一 本文概要
随着金融市场的日益复杂化和大数据时代的到来,精准的股票预测变得尤为关键。传统的时间序列模型,如门控循环单元(GRU),虽然在股票预测中得到了广泛应用,但在处理市场复杂的非线性动态以及灵活选择和有效利用关键历史信息方面仍存在诸多局限。针对以上挑战,本文提出了一种基于多头交叉注意力机制和改进GRU的股票预测模型,命名为MCI-GRU。首先,通过将GRU模型的重置门替换为注意力机制,增强了模型在选择和利用历史信息方面的灵活性。其次,设计了多头交叉注意力机制,以学习不可观测的潜在市场状态表示,并通过与时间特征和横截面特征的交互进一步丰富这些表示。本文方法中国的CSI 300和CSI 500数据集以及美国的NASDAQ 100和S&P 500数据集上进行了广泛的实验,结果表明MCI-GRU在多个指标上均优于现有的最先进方法。此外,本文方法已成功应用于一家基金管理公司的实际操作中,验证了其在真实金融环境中的有效性。
二 背景知识
2.1
门控循环单元(GRU)
门控循环单元(GRU)是一种常用的循环神经网络(RNN)结构,旨在解决传统RNN在处理长序列数据时的梯度消失或爆炸问题。GRU通过引入更新门和重置门来控制信息的流动,从而有效捕捉序列中的长期依赖关系。与长短期记忆网络(LSTM)相比,GRU结构更为简洁,仅包含两个门,但在许多任务中表现出相近甚至更优的性能。在股票预测中,GRU能够有效建模股票价格的时间依赖性,但其对复杂的非线性动态和历史信息的选择利用仍存在一定局限性。
2.2
图神经网络(GNN)
图神经网络(GNN)是一类能够处理图结构数据的神经网络模型,广泛应用于社交网络分析、生物信息学和金融市场预测等领域。在金融市场中,GNN通过将股票视为图中的节点,股票之间的相关性作为边,能够有效捕捉股票之间复杂的相互关系和依赖性。注意力机制的引入进一步增强了GNN在不同节点之间分配注意力权重的能力,使其能够更加灵活地建模股票之间的动态关系。然而,传统GNN在处理高噪声和稀疏数据时仍面临挑战,且模型训练复杂度较高。
2.3
注意力机制与Transformer
注意力机制最早在自然语言处理领域得到了广泛应用,尤其是在Transformer模型中发挥了关键作用。通过计算序列中不同位置之间的注意力权重,Transformer能够高效地捕捉长距离依赖关系,克服了传统RNN在处理长序列时的局限性。多头注意力机制进一步提升了模型的表达能力,使其能够在不同的子空间中并行捕捉多种依赖关系。在股票预测中,注意力机制能够帮助模型更好地选择和利用关键的历史信息,提升预测的准确性和稳定性。
三 本文方法

本文提出的MCI-GRU模型结合了多头交叉注意力机制和改进的GRU结构,旨在提升股票预测的准确性和稳定性。模型架构上图所示,主要分为下面四个模块:
- 改进的GRU模块
传统GRU模型通过更新门和重置门来控制信息的流动,但在捕捉长期依赖性和选择关键历史信息方面存在不足。为此,本文将重置门替换为注意力机制,形成改进的GRU结构。具体而言,使用注意力权重α_t来动态分配历史时间步的信息,从而提高模型对重要时间步的关注度。改进后的GRU能够更有效地提取时间序列中的关键信息,增强对复杂市场动态的建模能力。
- 图注意力网络(GAT)模块
GAT模块用于捕捉股票之间的横截面特征。首先,通过计算过去一年股票收益率的Pearson相关系数构建股票关系图,边权由相关系数决定,并通过设定阈值过滤掉不显著的关系。然后,GAT通过多头注意力机制动态计算节点之间的注意力权重,聚合邻居节点的信息,生成每只股票的更新特征向量。具体步骤包括线性变换、注意力系数计算、归一化及特征聚合,最终输出矩阵A2,捕捉股票之间的复杂关系,丰富横截面数据的特征表示。
- 多头交叉注意力机制模块
为进一步捕捉不可观测的潜在市场状态,本文设计了多头交叉注意力机制。首先,初始化一组可学习的潜在市场状态向量R1和R2,分别与时间特征A1和横截面特征A2进行多头交叉注意力操作,生成潜在状态表示B1和B2。具体而言,利用线性变换,缩放点积注意力,以及多头注意力的拼接和投影,实现R1与A1以及R2与A2之间的高效交互。通过这种交互,模型能够学习到隐藏的市场状态,如市场情绪和预期,从而提升对市场动态的理解和预测能力。
- 预测与损失计算层
在预测层,时间特征A1、横截面特征A2以及潜在状态表示B1和B2被拼接成综合特征向量Z。随后,Z通过额外的两个GAT层进行进一步处理,生成最终的预测结果Z'。具体过程包括图构建、注意力机制计算、特征聚合和降维处理,最终生成每只股票的预测值。损失函数选择均方误差(MSE),通过Adam优化器进行模型参数的优化,以最小化预测值与真实值之间的差异。
四 实验分析
4.1
实验设置
本文实验选取四个不同市场和行业的股票数据集,分别为中国的CSI 300和CSI 500,以及美国的NASDAQ 100和S&P 500。数据集分为训练集(2018-01-01至2021-12-31)、验证集(2022-01-01至2022-12-31)和测试集(2023-01-01至2023-12-31)。特征包括开盘价、收盘价、最高价、最低价、成交量和换手率,标签为每日收益率。评价指标涵盖年化收益率(ARR)、年化波动率(AVol)、最大回撤(MDD)、年化夏普比率(ASR)、卡玛比率(CR)和信息比率(IR)。
4.2
实验结果
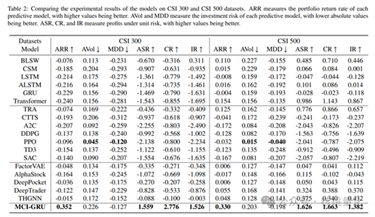
在CSI 300和CSI 500数据集上,传统和深度学习模型如BLSW、CSM、LSTM、ALSTM、GRU和Transformer表现较差,年化收益率(ARR)大多为负,且ASR、CR和IR指标较低。相比之下,MCI-GRU在CSI
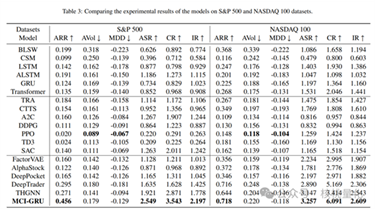
300上实现了0.352的ARR和1.559的ASR,在CSI 500上达到0.330的ARR和1.626的ASR,显著优于基线模型。在S&P 500和NASDAQ 100数据集上,尽管一些强化学习和图神经网络模型如DeepTrader和THGNN表现出色,但MCI-GRU依然表现最佳,分别在S&P 500上达到0.456的ARR和2.549的ASR,在NASDAQ
100上达到0.718的ARR和3.257的ASR,展示了其强大的预测能力和风险调整后的优异表现。
五 总结展望
本文提出的MCI-GRU模型通过融合多头交叉注意力机制和改进的GRU结构,有效提升了股票预测的准确性和稳定性。实验结果表明,MCI-GRU在多个数据集上均优于传统的机器学习方法、深度学习模型以及强化学习和图神经网络基线模型,展示了其在捕捉复杂时间和关系依赖方面的卓越能力。未来的研究可以进一步扩展MCI-GRU模型,结合更多类型的市场数据,如新闻文本和社交媒体情绪分析,增强对市场潜在状态的捕捉能力。同时,优化模型的计算效率和资源消耗,有望推动其在更大规模和更复杂的金融市场中的应用,助力投资者制定更为精准和稳健的投资策略。
原文出自:https://mp.weixin.qq.com/s/TcvXZNSJYIjjj_zrpkgDzw