用AI生成的指令微调羊驼大模型,数学能力超ChatGPT——
微软最新开源大模型WizardMath来了。 作者:AI观察室 https://www.bilibili.com/read/cv25736782/ 出处:bilibili
用AI生成的指令微调羊驼大模型,数学能力超ChatGPT——
微软最新开源大模型WizardMath来了。

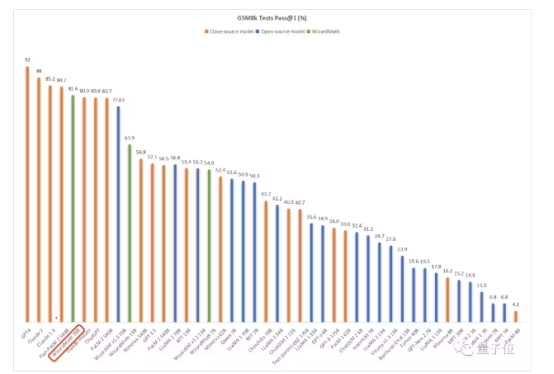
如下图所示,经过GSM8k数据集测试,WizardMath数学能力直接击败了ChatGPT、Claude Instant 1、PaLM 2-540B等一众大模型——
并且是在参数只有700亿,远不及后三者的情况之下。
HuggingFace已上线3个在线可玩版本(分别为7B、13B和70B参数),各种数学题可以直接丢进去试一试。
比如解决下面这道四次多项式方程:
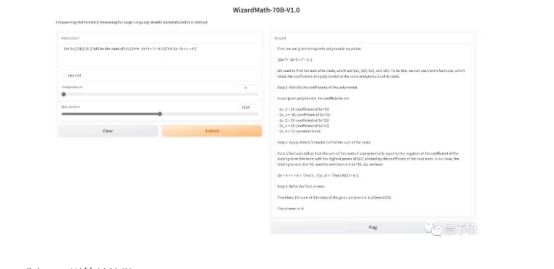
或者是一道简单的微积分:
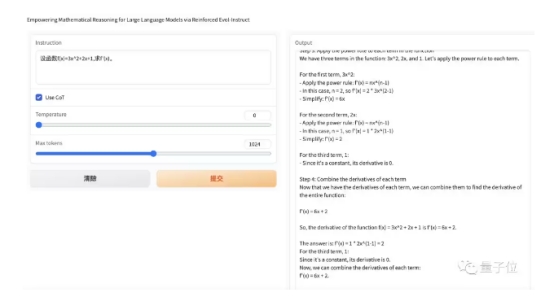
亦或者是稍微修改过的拉格朗日方程推导:
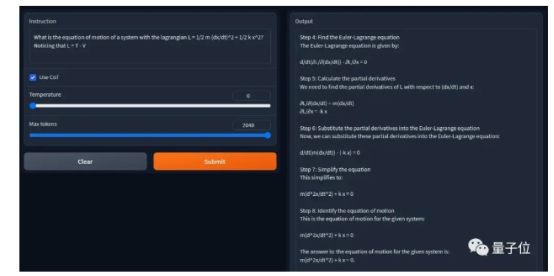
它都全部正确(过程也不需要等太久)。
有网友向作者表示:
目前,相关代码、复现方式以及论文也都开源或上线,GitHub短短几天已揽获4.8k标星。

那么,WizardMath究竟是如何做到的?
用AI生成的指令增强大模型能力
OpenAI的大模型(InstructGPT、GPT-4等)能够取得巨大成功、去执行各种复杂和多样化的任务,一部分原因是使用了真实人类用户生成的开放域指令数据进行了微调。
然而,不是谁都能像这家公司一样获得这样的指令数据集。
一是因为整个注释过程极其昂贵且耗时,二是人工难以创建出足够比例的高难度指令。
因此,开发出一种成本相对较低的、大规模开放域指令自动生产方法,成为当下指令调优语言模型的关键。
在此,作者将他们的方法命名为Evol Instruction。
它是一种利用AI来代替人类自动生成涵盖各种难度级别开放域指令的新方法。
具体而言,Evol Instruction分为指令进化器和指令消除器。
其中指令进化器可通过深度进化(蓝线)或广度进化(红线)两种路径,将简单指令升级为更复杂的指令或创建一条全新指令。
具体执行哪一条?随机选择就好。
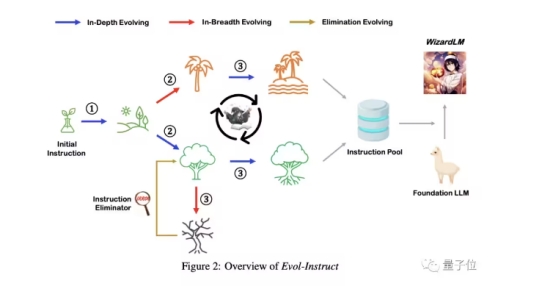
其中,深度进化的具体“进化法”,则是通过五种类型的操作来完成,包括:
添加约束(add constraints)、深化(deepening)、具体化(concretizing)、增加推理步骤(increase reasoning steps)和使输入复杂化(complicate input)。
由于所有指令均由AI完成,有时难免会出现错误。因此,指令消除器就是用于过滤失败指令的。
以下是一个具体示例,该方法从“1+1=?”开始,最终通过以上步骤自动生成了相当多的新指令。
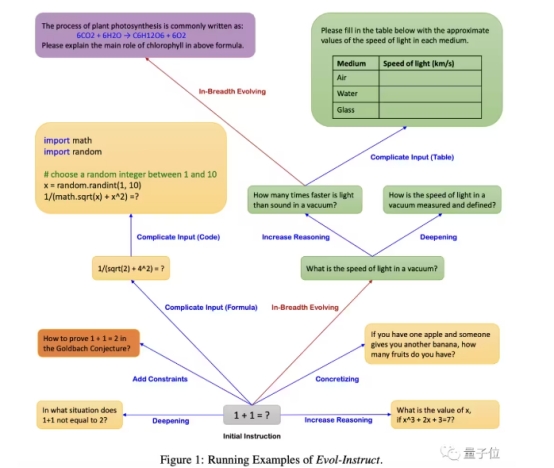
通过重复这一生成过程,最终我们就能得到足够多的指令,然后将它们合并并随机打乱,组成一个难度级别均匀分布的指令集,就可以对基础大模型进行微调了。
在此,作者选择Alpaca的训练数据(仅由175条人工创建的种子指令生成)作为初始数据集,然后使用ChatGPT的API执行了四个进化周期,最终获得25万条指令。
为了与Vicuna的70k真实用户数据(ShareGPT)进行公平比较,作者从这25万条数据中抽取了等量的样本,训练LLaMA 7B模型,最终得到WizardLM,结果WizardLM的性能明显优于Vicuna。
(Alpaca:斯坦福在LLaMa-7B基础上微调出来的模型;Vicuna,UC伯克利在LLaMa-13B的基础上微调得来)
此外,在更为复杂的测试指令下,人类更喜欢WizardLM的输出,而非ChatGPT,这表明该方法可以显着提高LLM处理复杂指令的能力。
基于此,作者又利用Evol Instruction生成了很多数学领域相关的指令,然后微调羊驼大模型,得到了WizardMath。
其效果如开头所示,在GSM8k数据集上测得其数学能力超越包括ChatGPT、Claude Instant 1、PaLM 2-540B等一众大模型,位列第5名,仅次于GPT-4、Claud1.3和2.0,以及5400亿参数的Flan-PaLM 2之后。
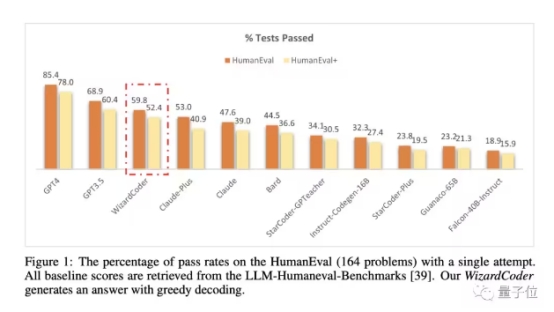
以此类推,作者还在羊驼之上得到了专攻代码能力的WizardCoder,效果超越Claude和Bard(详情可戳文末地址)。
出自:https://www.bilibili.com/read/cv25736782/
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip