随着大型语言模型如ChatGPT的流行,许多研究机构,企业,兴趣爱好者等都正在尝试微调大语言模型(large language model),以适应特定的应用场景。微调质量的好坏受到多个因素的影响,包括基底模型架构、参数量、微调数据集质量以及RLHF(RLHF:Reinforcement Learning from Human Feedback)等。在这些因素中,采用预训练并使用自己的数据集来微调是一个相对简单易行的方案。为了实现大型语言模型的微调,一个合适的微调数据集是必须的。构建一个高质量的微调数据集可以使经微调后的模型在特定任务上表现更为优秀。
随着大型语言模型如ChatGPT的流行,许多研究机构,企业,兴趣爱好者等都正在尝试微调大语言模型(large language model),以适应特定的应用场景。微调质量的好坏受到多个因素的影响,包括基底模型架构、参数量、微调数据集质量以及RLHF(RLHF:Reinforcement Learning from Human Feedback)等。在这些因素中,采用预训练并使用自己的数据集来微调是一个相对简单易行的方案。为了实现大型语言模型的微调,一个合适的微调数据集是必须的。构建一个高质量的微调数据集可以使经微调后的模型在特定任务上表现更为优秀。以下是构建高质量微调数据集的一些考虑因素:数据来源:选择合适的数据来源非常关键,可以通过从相关领域中抓取或收集适当领域的数据来收集数据。如果要微调模型以处理特定任务,那么数据集必须包括与该任务相关的文本,例如,如果要构建常见的具有情感反馈的微调数据集,则数据集应包含正面和负面评价的文本。数据质量:数据集的质量对于模型的微调至关重要。因此,应该在准备数据时仔细检查并清洗数据。确保数据集不包含无用的文本及其他噪声。数据集中的每个数据样本都应具有明确的实际意义,以便模型能够较好地理解其含义。数据规模:数据集的大小也很重要。数据样本应该充分,以确保模型能够准确地学习特定任务的格式和规律。通常认为,数据集中的文本数量应该在几千到几十万之间,但目前的研究对这个问题有了一些新的看法,关于这个问题下文将具体分析。相似性:在构建微调数据集时,应注意确保数据之间是具有相互关联的,且又易于泛化的。这意味着它们应该在特定的微调任务上具有代表性,但又不是简单的重复。尽管有研究表明重复数据并不降低模型的质量,但是重复冗余的数据会增加额外的微调成本。从目前的实践来看,微调是一种非常实用的技术,但是构建微调数据集并不是一件轻松的事情。因此本文将从微调数据集的格式、基本处理方法,以及构建方式角度出发,分析近期开展的相关研究,旨在帮助读者了解微调数据集相关技术的进展。
微调数据集的格式
目前常见微调数据集的格式包括以下几种:指令跟随格式、多轮对话格式,以及其他辅助格式。1. 指令跟随格式指令跟随形式是指用户输入指令,模型按照指令的要求输出结果的格式。这种形式的数据集通常采用json文件格式存储,典型的如Alpaca-52k数据集[1]。Alpaca-52k是一个开源的遵循指令的,最初用来微调LLaMA模型以得到Alpaca-7B模型的数据集,包含了52000条指令数据。这里的52k代表的是共有五万两千对指令与输出对。Alpaca的格式有两类,一类是instruction/output格式,例如:
#instruction:什么是三原色?
