-of-thought) 进行复杂推理:初代 GPT-3 的模型思维链推理的能力很弱甚至没有。这一能力,使得上层应用可以通过提示词工程使ChatGPT更加强大和准确。
o
o
o
详尽的回答:ChatGPT
的回应一般都很详细,以至于用户必须明确要求“用一句话回答我”,才能得到更加简洁的回答。
o
o
o
公正的回答:ChatGPT
通常对涉及多方利益给出非常平衡的回答,尽可能让所有人满意。同时也会拒绝回答不当问题。
o
o
o
拒绝其知识范围之外的问题:例如,拒绝在 2021 年 6 月之后发生的新事件,因为它没在这之后的数据上训练过。或者是拒绝回答一些它训练数据从没见过的数据。
o
然而,ChatGPT
目前也存在一些不足:
o
数学能力相对较差:ChatGPT
的数学能力相对较差。它在解决复杂的数学问题或者涉及高级数学概念的情况下,可能会表现出困惑或者给出不准确的答案。
o
o
o
有时会产生幻觉:有时 ChatGPT 会产生幻觉。它在回答与现实世界相关的问题时,有时会提供虚假或不准确的信息。这可能是因为模型在训练数据中遇到了不准确或误导性的例子,从而导致它对某些问题的回答产生偏差。
o
o
o
无法实时更新知识:ChatGPT
无法实时更新知识。它无法像人类一样通过持续学习来更新和获得最新的知识。这限制了其应用于那些需要及时更新信息的领域,例如新闻报道或金融市场分析。
o
好在,我们可以使用
Retrieval Augmented Generation (RAG) 技术解决产生幻觉,和无法实时更新知识这两点不足。RAG 是结合向量数据库和 LLM 的一项技术应用,关于 RAG 的介绍以及优化技巧,可以参考其它的文章。
03.
总结
在这篇文章中,我们从 Embedding 出发,介绍了 Deep Learning 尤其是 NLP 领域目前主流的模型和应用。从早期的 Word Embedding,到现在 ChatGPT 的火热,AI 的发展正在越来越快。随着技术的不断进步和数据的丰富,我们可以期待更加强大的模型的出现。深度学习的应用将更加广泛,不仅仅局限于自然语言处理领域,而是覆盖到更多的领域,如视觉、语音等。相信随着技术的不断突破和社会的发展,会看到未来更多令人振奋的进展和创新。
出自:https://mp.weixin.qq.com/s/s7H_0nzCw57-FY0yUnCXjQ