拖放图像编辑是一项功能强大的技术,它涉及训练生成模型来根据用户提供的指令转换图像。该技术的一个流行实现是拖放生成器(DragGAN),这是一个深度学习模型,当用户将图像拖放到基于web的界面中时,它可以将图像转换为另一个图像。
拖放图像编辑是一项功能强大的技术,它涉及训练生成模型来根据用户提供的指令转换图像。该技术的一个流行实现是拖放生成器(DragGAN),这是一个深度学习模型,当用户将图像拖放到基于web的界面中时,它可以将图像转换为另一个图像。
在传统的图像编辑软件中,用户必须手动选择和移动单个图像元素,如像素、线条和形状,以创建所需的构图。然而,使用拖放生成器,用户可以简单地将预训练的图像转换拖放到网页中,模型将根据用户的指令自动生成新图像。
拖放生成器使用两个阶段的训练过程来生成转换后的图像。首先,训练模型根据一组用户提供的指令来预测图像的内容,比如“水平翻转图像”或“在场景中添加一只猫”。这个阶段通常被称为“条件生成”阶段,因为模型是根据特定提示生成图像的。
在第二阶段,称为“鉴别器”阶段,训练模型区分真实图像和生成图像。这一点很重要,因为模型需要能够区分原始图像和用户创建的转换后的图像。鉴别器阶段通常用于评价生成图像的质量,并调整条件生成阶段以提高生成图像的质量。
总的来说,拖放生成器是一个强大的工具,可以根据用户提供的指令生成高质量的图像。它有许多潜在的应用,包括在线编辑、社交媒体和数字艺术。

项目地址
本地部署 - Pip Install 方式 #
接来下的图片展示以Windows下的部署为例,Linux下的部署也是相同的
目前, Zeqiang-Lai/DragGAN 的实现已经上传到 PyPI 源上了,因此,我们无需下载代码,只需要使用 pip install 即可进行安装。
安装 Conda #
为了避免依赖冲突,我们首先使用Conda创建一个虚拟环境,如果你还没有安装Conda,可以在 这里下载一个Miniconda。
下载完成后,点击安装包一直下一步就可以了。
创建 Conda 虚拟环境 #
接下来从 Windows 菜单栏选择 Anaconda Powershell Prompt (miniconda3) 进入Conda 的命令行。
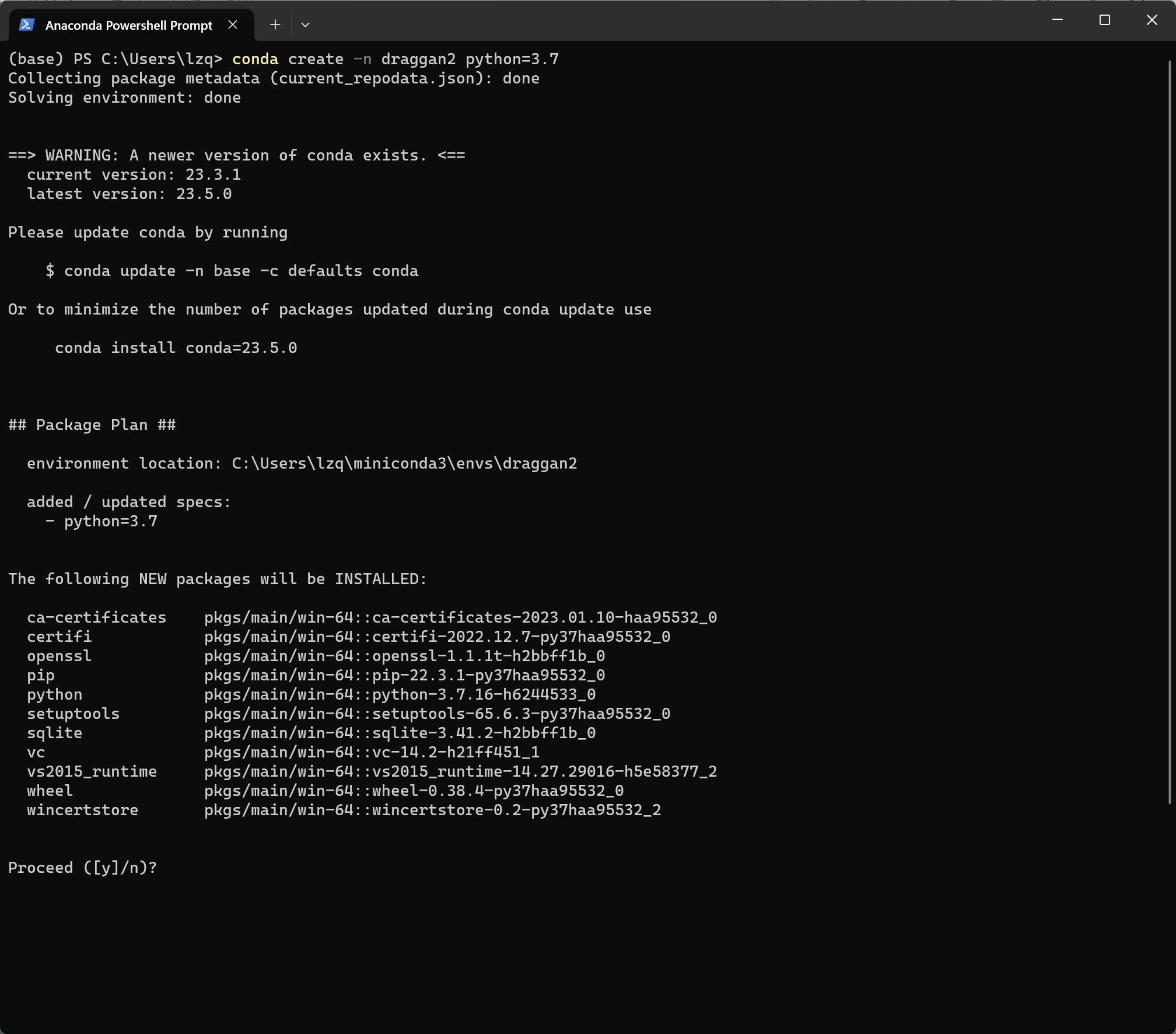
进入之后,输入以下指令创建一个名为 draggan 的环境,python 版本为3.7。提示是否继续的时候输入 y 即可继续。
conda create -n draggan python=3.7
因为我这把已经有一个环境叫draggan了,所以图片里用的是draggan2
安装 PyTorch #
我们首先激活一下刚刚创建的环境,输入以下指令即可
接着,参考PyTorch的 官方安装教程,
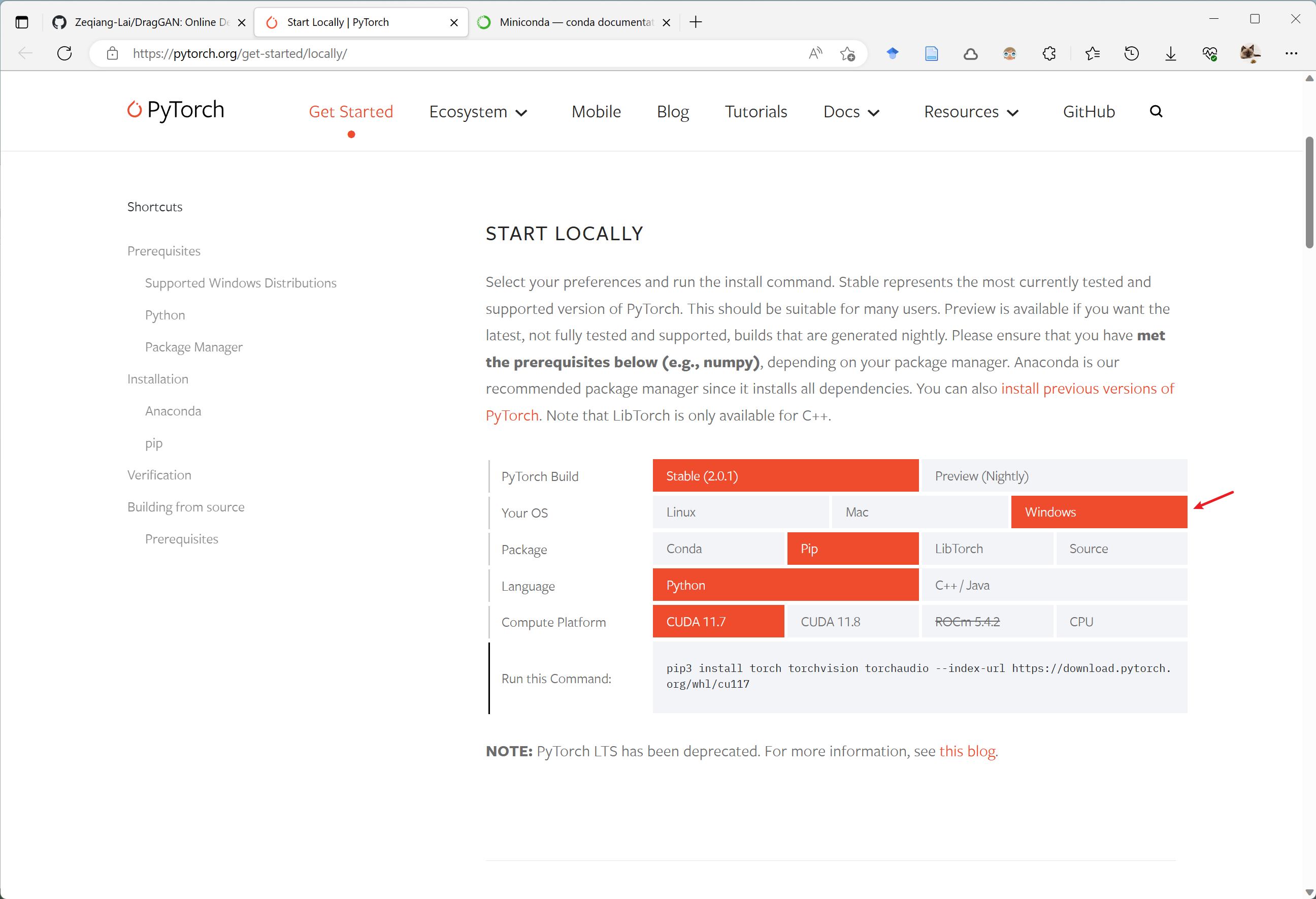
我们可以使用以下指令安装PyTorch,二选一即可,具体选哪个按下载速度自行选择,
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
没有GPU的用户用这个指令安装
pip3 install torch torchvision torchaudio
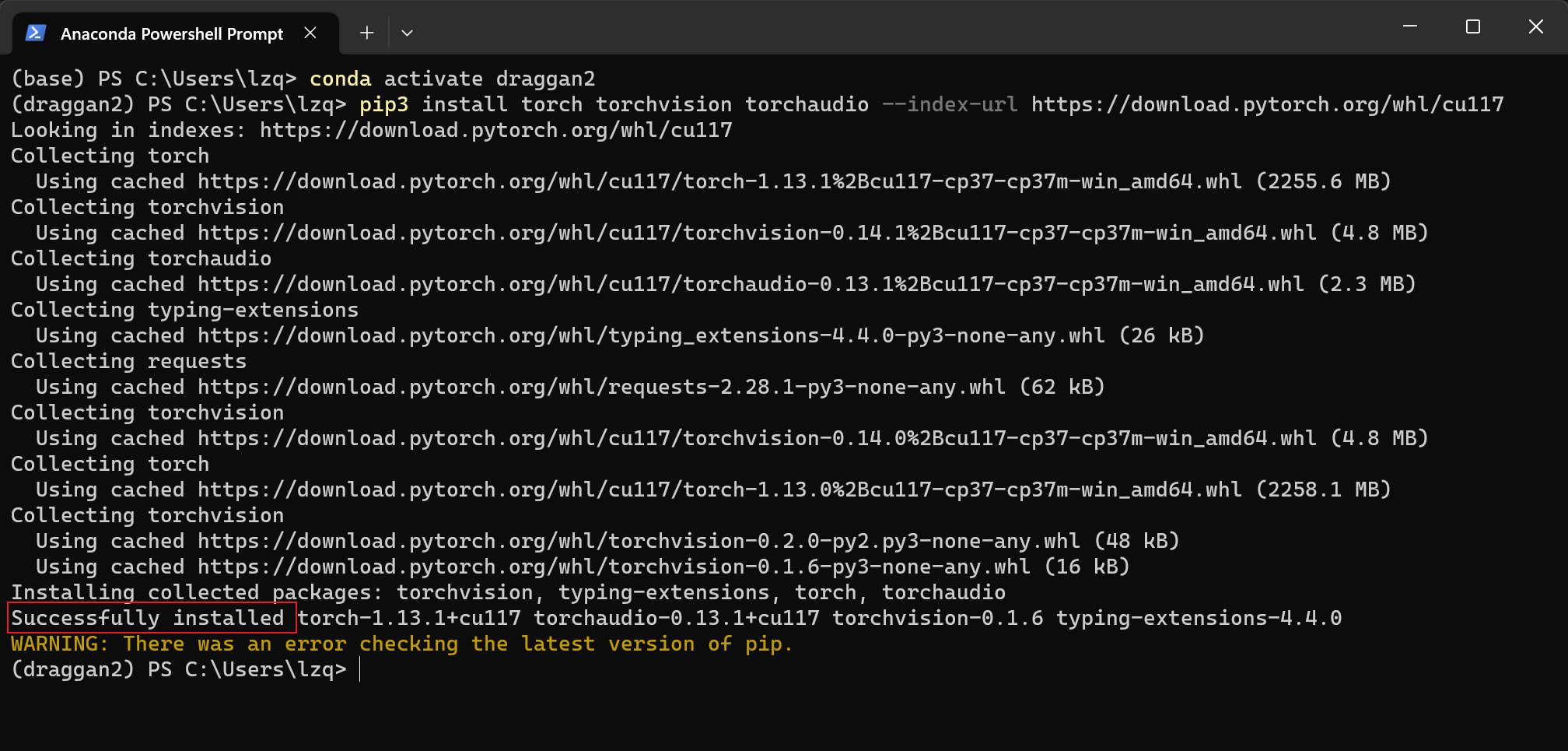
当出现 Successfully installed 就说明安装成功啦,其他 WARNING 都不用管。
安装 DragGAN #
安装完成之后,我们安装DragGAN,这可以通过以下指令进行
因为一些我也不知道的原因,清华pip源没有同步draggan 这个包,如果你的 pip 配置过清华或国内的pip源,你可能会遇到包找不到的问题

这时候你可以使用这个指令,临时使用官方源进行安装
pip install draggan -i https://pypi.org/simple/
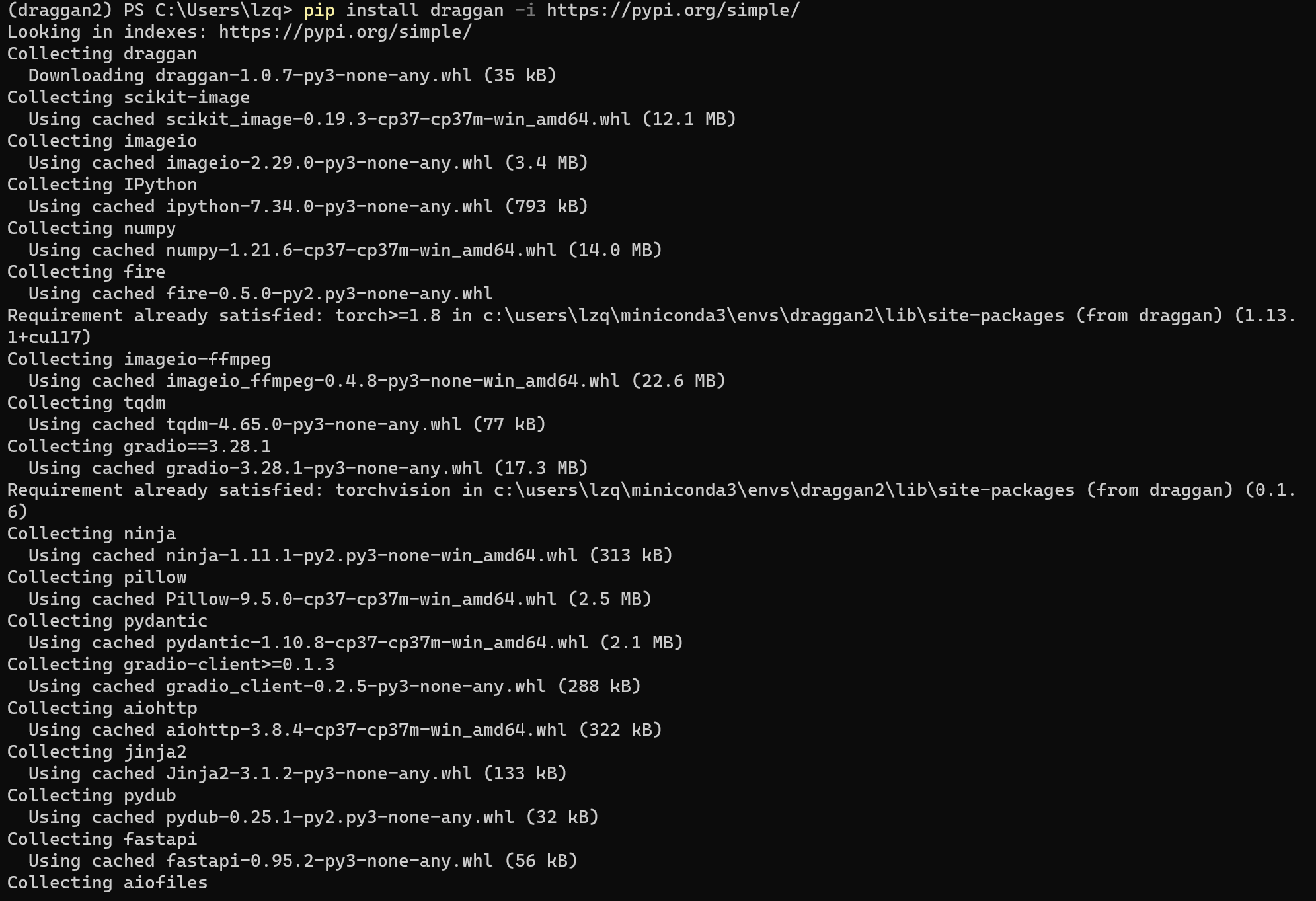
与PyTorch安装类似,当出现 Successfully installed 就说明安装成功了,其他 WARNING 都不用管。
至此,所有依赖安装完成,接下来可以开始运行了。
运行 DragGAN Demo #
你可以通过以下指令运行 DragGAN 的 Demo
如果你不小心关掉了命令行,也不用重新安装,通过 Anaconda Powershell Prompt (miniconda3) 重新进入Conda 的命令行,激活环境,运行即可。
conda activate draggan
python -m draggan.web
没有GPU的用户,使用
python -m draggan.web --device cpu
当出现这个网址的时候 http://127.0.0.1:7860 ,说明程序已经成功运行
将这个网址输入到浏览器里就可以访问到 DragGAN 的 Demo 了
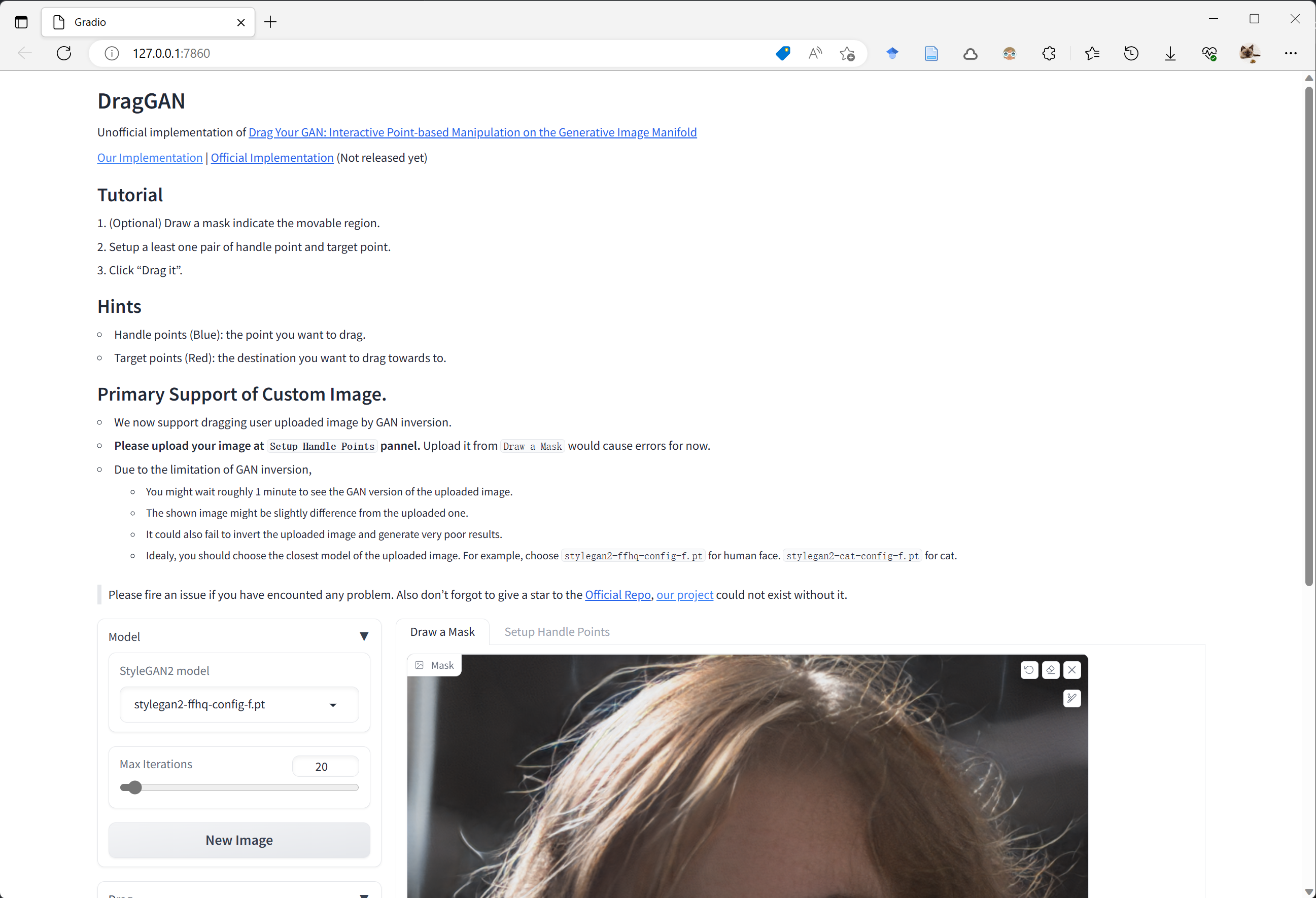
功能介绍 #
界面功能介绍如下
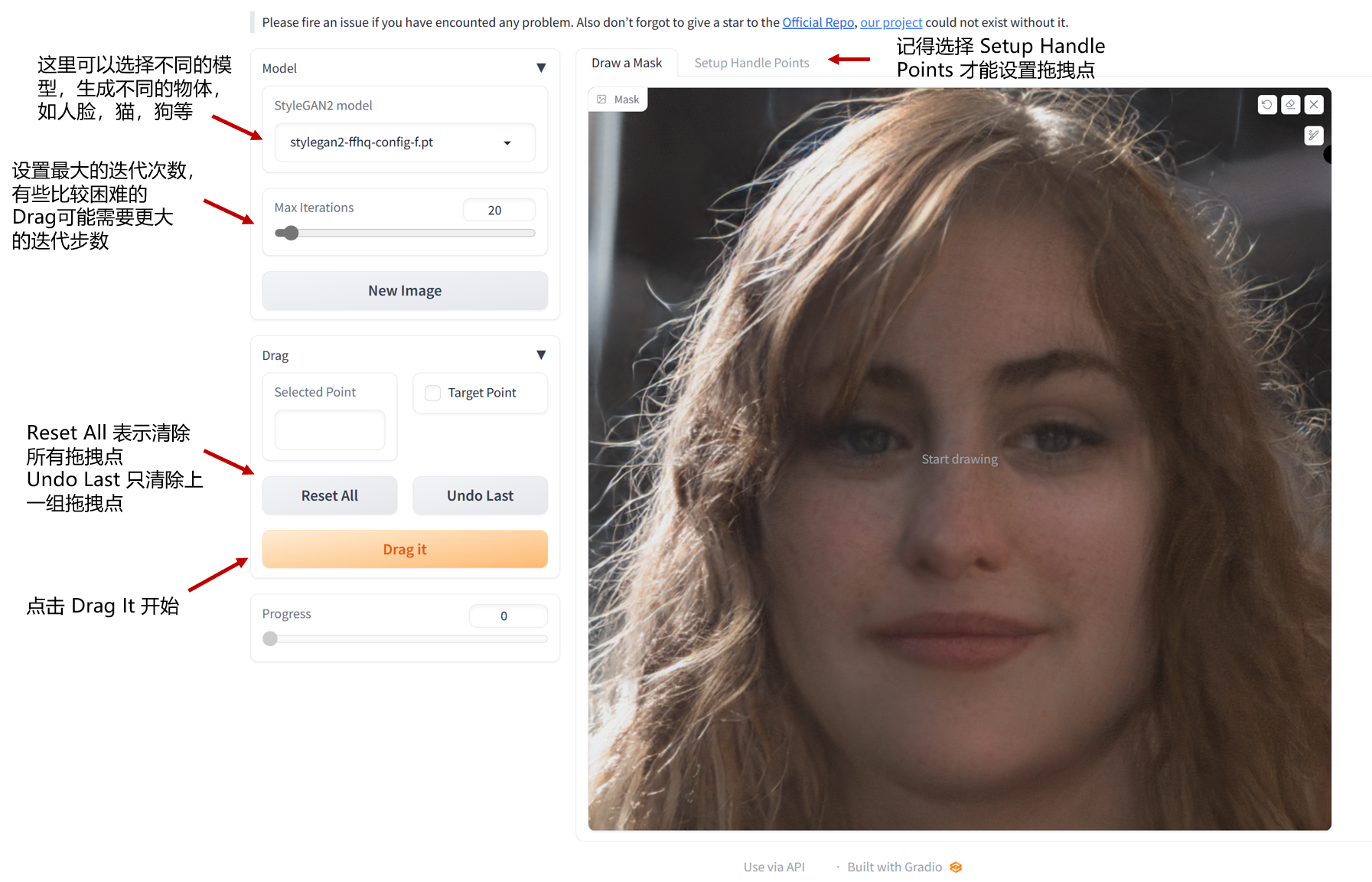
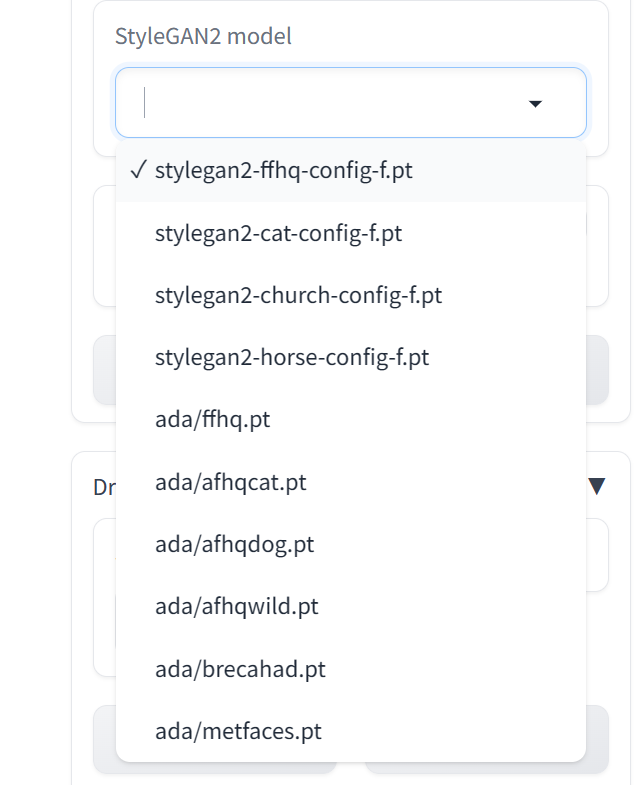
- 选择模型:目前我们提供了10个模型(在web界面选择后会自动下载),不同模型输出图片分辨率,和对显存要求不一样,具体如下
模型信息汇总
| 名称 |
分辨率 |
显存占用 (MB) |
| stylegan2-ffhq-config-f.pt |
1024 |
7987 |
| stylegan2-cat-config-f.pt |
256 |
4085 |
| stylegan2-church-config-f.pt |
256 |
4085 |
| stylegan2-horse-config-f.pt |
256 |
4085 |
| ada/ffhq.pt |
1024 |
7987 |
| ada/afhqcat.pt |
512 |
4473 |
| ada/afhqdog.pt |
512 |
4473 |
| ada/afhqwild.pt |
512 |
4473 |
| ada/brecahad.pt |
512 |
4473 |
| ada/metfaces.pt |
512 |
4473 |
-
最大迭代步数:有些比较困难的拖拽,需要增大迭代次数,当然简单的也可以减少。
-
设置拖拽点对,模型会将蓝色的点拖拽到红色点位置。记住需要在 Setup handle points 设置拖拽点对。
-
设置可变化区域(可选):这部分是可选的,你只需要设置拖拽点对就可以正常允许。如果你想的话, 你可以在 Draw a mask 这个面板画出你允许模型改变的区域。注意这是一个软约束,即使你加了这个mask,模型还是有可能会改变超出许可范围的区域。
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip