“视频版ControlNet”来了!
让蓝衣战神秒变迪士尼公举:

视频处理前后,除了画风以外,其他都不更改。
女孩说话的口型都保持一致。
正在插 剑的姜文,也能“下一秒”变猩球崛起了。
剑的姜文,也能“下一秒”变猩球崛起了。

这就是由全华人团队打造的最新视频处理算法CoDeF,发布才几天,迅速在网上爆火。
网友们看了直呼:
这一天天的,虚实分辨越来越难了!

只需要自己拍点东西,然后覆盖上去,就能变成各种各样的动画了。

有人说,只需给它一年时间,就能被用在电影制作上了。
这马上引来其他人的肯定:技术发展真的非常疯狂、非常快。
目前,团队已将这一方法在GitHub上开源。
姿势不变,画风“皮套”随便换
之所以会被称为是“视频版ControlNet”,主要原因在于CoDeF能够对原视频做到精准控制。
(ControlNet实现了根据提示词精准控制图像元素改变,如人物动作、图像结构等)
根据给到的提示词,它仅改变视频的画风,而且是针对完整视频。
比如输入“Chinese ink painting”,风景纪录片能秒变国风水墨大作。

包括水流也能很好跟踪,整个流体动向都没有被改变。

甚至一大片穗子,在原视频里怎么摆动,改变画风后频率和幅度也如出一辙。

在画风改变上,CoDeF也做了很多细节处理,让效果更加逼真合理。
“由春入冬”后,原本有涟漪的河流静止了,天空中的云彩被换成了太阳,更加符合冬日景象。

霉霉变成魔法少女后,耳环被换成了发光宝石,手里的苹果也换成了魔法球。

这样一来,让电影角色一键变老也简单了许多。
皱纹可以“悄无声息”上脸,其他一切都没有变化。

所以,CoDeF是怎么实现的呢?
可跟踪水和烟雾,跨帧一致性更强
CoDeF是英文“the content deformation field”的缩写,即作者在此提出了一种叫做内容形变场的新方法,来用于视频风格迁移任务。
比起静态的图像风格迁移,这种任务的复杂点在于时间序列上的一致性和流畅度。
比如处理水、烟雾这种元素,两帧画面之间的一致性非常重要。
在此,作者“灵机一动”,提出用图片算法来直接解决视频任务。
他们只在一张图像上部署算法,再将图像-图像的转换,提升为视频-视频的转换,将关键点检测提升为关键点跟踪,而且不需要任何训练。
这样一来,相较于传统方法,能够实现更好的跨帧一致性,甚至跟踪非刚性物体。
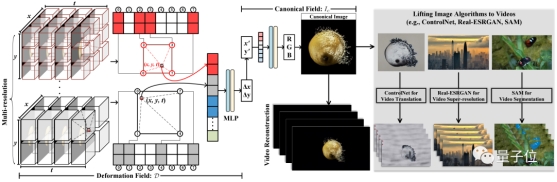
具体而言,CoDeF将输入视频分解为2D内容规范场(canonical content field)和3D时间形变场(temporal deformation field):
前者用于聚合整个视频中的静态内容;后者则负责记录图像沿时间轴的每个单独帧的转换过程。
利用MLP(多层感知器),每个场都用多分辨率2D或3D哈希表来表示。
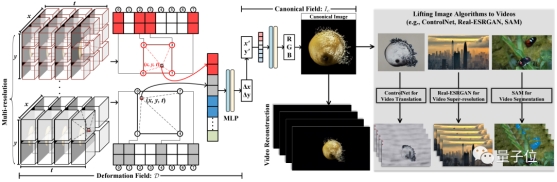
在此,作者特意引入了正则化,来保证内容规范场能够继承原视频中的语义信息(比如物体的形状)。
如上图所示,这一系列设计使得CoDeF可以自动支持各种图像算法直接应用于视频处理——
也就是只需利用相应算法提取出来一张规范图像,然后通过时间形变场沿着时间轴传播结果即可。
比如,给CoDeF“套上”本用于图片处理的ControlNet,就可以完成视频风格的“翻译”(也就是我们开头和第一段看的那一堆效果):

“套上”分割一切算法SAM,我们就能轻松做到视频的对象跟踪,完成动态的分割任务:

“套上”Real-ESRGAN,则给视频做超分也是信手拈来……

整个过程非常轻松,不需要对待操作视频进行任何调整或处理。
不仅能处理,还能保证效果,即良好的时间一致性和合成质量。
如下图所示,相比去年诞生的Layered neural atlas算法,CoDeF能够呈现非常忠于原视频的细节,既没有变形也无破坏。
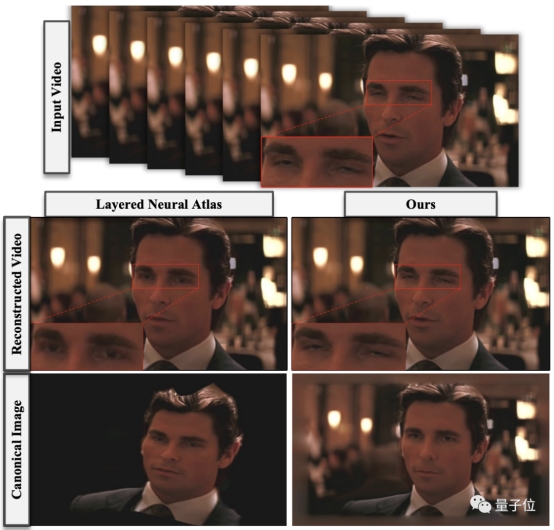
而在根据文本提示修改视频风格的任务对比中,CoDeF全部表现突出,不仅最匹配所给要求,也有着更高的完成度。

跨帧一致性则如下图所示:

一位一作刚本科毕业
这项研究由香港科技大学、蚂蚁团队、浙江大学CAD&CG实验室共同带来。
共同一作有三位,分别是欧阳豪、Yujun Shen和Yuxi Xiao。
其中欧阳豪为港科大博士,师从陈启峰(本文通讯作者之一);本科导师为贾佳亚。曾在MSRA、商汤、腾讯优图实验室实习过,现在正在谷歌实习。

另一位是Qiuyu Wang。Yujun Shen是通讯作者之一。
他是蚂蚁研究所的高级研究科学家,主管交互智能实验室,研究方向为计算机视觉和深度学习,尤其对生成模型和3D视觉效果感兴趣。

第三位一作为Yuxi Xiao才刚刚从武大本科毕业,今年9月开始在浙大CAD&CG实验室读博。
他以一作身份发表的论文Level-S2fM: Structure from Motion on Neural Level Set of Implicit Surfaces,被CVPR2023接收。

论文地址:
https://arxiv.org/abs/2308.07926
项目地址:
https://qiuyu96.github.io/CoDeF/
参考链接:
https://twitter.com/LinusEkenstam/status/1692492872392626284
出自:https://mp.weixin.qq.com/s/IktbUgTf7qXdH6lB1EO4bw
“视频版ControlNet”来了!
让蓝衣战神秒变迪士尼公举:

视频处理前后,除了画风以外,其他都不更改。
女孩说话的口型都保持一致。
正在插 剑的姜文,也能“下一秒”变猩球崛起了。
剑的姜文,也能“下一秒”变猩球崛起了。

这就是由全华人团队打造的最新视频处理算法CoDeF,发布才几天,迅速在网上爆火。
网友们看了直呼:
这一天天的,虚实分辨越来越难了!

只需要自己拍点东西,然后覆盖上去,就能变成各种各样的动画了。

有人说,只需给它一年时间,就能被用在电影制作上了。
这马上引来其他人的肯定:技术发展真的非常疯狂、非常快。
目前,团队已将这一方法在GitHub上开源。
姿势不变,画风“皮套”随便换
之所以会被称为是“视频版ControlNet”,主要原因在于CoDeF能够对原视频做到精准控制。
(ControlNet实现了根据提示词精准控制图像元素改变,如人物动作、图像结构等)
根据给到的提示词,它仅改变视频的画风,而且是针对完整视频。
比如输入“Chinese ink painting”,风景纪录片能秒变国风水墨大作。

包括水流也能很好跟踪,整个流体动向都没有被改变。

甚至一大片穗子,在原视频里怎么摆动,改变画风后频率和幅度也如出一辙。

在画风改变上,CoDeF也做了很多细节处理,让效果更加逼真合理。
“由春入冬”后,原本有涟漪的河流静止了,天空中的云彩被换成了太阳,更加符合冬日景象。

霉霉变成魔法少女后,耳环被换成了发光宝石,手里的苹果也换成了魔法球。

这样一来,让电影角色一键变老也简单了许多。
皱纹可以“悄无声息”上脸,其他一切都没有变化。

所以,CoDeF是怎么实现的呢?
可跟踪水和烟雾,跨帧一致性更强
CoDeF是英文“the content deformation field”的缩写,即作者在此提出了一种叫做内容形变场的新方法,来用于视频风格迁移任务。
比起静态的图像风格迁移,这种任务的复杂点在于时间序列上的一致性和流畅度。
比如处理水、烟雾这种元素,两帧画面之间的一致性非常重要。
在此,作者“灵机一动”,提出用图片算法来直接解决视频任务。
他们只在一张图像上部署算法,再将图像-图像的转换,提升为视频-视频的转换,将关键点检测提升为关键点跟踪,而且不需要任何训练。
这样一来,相较于传统方法,能够实现更好的跨帧一致性,甚至跟踪非刚性物体。
具体而言,CoDeF将输入视频分解为2D内容规范场(canonical content field)和3D时间形变场(temporal deformation field):
前者用于聚合整个视频中的静态内容;后者则负责记录图像沿时间轴的每个单独帧的转换过程。
利用MLP(多层感知器),每个场都用多分辨率2D或3D哈希表来表示。
在此,作者特意引入了正则化,来保证内容规范场能够继承原视频中的语义信息(比如物体的形状)。
如上图所示,这一系列设计使得CoDeF可以自动支持各种图像算法直接应用于视频处理——
也就是只需利用相应算法提取出来一张规范图像,然后通过时间形变场沿着时间轴传播结果即可。
比如,给CoDeF“套上”本用于图片处理的ControlNet,就可以完成视频风格的“翻译”(也就是我们开头和第一段看的那一堆效果):

“套上”分割一切算法SAM,我们就能轻松做到视频的对象跟踪,完成动态的分割任务:

“套上”Real-ESRGAN,则给视频做超分也是信手拈来……

整个过程非常轻松,不需要对待操作视频进行任何调整或处理。
不仅能处理,还能保证效果,即良好的时间一致性和合成质量。
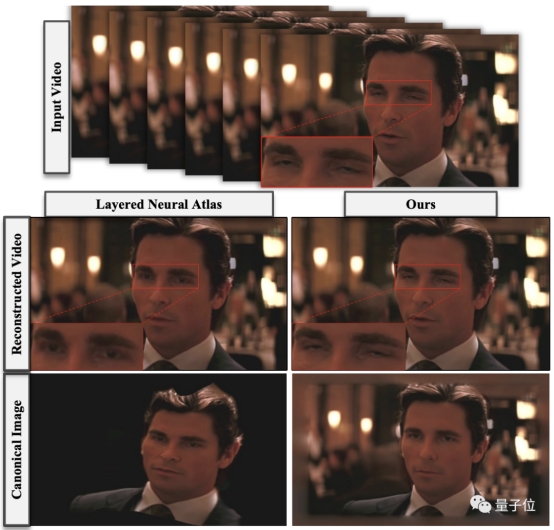
如下图所示,相比去年诞生的Layered neural atlas算法,CoDeF能够呈现非常忠于原视频的细节,既没有变形也无破坏。
而在根据文本提示修改视频风格的任务对比中,CoDeF全部表现突出,不仅最匹配所给要求,也有着更高的完成度。

跨帧一致性则如下图所示:

一位一作刚本科毕业
这项研究由香港科技大学、蚂蚁团队、浙江大学CAD&CG实验室共同带来。
共同一作有三位,分别是欧阳豪、Yujun Shen和Yuxi Xiao。
其中欧阳豪为港科大博士,师从陈启峰(本文通讯作者之一);本科导师为贾佳亚。曾在MSRA、商汤、腾讯优图实验室实习过,现在正在谷歌实习。

另一位是Qiuyu Wang。Yujun Shen是通讯作者之一。
他是蚂蚁研究所的高级研究科学家,主管交互智能实验室,研究方向为计算机视觉和深度学习,尤其对生成模型和3D视觉效果感兴趣。

第三位一作为Yuxi Xiao才刚刚从武大本科毕业,今年9月开始在浙大CAD&CG实验室读博。
他以一作身份发表的论文Level-S2fM: Structure from Motion on Neural Level Set of Implicit Surfaces,被CVPR2023接收。

论文地址:
https://arxiv.org/abs/2308.07926
项目地址:
https://qiuyu96.github.io/CoDeF/
参考链接:
https://twitter.com/LinusEkenstam/status/1692492872392626284
出自:https://mp.weixin.qq.com/s/IktbUgTf7qXdH6lB1EO4bw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip