【TTS语音克隆开源最强王者】5款爆火开源模型(Fish、F5、GPT、CosyVoice、MaskGCT)效果对比,等你来评!
今天给大家同时展示5款(Fish、F5、GPT、CosyVoice、MaskGCT)爆火的语音克隆-文本合成的效果展示。哪款语音克隆模型最好,等你来评价~本文案例效果仅供参考!下面进入今天的主题~
需要特别注意:本文只是技术分享,在使用对应模型进行语音合成时,需要严格遵照对应项目的要求和法律法规!!
- 5款爆火开源TTS语音克隆项目
- GPT-SoVITS模型介绍
- MaskGCT模型介绍
- F5-TTS语音模型介绍
- FishSpeech1.4模型介绍
- CosyVoice模型介绍
- 模型对应的license总结
- 实战篇:部署5款模型进行语音克隆
- GPT-SoVITS模型代码语音克隆-推理部分
- fish-speech1.4模型代码语音克隆
- F5-TTS模型推理部分代码
- Mask-GCT模型推理部分代码
- CosyVoice模型的推理代码
- 效果篇:5款语音克隆模型效果展示
- 案例1: 萝莉语音克隆-5款模型语音克隆--效果展示
- 案例2: 萝莉语音克隆-5款模型语音克隆-带数字文本-效果展示
- 案例3: 萝莉语音克隆-5款模型语音克隆-长文本-效果展示
- 案例4: 中文动漫人物语言克隆-5款模型语音克隆-中英文克隆-效果展示
- 案例5: 中文动漫人物语言克隆-5款模型语音克隆-短文本克隆-效果展示
- 参考链接
5款爆火开源TTS语音克隆项目
GPT-SoVITS模型介绍
 GPT-SoVITS项目是TTS克隆领域内效果常年霸榜的模型之一,具有以下功能:
GPT-SoVITS项目是TTS克隆领域内效果常年霸榜的模型之一,具有以下功能:
- 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
- 少样本 TTS:仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持:支持与训练数据集不同语言的推理,目前支持英语、日语、韩语、粤语和中文。
- WebUI 工具:集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
该文章的目录如下,详情见:【34.8k点赞量!】TTS领域内明星模型GPT-SoVITS实操教程来啦;2秒语音就能克隆,效果过于惊艳,请谨慎使用!
MaskGCT模型介绍
 大型文本到语音(TTS)系统通常被分为自回归和非自回归系统。自回归系统隐式地建模了持续时间,但在鲁棒性方面存在一定的缺陷,并且缺乏持续时间的可控性。非自回归系统在训练期间需要显式的文本和语音之间的对齐信息,并预测语言单位(例如音素)的持续时间,这可能会影响其自然性。在10月24日,趣丸科技&香港中文大学提出一种完全非自回归的TTS模型——掩码生成编解码器变换器(MaskGCT),它消除了对文本和语音监督之间显式对齐信息的需求,以及对音素级别持续时间预测的需求。
大型文本到语音(TTS)系统通常被分为自回归和非自回归系统。自回归系统隐式地建模了持续时间,但在鲁棒性方面存在一定的缺陷,并且缺乏持续时间的可控性。非自回归系统在训练期间需要显式的文本和语音之间的对齐信息,并预测语言单位(例如音素)的持续时间,这可能会影响其自然性。在10月24日,趣丸科技&香港中文大学提出一种完全非自回归的TTS模型——掩码生成编解码器变换器(MaskGCT),它消除了对文本和语音监督之间显式对齐信息的需求,以及对音素级别持续时间预测的需求。
该项目的目录如下,详情见:【又又一款王炸级别TTS模型】趣丸科技&港中大开源MaskGCT语音大模型,性能超过CosyVoice,XTTS-v2!
F5-TTS语音模型介绍
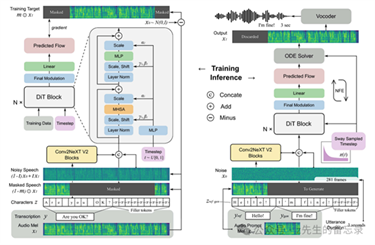 F5-TTS是由上海交通大学(Shanghai Jiao Tong University)、剑桥大学(University
of Cambridge)、以及极氪汽车研究院(Geely Automobile Research
Institute (Ningbo) Company Ltd.)的研究团队联合开发的。具有以下特点:
F5-TTS是由上海交通大学(Shanghai Jiao Tong University)、剑桥大学(University
of Cambridge)、以及极氪汽车研究院(Geely Automobile Research
Institute (Ningbo) Company Ltd.)的研究团队联合开发的。具有以下特点:
- 改进的文本表示:F5-TTS使用ConvNeXt对输入文本进行细化,以改善与语音的对齐,解决了E2-TTS中存在的鲁棒性问题。
- Sway Sampling策略:F5-TTS提出了一种新的推理时采样策略,称为Sway Sampling,它显著提高了模型的性能和效率。这种采样策略可以轻松地应用于现有的基于流匹配的模型,而无需重新训练。
- 更快的训练与推理:F5-TTS的设计允许更快的训练,并且在推理时实现了0.15的实时因子(Real-Time Factor, RTF),与现有的基于扩散的TTS模型相比,这是一个显著的改进。
- 零样本能力:F5-TTS在公共100K小时多语言数据集上训练,展示了高度自然和富有表现力的零样本能力,以及无缝的代码切换能力。
- 开源:F5-TTS的代码和检查点被开源,以促进社区发展。
该项目的目录如下,详情见文章:【克隆TTS领域又更新啦】上海交大开源F5-TTS: 只需要2秒就能克隆语音,可商用,合成语音效果让我震惊不已!
FishSpeech1.4模型介绍
 fish.audio团队最新开源的FishSpeech1.4;支持中文、英文等8种语音,具有以下特点:
fish.audio团队最新开源的FishSpeech1.4;支持中文、英文等8种语音,具有以下特点:
- 零样本和少样本文本转语音(TTS):输入一个10到30秒的语音样本,即可生成高质量的TTS输出。有关详细指南,请参见语音克隆最佳实践。
- 多语言和跨语言支持:只需将多语言文本复制粘贴到输入框中——无需担心语言问题。目前支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
- 无需音素依赖:该模型具有强大的泛化能力,不依赖于音素进行TTS。它可以处理任何语言脚本的文本。
- 高度准确:对于5分钟的英文文本,实现了约2%的低CER(字符错误率)和WER(词错误率)。
- 快速:借助fish-tech加速技术,在Nvidia RTX 4060笔记本电脑上实时因子约为1:5,在Nvidia RTX 4090上为1:15。
- WebUI推理:功能强大,基于Gradio的Web UI,兼容Chrome、Firefox、Edge等浏览器。
- GUI推理:提供与API服务器无缝协作的PyQt6图形界面。支持Linux、Windows和macOS。见GUI。
- 部署友好:可以轻松设置推理服务器,原生支持Linux、Windows和MacOS,最小化速度损失。该文章的目录如下,详情见文章:【又一款王炸级别语音克隆TTS模型】FishSpeech重磅开源1.4版本!语音合成更逼真!跟最近爆火F5-TTS相比如何呢?

CosyVoice模型介绍
CosyVoice是一个语音生成模型,能够合成自然声音,适用于多种应用。模型支持五种语言:中文、英语、日语、粤语和韩语。CosyVoice 包含三个开源模型:
- CosyVoice-base-300M:擅长准确代表说话者身份,无需微调即可适应不同上下文,能够跨语言克隆声音。
- CosyVoice-300M-25Hz、CosyVoice-300M-SFT:能够生成富有情感表现力的语音,允许通过指令文本进行精细调整。
- CosyVoice-300M-SFT:已针对七位多语言说话者进行了微调,适合立即部署使用。
语音合成模型 CosyVoice 功能特点:
- 多语言支持:CosyVoice 支持包括中文、英文、日语、粤语和韩语在内的五种语言。
- 零样本学习:能够无需训练即可适应新说话者(zero-shot
in-context learning),能够在不同语言之间复制声音。
- 情感共鸣:能够创建情感共鸣的声音,
CosyVoice-instruct 版本通过情感指令显著提高了情感控制的准确性。
- 高质量语音合成:生成的样本在词错误率(WER)和说话者相似性方面达到人类水平。
- 语音定制化:能够根据特定说话者生成多语言语音,适应新说话者而无需训练。
- 语音克隆与风格迁移:支持在不同语言之间进行语音克隆和情感风格迁移。
该项目的目录如下,详情见文章:【语音领域-又双叒更新】阿里开源FunAudioLLM: 2大核心模型、5大亮点功能!效果炸裂!手把手带你理论+实战部署推理!
模型对应的license总结
- CosyVoice模型: Apache-2.0 license
- GPT-SoVITS模型: MIT license
- F5-TTS模型:源代码是 MIT License,预训练模型是 CC-BY-NC license
- Fish-Speech-1.4模型: 这个模型在BY-CC-NC-SA-4.0 License下获得了宽松的授权。源代码在BSD-3-Clause License
- MASK-GCT模型: 代码Amphion是MIT License, 模型是cc-by-nc-4.0 License
实战篇:部署5款模型进行语音克隆
在本次实验中5款模型的版本参数: GPT-SoVITSV2版本、fish-speech1.4、 F5-TTS、 Mask-GCT、CosyVoice-300M-25Hz;其中核心的代码如下:
GPT-SoVITS模型代码语音克隆-推理部分
%%time
%cd /kaggle/working/GPT-SoVITS
!rm -rf gpt_sovits_output.wav
!python GPT_SoVITS/src.py --gpt_model "GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s1bert25hz-5kh-longer-epoch=12-step=369668.ckpt" \
--sovits_model "GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth" \
--ref_audio {ref_audio} --ref_text {ref_text} \
--target_text {content}
clear_output()
fish-speech1.4模型代码语音克隆
%%time
%cd /kaggle/working/fish-speech
!rm -rf fishspeech14_output.wav
# 从语音生成 prompt
!python tools/vqgan/inference.py \
-i {ref_audio} \
-o "outputs/fake.wav" \
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
# clear_output()
!rm -rf codes_*.npy
# 从文本生成语义 token
!python tools/llama/generate.py \
--text {content} \
--prompt-text {ref_text} \
--prompt-tokens "outputs/fake.npy" \
--checkpoint-path "checkpoints/fish-speech-1.4" \
--num-samples 1 \
--temperature 0.1 \
--half
# clear_output()
# 从语义 token 生成人声
!python tools/vqgan/inference.py \
-i "codes_0.npy" \
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
-o "fishspeech14_output.wav"
# clear_output()
!ls -lh |grep generate
!ls -lh |grep code
!ls -lh outputs
F5-TTS模型推理部分代码
%%time
%cd /kaggle/working/F5-TTS
!rm -rf tests/*
!f5-tts_infer-cli \
--model "F5-TTS" \
--ref_audio {ref_audio} \
--ref_text {ref_text} \
--gen_text {content}
# clear_output()
!ls -lh tests/
Mask-GCT模型推理部分代码
%%time
%cd /kaggle/working/Amphion
!rm -rf mask_gct_output.wav
!python maskgct_main.py --ref_audio {ref_audio} \
--ref_text {ref_text} \
--ref_language 'zh' \
--output_path "./mask_gct_output.wav" \
--target_text {content}
CosyVoice模型的推理代码
%%time
%cd /kaggle/working/CosyVoice
!rm -rf cosyvoice_output.wav
!source activate cosyvoice && export PYTHONPATH=third_party/AcademiCodec:third_party/Matcha-TTS && \
python demo.py --ref_audio {ref_audio} \
--ref_text {ref_text} \
--ref_language 'zh' \
--output_path "./cosyvoice_output.wav" \
--target_text {content}
参考链接
- https://github.com/SWivid/F5-TTS
- https://hf-mirror.com/amphion/MaskGCT
- https://hf-mirror.com/fishaudio/fish-speech-1.4
- https://github.com/RVC-Boss/GPT-SoVITS
- https://github.com/FunAudioLLM/CosyVoice
大家好,今天给大家实操5款爆火的语音克隆模型的效果案例展示,哪款好用等你来评价!本文仅供参考,语音克隆受音频文件和文本内容以及模型性能所影响。
需要特别注意:本文只是技术分享,在使用模型进行语音合成时,需要严格遵照对应项目的要求和法律法规!!
原文出自:https://mp.weixin.qq.com/s/AbVAy8OXkyvjRfxJdDQRTg