引言
紧跟技术发展趋势,快速了解大模型最新动态。终于又有时间更新文章了,今天继续总结最近一周的研究动态,梳理了10篇有关大模型(LLMs)的最新研究进展,其中涉及涉及多模态RAG、推理时对齐、多模态模型、大模型微调、大模型Agent等热门研究。
LMU | 多模态RAG系统

论文:https://arxiv.org/pdf/2410.21943
检索增强生成(RAG)主要解决的是大模型缺乏领域知识且容易产生幻觉的问题。随着当前多模态模型的发展,它可以同时处理文本和图像,「那么能否将多模态模型应用到RAG系统呢?」 基于这个问题,本文重点研究了如何将多模态模型集成到 RAG 系统中,旨在找到多模态RAG系统的最佳配置。
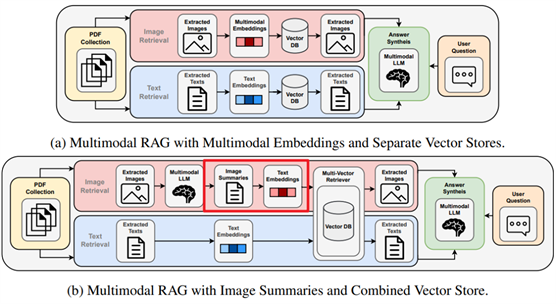
本文作者研究主要关注两个问题:1)基于工业领域中的PDF文档,将单模态文本、单模态图像、文本+图像双模态放入RAG系统中,看一看文本+图像双模态是否能够提升RAG系统的性能?2)如何优化多模态RAG系统?为了回答这两个问题,本文作者首先选择了当前主流的两个多模态模型GPT4-Vision,LLaVA ,然后手动标注了数据集和RAG系统测试集,接着作者构建了一个多模态RAG系统(两种配置),将文本和图像结合到一块。
CMU | 提出推理时对齐方法
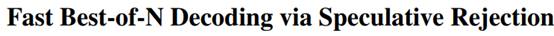
论文:https://arxiv.org/pdf/2410.20290
大模型训练主要包括两个部分,分别为Pre-Training 和 Post-Training。当我们拿到开源大模型的时候,通常会与实际场景结合来对大模型做一波Post-Training,进而改变预训练模型的权重来实现LLM对齐。「那么能否有一种技术来避免Post-Training来实现大模型对齐呢?
答案就是「推理时对齐方法」,称之为:Best-of-N。但是该方法有一个缺点,就是在推理时所需要的资源远远要超过标准解码策略,这不利于实际应用。今天给大家分享的这篇文章就针对这个问题,「提出了一种计算上可行的推理时对齐算法,称为Speculative Rejection,在计算效率上可以高出16至32倍」。
智源|新型扩散模型架构OmniGen

论文:https://arxiv.org/pdf/2409.11340
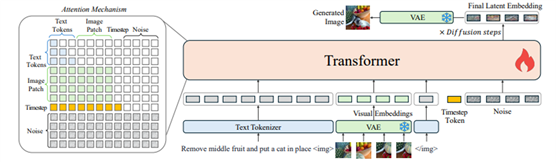
OmniGen具有以下特点:
「统一性:」 OmniGen天然地支持各种图像生成任务,例如文生图、图像编辑、主题驱动生成和视觉条件生成等。此外,OmniGen可以处理经典的计算机视觉任务,将其转换为图像生成任务。
「简单性:」 OmniGen的架构高度简化。此外,与现有模型相比,它更加用户友好,可以通过指令完成复杂的任务,而不需要冗长的处理步骤和额外的模块(如ControlNet或IP-Adapter),从而大大简化了工作流程。
「知识迁移:」 受益于统一格式的学习,OmniGen有效地跨不同任务迁移知识,应对未见过的任务和领域,并展示新颖的功能。研究人员还探讨了模型的推理能力和思维链机制的在图像生成领域的潜在应用。
Salesforce|多模态语言模型:BLIP-3-Video
论文:https://arxiv.org/pdf/2410.16267
本文提出了一个专门处理视频的多模态语言模型:BLIP-3-Video(xGen-MM-Vid),它能有效捕捉视频帧之间的时间信息。
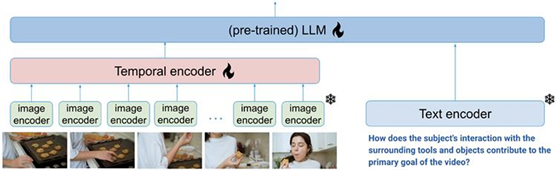
「这个模型除了使用常规的视觉分词器外,还增加了一个“时间编码器”」,可以把多帧视频转换成更少的视觉标记,减少了模型需要处理的标记数量。实验证明,BLIP-3-Video虽然模型更小,但在视频问答的准确率上与更大的模型相当,效率更高。
CMU|多语言多模态:Pangea

论文:https://arxiv.org/pdf/2410.16153
当前大模型主要主要关注英语和西方文化的问题。为此,本文作者训练了一个「多语言多模态大模型:Pangea」,该模型覆盖39种语言的600万指令数据集PangeaIns上进行训练。
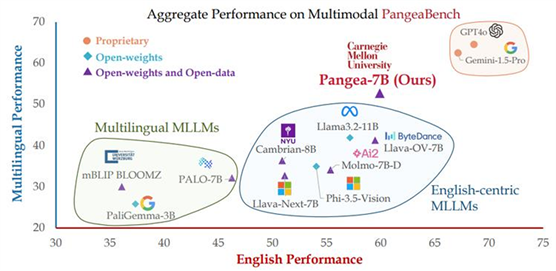
PangeaIns包括高质量的英语指令、机器翻译的指令和与文化相关的多模态任务。研究者还推出了PangeaBench评估套件,包含14个数据集、覆盖47种语言。实验显示,Pangea在多语言和不同文化背景下的表现优于现有开源模型。
斯坦福 | 上下文Scaling Laws
论文:https://arxiv.org/pdf/2410.16531
本文研究了上下文学习(ICL)在不对模型进行微调训练的情况下提高语言模型执行复杂任务的能力,并解释了为何提供的示例越多,模型预测的准确性越高。
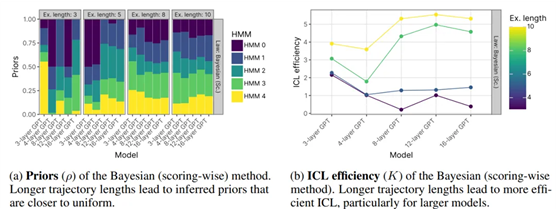
「作者发现ICL类似于贝叶斯学习,并提出了新的贝叶斯法则来描述ICL。实验表明,这些法则能提高模型准确性」,并帮助理解任务特性和学习效率。此外,通过实验,作者发现贝叶斯法则能准确预测ICL如何恢复被抑制的模型能力,这表明仅通过后训练难以提高大型语言模型的安全性。
RAG推理加速
论文:https://arxiv.org/pdf/2409.15355
为了提升RAG系统推理速度,本文作者提出了Block-Attention,该方法将检索到的文档划分为离散的块,每个块独立计算键值(KV)状态,最后一个块除外。在RAG场景中,通过将每个段落定义为一个块,「Block-Attention能够重用之前见过的段落的KV状态,从而显著降低推理时的延迟和计算开销」。
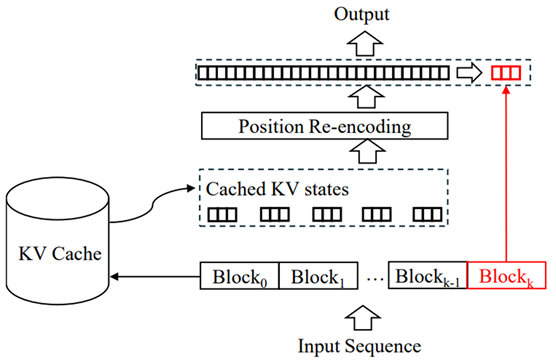
Block-Attention的实现包括块分割、位置重新编码以及对大模型(LLM)的微调,以适应Block-Attention机制。实验结果显示,在四个RAG基准测试中,经过块微调后,Block-Attention模型的性能与自注意力模型相当(Llama3上为68.4%对67.9%),甚至在某些情况下表现更好(Mistral上为62.8%对59.6%)。
可拓展Agent平台AgentStore
论文:https://arxiv.org/pdf/2410.18603
大模型Agent能够自动化复杂计算机任务,但在处理现实任务时泛化和专业化能力不足。为此,本文作者提出了「AgentStore,一个可扩展的平台,能够集成不同代理来自动化计算机任务」。AgentStore支持用户添加第三方代理,使系统功能不断扩展,适应操作系统的变化。
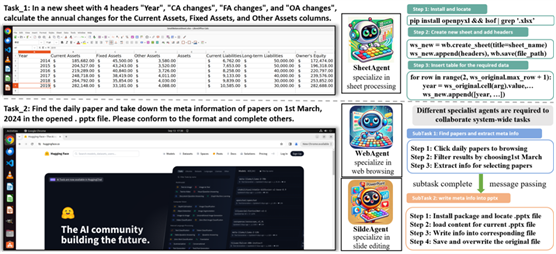
除此之外,作者还设计了一个核心MetaAgent,使用AgentToken策略来管理各种代理,提高它们在特定任务和系统任务中的表现。结果显示,该方法把 OSWorld 刷到了 25%,把
claude 打下来了。
LLM PEFT技术全面介绍

论文:https://arxiv.org/pdf/2403.14608
大模型能力不断增强,同时参数也在不断加大。受限于计算资源,传统的全参数微调方法可能会显得力不从心,因此需要探索更高效的微调策略,此时参数高效微调(PEFT)技术应运而生。PEFT 提供了一个高效的针对预训练模型的下游任务适配手段,其通过固定大部分预训练参数并微调极少数参数,让大模型轻装上阵,迅速适配各种下游任务,让大模型变得不再「巨无霸」。
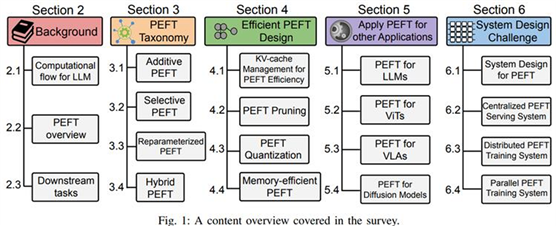
为了全面总结 PEFT 技术的发展历程并及时跟进最新的研究进展,最近,美国东北、加大等整理并「总结了参数高效微调(PEFT)技术在大模型上的应用及其发展前景」,并总结为一篇全面且前沿的综述。「全文长达 24 页」,涵盖了近 250 篇最新文献,在各平台都有着不小的热度。