项目简介
RAGFlow是一个开源的RAG引擎,专注于深入的文档理解。该项目提供了一个简化的RAG工作流,适用于各种规模的企业,通过结合使用大型语言模型(LLM)来提供基于严谨引用的真实问答能力。支持处理各种复杂格式的非结构化数据,包括文本、图片、扫描副本、结构化数据和网页等。
此外,RAGFlow还具备自动化和易于配置的特点,能够与商业系统无缝集成,提高数据处理和分析的效率。
主要特点
·基于深度文档理解的非结构化数据知识提取,处理复杂格式数据。
·在包含无限符号的数据“干草堆”中寻找“针”。
·智能化且可解释性强。
·提供众多模板选项。
·可视化文本分块,支持人工干预。
·快速查看关键参考资料和可追踪引用以支持有根据的回答。
·支持Word、幻灯片、Excel、txt、图片、扫描副本、结构化数据、网页等。
·为个人和大型企业量身定制的RAG流程管理。
·可配置的大型语言模型和嵌入模型。
·多重召回配合融合重排。
·直观的API,便于与商业系统无缝集成。
系统架构
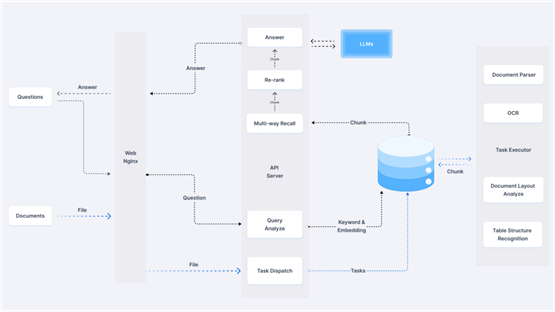
使用
先决条件
·CPU >= 2 核
·内存 >= 8 GB
·Docker >= 24.0.0 & Docker Compose
>= v2.26.1
1.要确保 vm.max_map_count 的值至少为 262144,你可以按照以下步骤操作:
·检查当前值:在终端运行 sysctl vm.max_map_count 来查看当前设置。
·
$ sysctl vm.max_map_count
·重置值:如果值低于 262144,运行 sudo
sysctl -w vm.max_map_count=262144 来临时更改它。
·
·
# In this case, we set it to 262144:
$ sudo sysctl -w vm.max_map_count=262144
·永久设置:为了确保重启后设置不变,需要将 vm.max_map_count=262144 添加到 /etc/sysctl.conf 文件中。
·
vm.max_map_count=262144
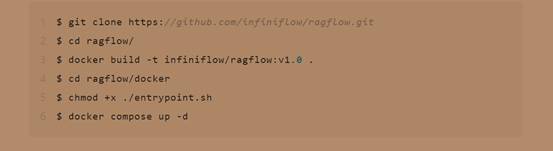
2.克隆所需的存储库
·
$ git clone https://github.com/infiniflow/ragflow.git
3.构建预构建的Docker镜像,并启动服务器
·
·
·
$ cd ragflow/docker
$ chmod +x ./entrypoint.sh
$ docker compose up -d
核心映像大小约为 9 GB,可能需要一段时间才能加载。
4.动后,检查服务器状态以确认系统已成功启动。
以下输出确认系统已成功启动
·
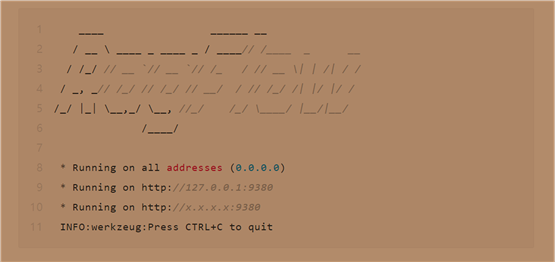
5.在你的网络浏览器中,输入你的服务器 IP 地址并登录到 RAGFlow。
在给定场景中,你只需输入 http://IP_OF_YOUR_MACHINE(无需端口号)即可,因为使用默认配置时可以省略默认的 HTTP 服务端口 80。
6.在 service_conf.yaml 中,选择所需的 LLM 工厂在 user_default_llm 中,并用相应的 API 密钥更新 API_KEY 字段。
配置
1.在处理系统配置时,您需要管理以下文件:
·.env:存储系统的基本设置,如
SVR_HTTP_PORT、MYSQL_PASSWORD 和 MINIO_PASSWORD。
·service_conf.yaml:配置后端服务。
·docker-compose.yml:系统依赖此文件启动。
2.必须确保 .env 文件中的更改与 service_conf.yaml 文件中的设置相符。
./docker/README
文件详细描述了环境设置和服务配置,您需要确保所有在 ./docker/README 文件中列出的环境设置与 service_conf.yaml 文件中的相应配置保持一致。
3.若需更新默认的 HTTP 服务端口(80),请在 docker-compose.yml 中将
80:80 更改为:80。
所有系统配置的更新都需要重启系统才能生效。
·
$ docker-compose up -d
从源代码构建
从源代码构建 Docker 镜像:
·
出自:https://mp.weixin.qq.com/s/750NEL_deXIporX4GN-OFA