#output:三原色是红、蓝、黄。这些颜色被称为原色,因为它们不能通过混合其他颜色来创建,而所有其他颜色都可以通过以不同比例组合它们来制作。在用于光的加法色彩系统中,原色是红、绿、蓝(RGB)。另一类为instruction/input/output格式,例如:#instruction:检查这个句子的拼写和语法错误#input:他吃完饭离开了餐厅。#output:这句话中有两个拼写错误。正确的句子应该是:“他吃完饭离开了餐厅。然而,由于生成Alpaca数据集的self-instruct [2] 技术得到的数据集本身存在一些瑕疵,因此数据集需要进一步清洗和改进,例如alpaca-cleaned [3] 和alpaca-gpt4 [4]。此外还有中文翻译版本[5]。这些数据集通常包含几万个指令对,文件大小约为40MB左右的json格式文件。这里补充一句,在相关研究中,数据集长度通常采用token数或指令条数进行计算。由于token数与tokenizer相关,而指令数会因文本长度的不同而有大的影响。为了直观起见,在本文的数据集规模评估中选择文件存储大小作为评估指标。
2. 多轮对话格式多轮对话形式是指用户和模型之间以对话的形式进行,模型将通过与用户进行多轮的交互最终来达到用户的需求。典型的如训练Vicuna模型 [6] 所使用的ShareGPT数据集,ShareGPT本身是一个与ChatGPT(GPT-4)模型的聊天记录分享平台,它托管了大量由用户挑选的对话数据集,这些聊天记录通常展示的是聊天机器人自然流畅、具有创意的回答。Vicuna模型通过收集该平台的数据,数据大小为 673MB [7],其训练出来的模型具有较好的多轮对话能力,具体格式如下 [6]:
"conversations": [ { "from": "human", "value": "Who are you?" }, { "from": "gpt", "value": "I am Vicuna, ..." }, { "from": "human", "value": "What can you do?" }, { "from": "gpt", "value": "I can chat with you." }
3. 其他形式
除了上述提到的数据格式,还有一些数据格式不易转化为对话形式,例如纯文本文档。另外,还有一些针对特定用途的数据集,例如文本总结数据集以及根据纯文本生成对话的数据集,如RefGPT [8] 文章提到的方案。根据文本的不同功能,它们还包括调用API的格式 [9] 和调用数据库语言的格式 [10] 等。当然,除非以纯文本的形式存在,否则这些格式都可以转换为指令跟随或多轮对话的格式。需要注意的是,这里所提到的微调数据集的格式并不包括基于强化学习训练的所使用的RLHF数据集。
微调数据的基本处理
微调数据集需要经过一系列的处理步骤,包括数据收集、数据清洗和数据增强等。数据收集是文本处理的基础,可通过公共数据集、自定义数据集和行业数据集等多种方式获得。在获得数据集后,需要进行数据清洗,去除噪声、重复和低质量的数据,将其统一转化为可训练的格式。另外,为了提高数据集的质量和丰富性,可以采用数据增强技术,如翻译、摘要、同义词替换、随机插入等操作,当然由于大模型本身已经有了很强的文本处理能力,这些数据增强技术都可以使用大模型来辅助完成。通常,微调数据集的规模比预训练数据集小得多。典型的相比于几个TB的预训练文本数据,预训练的存储大小通常在几MB到1GB左右。在收集和整理数据后,可以将自定义数据集与其他开源数据集混合训练。此外,微调数据集通常还包含一个用于自身认知的数据集,典型的如训练Vicuna模型时提到的Dummy数据集 [6]。自定义数据集与其他开源数据集混合训练有助于提高模型效果和泛化性。例如近期发布的模型 MPT-30B-Chat [11] 即混合了多种的对话数据集,如下:
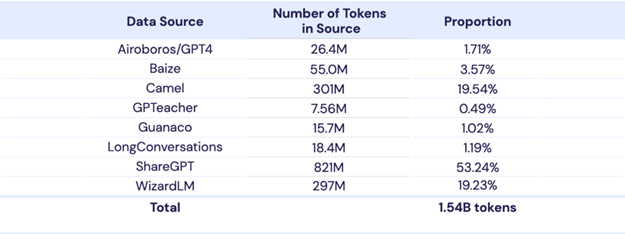
图1.微调MPT-30B-Chat模型用到的混合数据集图片来源:https://www.mosaicml.com/blog/mpt-30b
由于数据整理过程往往需要涉及许多方面,因此一个好用的GUI工具将有助于加速上述数据处理的过程。常见的开源数据标注工具如Label-Studio正在向这方面进行拓展,近期还出现了一套新工具如H2O LLM Data Studio [12],如下图。虽然微调数据难以单独评测效果,但训练出更好的大模型可以间接地证明该工具的有效性。因此,如果这一类GUI工具能够更好地将数据处理与模型微调过程一同处理,那么将帮助我们更快地得到一个更好的大模型。
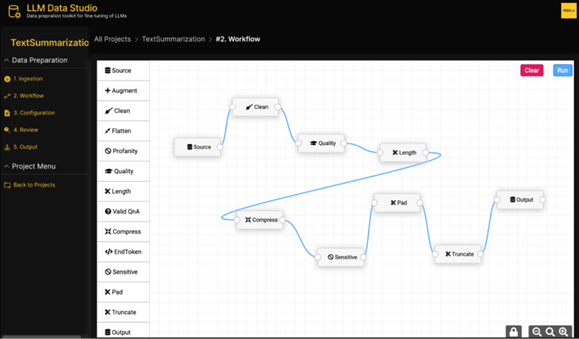
图2.H2O LLM Data
Studio GUI工具预览图片来源:https://blog.h2o.ai/blog/streamlining-data-preparation-for-fine-tuning-of-large-language-models/
当然,大型预训练模型的标准化步骤仍在在不断变化和发展中,更加便捷和高效的微调数据的处理实践方案也正在被探索中。
微调数据构建方式的探索
在上述的讨论中可以看到,微调数据集的构建非常重要,可以说是定制化自有模型时最核心的环节了。微调的目的是以一个预训练的模型为基础,利用一个小数据集,以打磨细节的方法,重新微调一个更为定制化的模型。
在构建微调数据集时,有一些值得注意的事项和构建方法,例如可以基于现有的大模型进行self-instruct,以及利用一些基本原则通过结合self-instruct方法来构建微调数据,如Dromedary-65B模型的微调方法 [13]。虽然从已有模型中构建数据是一种简便的方法,但并不一定能得到高质量的数据集。加之数据量大小不是唯一的评判标准,例如根据LIMA [14] 文章的结果表明,一定数量的微调数据就可以激活大模型预训练的数据,关键在于数据的质量和对模型的启发。基于LIMA文章的思想,出现了一个有意思的模型称为based [15],该模型的指导思想是,大模型本身已经拥有对各种事物的看法了,仅仅需要教会它如何说话就可以了。该模型有意思的地方在于,其微调数据的文件大小仅72.8KB,就可以让大模型流畅表达它的观点了,作为对比,LIMA的微调数据文件大小有2.97MB。
构建微调数据集的目的是,一方面是告知大模型一些新的知识,另一方面是调整大模型以我们期待的方式回复我们。如果需要告诉大模型一种新的知识,可能需要用高质量教导式的方式进行数据扩充。在这里,已有的文章提供了许多启示,例如Orca模型 [16] 的训练方式,从GPT-4获得丰富的解释轨迹,进行逐步思维,从而使得LLaMA-13B模型训练出具有ChatGPT相当的效果。又如 Textbook is all you need [17] 文章所提出的(尽管这篇文章讨论的并非是微调过程),可以构建更加具有教育意义的知识,例如采用教科书级别的数据集,这样能使大模型在编程领域上达到更高的水平。当然,为了增加微调数据的复杂度,也可以基于大模型根据已有的数据通过演化的方法来生成更加复杂的微调数据 [18][19]。
另外,微调数据集的构建和tokenizer也有关系。其中最大的影响是,tokenizer会影响到大模型的学习,例如文章 [20][21] 提到的,不恰当的tokenizer影响会影响大模型在两位数的加法正确性。当然,如果不想更改已经训练好的tokenizer,那么在构建微调数据集时,最好使用tokenizer中已有的词汇。当然,tokenizer本身会影响到token的长度,例如带有更多中文词汇的tokenizer可以使得中文文本经过tokenizer之后更短。同时在数据集处理过程加入StartToken,PadToken,EndToken等标记,也可以帮助模型更好地理解数据,或者帮助下游应用进行编码,一个具体的例子如Vicuna模型,在版本更新后,他们在微调数据集中加入了新的对话结束的标记:</s>,使模型能有效地预测何时停止生成字符。
综上,在构建微调数据集时,需要考虑方方面面的问题,不仅需要注重数据质量和数量的平衡,同时也要让模型了解我们的期望,以及在专有的定制领域获得相应的知识,从而达到在定制领域具有更高的预测准确性。由于微调数据的重要性,因此这方面的努力都是值得的。
总结
本文主要讨论了大语言模型的微调数据集构建技术,并阐述了微调数据集的格式、数据增强和数据整理等步骤。与预训练数据集相比,微调数据集的构建需要更加精益求精。在实践中,采用自定义数据集与其他开源数据集混合训练的方式可以帮助微调模型提高效果和泛化性。然而,构建高质量微调数据集是一项庞杂琐碎的任务,需要耗费大量的时间和精力。期待在未来出现更加友好易用的GUI工具,帮助我们更好地构建微调数据集。
出自:https://mp.weixin.qq.com/s/UPsfwxHObhaVB6yrm3atYw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip