RAG 2.0,终于把RAG做对了!
原文链接:https://pub.towardsai.net/rag-2-0-finally-getting-rag-right-f74d0194a720
 在审视人工智能行业时,我们已习惯了每天看到事物被“杀死”。我自己有时在不得不第23923次谈论某事物突然被“杀死”时也会感到不安。
在审视人工智能行业时,我们已习惯了每天看到事物被“杀死”。我自己有时在不得不第23923次谈论某事物突然被“杀死”时也会感到不安。
着眼于人工智能行业,我们已习惯了每天看到各种事物被“淘汰”。有时候,当我不得不第23923次谈论某个事物突然被“杀死”时,自己也会感到不寒而栗。
但很少有案例像Contextual.ai提出的基于情境语言模型(CLMs)的“RAG 2.0”那样引人注目,它旨在使标准检索增强生成(RAG)——目前最流行(如果不是最受欢迎的话)的生成式AI模型实现方式之一——变得过时。提出这一主张的正是RAG的最初创造者。
尽管这是对生产级生成式AI现状的重大改进,但整个子领域仍存在一个疑问:RAG是否正在倒数其最后的日子,这些创新是否只是在对一匹死马进行鞭打?
立足于数据
如您所知或未知,所有独立的大规模语言模型(LLMs),以ChatGPT等突出示例为代表,都有知识截止日期。
这意味着预训练是一次性的任务(不同于持续学习方法)。换句话说,LLMs只能“看到”截至某一时间点的数据。例如,撰写本文时,ChatGPT的数据更新至2023年4月。因此,它们无法回答该日期之后发生的事实和事件。
这就是RAG发挥作用的地方。
一切都关乎语义相似性
顾名思义,其理念是从已知数据库中检索数据,这些数据是LLM很可能从未见过的,并实时将其输入模型中,使其具备最新且重要的是语义相关的上下文,以便提供准确的答案。
那么,这种检索过程是如何运作的呢?
整个架构基于一个单一原则:有能力检索与请求或提示上下文语义相关、有意义的数据。
但很少有情况像Contextual.ai提出的上下文语言模型(CLMs)那样引人入胜,他们称之为“RAG 2.0”,旨在使标准的检索增强生成(RAG)——如果不是最流行的方式之一——成为过时的实现生成性AI模型的方法。
这一主张背后,正是RAG的最初创造者。
尽管这比生产级生成性AI的现状有了巨大改进,但整个子空间上空仍然悬着一个问题:RAG是否正在度过它的最后日子,而这些创新是否只是在徒劳地打击一匹死马?
基于数据的依据
你可能知道或不知道,所有独立的大型语言模型(LLMs),以ChatGPT等突出的例子为例,都有一个知识截止点。
这意味着预训练是一次性的练习(与持续学习方法不同)。换句话说,LLMs在某个时间点之前已经“见过”数据。
例如,截至撰写本文时,ChatGPT的更新截止到2023年4月。因此,它们没有准备好回答在那之后发生的事实上的事件。
而这正是RAG的用处所在。
一切都是语义相似性
正如其恰当的名称所暗示的,这个想法是从已知数据库中检索数据,这些数据LLM很可能以前从未见过,并实时地将其输入模型,以便它有更新的——并且重要的是,语义上相关的——上下文来提供一个准确的答案。
但这个检索过程是如何工作的呢?
整个架构源于一个单一的原则:检索与请求或提示的上下文语义上有意义的数据的能力。
 Source
Source
注:Source
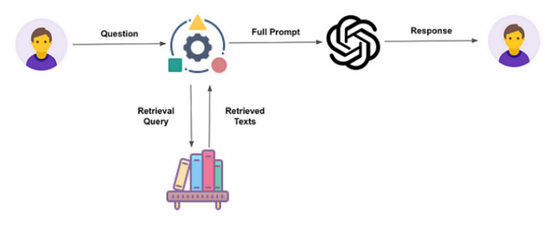
该过程涉及使用三个要素:
1.嵌入模型
2.检索器,通常是一个向量数据库
3.生成器,即LLM
首先,要使检索过程奏效,需要将数据转换为“嵌入形式”,即将文本表示为数值向量的形式。
更重要的是,这些嵌入具有相似性原则:相似的概念会有相似的向量。例如,在我们看来,“狗”和“猫”的概念是相似的:两者都是动物、哺乳类、四足且家养。转化为向量后,“狗”可能是[3, -1, 2],“猫”可能是[2.98, -1, 2.2],可以将每个数字视为该概念的一个“属性”。因此,相似的数字意味着相似的属性。
想要深入了解嵌入是什么,请查阅我的深度解析文章。
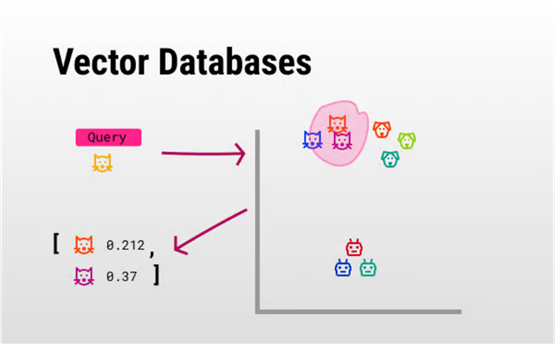
获取到嵌入之后,我们将它们插入向量数据库(即检索器)中,这是一个存储这些嵌入的高维数据库。
应用之前讨论的相似性原则,在这个空间中,相似的事物彼此更接近。
然后,每当用户发送如下所示请求:“给我与‘黄色猫’类似的结果”时,向量数据库就会执行一次“语义查询”。
用通俗的话说,它会提取与用户查询向量距离最近的那些向量。
由于这些向量代表了底层概念,所以相似的向量将代表相似的概念,在本例中就是其他猫。
注:Source
一旦我们提取了内容,我们就构建了大型语言模型(LLM)的提示,包含了:
•用户的请求
•提取的内容
•以及通常,一组系统指令
但什么是系统指令呢?
作为提示工程过程的一部分,你还想调整模型将如何响应。一个典型的系统指令可能是“要简洁”。
这就是RAG(Retrieval-Augmented Generation,检索增强生成)的精髓,一个在推理时提供与用户查询相关的实时内容以增强LLM响应的系统。
RAG系统之所以能够首先工作,是因为LLM的最大超能力:上下文学习,这使得模型能够使用以前未见过的数据,在没有权重训练的情况下进行准确的预测。
让我们深入探讨上下文学习以及LLM如何学习使用它。
但这个过程听起来好得令人难以置信,当然,事情并不像看起来那么惊人。
理解推动前沿AI模型发展的关键直觉是困难的。但它不必如此。
无需精炼的缝合,已成过去
一种可视化当前RAG系统的方法是以下裤形图:
尽管这些裤子可能适合某些观众,但大多数人永远不会穿它们,因为尽管补丁裤最初是为了不引人注意,但它们并没有统一性。
这个类比背后的原因是因为标准的RAG系统组装了三个不同的组件,这些组件是分别预训练的,并且根据定义,它们本来就不应该在一起。
相反,RAG 2.0系统从一开始就被定义为“一体”。#RAG2.0#
这里不允许有弗兰肯斯坦(意指拼凑而成的东西)
在实践中,整个系统是端到端训练的,同时保持连接,就像假设大型语言模型(LLM)应该始终有一个向量数据库与之相连,以保持更新。
与标准的RAG相比,预训练、微调以及从人类反馈中学习强化学习(RLHF),所有这些是标准LLM训练的基本组成部分,都是从头开始执行的,包括大型语言模型和检索器(向量数据库)。
用更专业的术语来说,这意味着在反向传播过程中,用于训练这些模型的算法,梯度不仅通过整个LLM传播,还通过检索器传播,以便整个系统作为一个整体,从训练数据中学习。

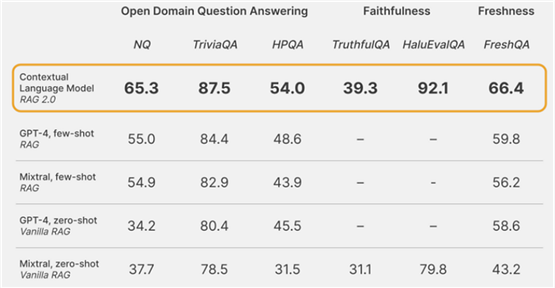
并且结果无疑证明了这一点:
尽管使用的几乎可以保证是一个比GPT-4更差的独立模型,但这种新的方法是在GPT-4和其他检索系统之间所有可能的RAG 1.0组合中表现最好的。
注:Source: Contextual.ai
原因很简单:在RAG
1.0中,我们分别训练各个部分,然后将它们拼接在一起,希望得到最好的结果。但在RAG 2.0中,情况大不相同,因为所有组件从一开始就在一起。
用更专业的术语来说,将两个独立训练的系统拼接在一起是灾难的配方,尤其是如果学习到的表示不平等的情况下。
这类似于一个英国人使用一个日本数据库;上下文是存在的,但它不能被英国人理解。
但即使RAG 2.0的优势很明显,一个重大问题仍然存在。
真正的问题仍未得到解答
尽管由于其设计专门针对不愿与大型语言模型(LLM)提供商共享机密数据的公司,RAG 2.0可能很快就会成为企业标准,但有理由相信,无论哪个版本,RAG最终可能根本不再被需要。
巨大序列长度的到来
我相信你非常清楚,我们今天的前沿模型,比如Gemini 1.5或Claude 3,它们的上下文窗口非常大,在生产发布的模型中可以达到一百万个令牌(75万字),在研究实验室中可以达到一千万个令牌(750万字)。
用外行的话来说,这意味着这些模型可以在每个提示中输入非常长的文本序列。
作为参考,《指环王》系列书籍总共有576,459个单词,而《哈利·波特》整个系列书籍大约有1,084,170个单词。因此,一个750万字的上下文窗口可以在每个提示中五次装下这两个故事。
在那种情况下,我们真的需要一个知识检索知识库,而不是仅仅在每个提示中输入信息吗?
一个可能放弃这个选项的理由可能是准确性。序列越长,模型检索正确上下文的难度应该越大,对吧?
另一方面,与在每个提示中输入整个上下文相比,RAG过程允许只选择语义相关的数据,从而使整个过程更加高效。
然而,正如谷歌所证明的那样,在长序列中准确性并不会受到影响,他们甚至在一千万个令牌长度的上下文中展示了几乎100%的准确性,对于“大海捞针”任务,其中在提示的深处隐藏了一个很小的,有时不相关的事实,以查看模型是否能够正确检索它。
而它确实做到了:
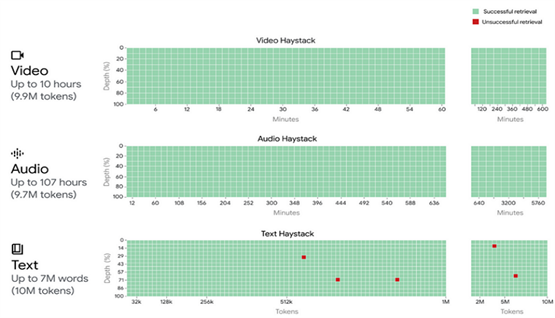
但这是如何做到的呢?
这些模型无论长度如何都能表现出惊人性能的背后的技术支持是,这些模型的基本操作符——注意力机制——具有绝对的全局上下文,因为注意力机制迫使序列中的每一个单独的令牌(也就是一个单词或子词)去关注序列中每一个其他的之前的单词。
这确保了无论依赖关系有多远,无论信号有多小(关键信息可能存储在一个距离数百万单词的单个单词中),模型应该能够——而且确实能够——检测到它。
因此,在我看来,RAG最终是否存活下来不会取决于准确性,而是取决于另一个超越技术的关键因素:
成本。
更好的商业案例,或死亡
今天,由于Transformer无法压缩上下文,更长的序列不仅意味着成本呈二次方增长(序列增加2倍意味着计算量增加4倍,或者序列增加3倍意味着计算成本增加9倍),而且还意味着由于KV缓存大小的增加,内存需求会爆炸性增长。
KV缓存是模型的“缓存内存”,避免不得不重新计算大量冗余的注意力数据,否则这个过程在经济上是不可行的。这里是关于KV缓存是什么以及它如何工作的深入回顾。
简而言之,运行非常长的序列是非常昂贵的,以至于对于具有极长序列长度的模态,如DNA,甚至不考虑使用Transformer。
事实上,在像EVO这样的DNA模型中,研究人员使用了海纳(Hyena)操作符而不是注意力来避免前面提到的二次方关系。海纳操作符使用长卷积而不是注意力来以次二次方的成本捕捉长距离依赖。
但等等,卷积不也是一个二次方操作吗?
是的,但标准卷积的成本确实是二次方的,但通过应用卷积定理,该定理指出两个函数之间的卷积的傅里叶变换是它们各自傅里叶变换的逐点乘积(哈达玛乘积),你可以在次二次方的时间和成本内执行操作,这种操作被称为“快速卷积”。
本质上,虽然你在时间域中计算卷积,但你是作为频率域中的逐点乘积来计算它,这更快、更便宜。
其他替代方案寻求一种混合方法,而不是完全放弃注意力,而是找到注意力和其他操作符之间的最佳平衡点,以在保持性能的同时降低成本。
最近的示例包括Jamba,它巧妙地将Transformer与其他更高效的架构(如Mamba)混合在一起。
Mamba、Hyena、Attention……你可能认为我只是为了证明一个观点而随意列举一些花哨的词汇。
但忘掉这些不同的名字吧,在一天结束时,一切都归结为同一个原则:它们是揭示语言模式的不同方式,帮助我们的AI模型理解文本。
注意力机制驱动了当今99%的模型,其余的只是在尝试找到尽可能最小的性能降低的更便宜的方式,使大型语言模型(LLM)更加经济。
总而言之,我们很快就能看到极长序列的处理成本仅为目前价格的一小部分,这应该会增加对RAG架构需求的怀疑。
当那个时刻到来时,我们可以几乎保证它会发生,我们还会依赖RAG吗?我不知道,但有可能我们目前正在做无用功。
出自:https://mp.weixin.qq.com/s/11gdAT-oDHGtx_TEP5kdCA