这篇文章中,我并不试图去解释ChatGPT的一切,而是将从原理出发,思考计算机理解语言的关键要素,这些思考落到了一个具体的切入点 —— embedding —— 一个第一眼难以理解但极为关键的东西。
和大部分人一样,我对自然语言处理和语言模型的了解从ChatGPT开始。
和大部分人一样,第一次接触就被ChatGPT的能力所震惊 —— 计算机确实做到了理解人类的语言。
我也产生了几乎人人都会有的疑问:怎么做到的?
这篇文章中,我并不试图去解释ChatGPT的一切,而是将从原理出发,思考计算机理解语言的关键要素,这些思考落到了一个具体的切入点 —— embedding —— 一个第一眼难以理解但极为关键的东西。
文章是一个门外汉通过业余的研究和碎片的思考所完成,谬误之处难以避免,欢迎专业的研究人员指正。
1 编码:文字的数字化
Embedding 这个词直译为中文是:嵌入,这是让人头秃的两个字 —— 啥是嵌入?嵌入了啥?跟自然语言又有啥关系?它的体现形式是一组具有固定长度的数组,或者叫做向量,但它究竟是什么?为什么需要它?它在计算机理解自然语言的过程中扮演的是怎样的角色呢?
要回答这些问题,不妨先思考:让计算机理解自然语言,我们需要做什么?
计算的基础是数,而自然语言是文字,因此很容易想到要做的第一步是让文字数字化,为行文方便,我们将这个过程叫做编码。要设计编码的方法,自然需要思考的问题是:哪些性质是编码规则必须要满足的?
有一条是显然可以给出的:
性质一:每一个词具有唯一量化值,不同词需要具有不同的量化值
背后的逻辑不言自明:一词多数,或是多词一数,都会增加计算机理解语言的难度,这种难度就如同多音字或是多义词给人类造成的困难,尽管人类的智慧让我们可以克服这些障碍,但对于仍然处于培育智能阶段的计算机,为它降低一些难度显然是必要的。
满足性质一的方法非常容易设计,例如:首先穷举出人类所有的文字或词组 —— 这个集合必定是有限集,例如汉字有10万个,辞海收录的词大概60万个,字母有26个,英语单词数小于100万个 ——— 由于是有限集,我们可以给每一个词分配一个固定的数字,例如打开一个词典,将遇到的单词依次赋予一个不同的数值:
A --> 1
Abandon --> 2
Abnormal --> 3
... |
这便完成了符合性质一的编码。例如 "Hello World" 这句话就可以作为 ”3942 98783“ 这样的数字序列输入,从而可以被计算机处理。但这一方法的问题是显然的:
数的值与词的义是割裂的。
这种割裂会产生什么问题?可以通过一个简单的例子来思考:在英语中,a 和 an 是完全同质的词,而 a 和 abnormal 则是差异极大的词。如果按照上述编码方式, a 可能会被赋予数值1,abnormal会被赋予数值2,an 会被赋值赋予数值 123 ,这个时候我们可能会发现 a 和 abnormal 似乎在数值上更加靠近,而 a 和 an 这两个同质的词却隔得非常远。这时容易想到要添加一条性质,来确保数字化后的数值与词义之间的关联:
性质二:词义相近词需要有"相近"的量化值;词义不相近的词量化值需要尽量“远离”
2 基于词义的编码
上面的例子中虽然提到了字典编码法会割裂数值和词义,却未能解释为什么数值和词义应该关联 —— 基于直觉的思考会认为这一点是显然的,但模糊的显然容易掩埋值得被清晰梳理的逻辑。我能够想到的原因有两个:
00001. 可以帮助更加高效理解语义;
00002. 允许计算模型的设计有更大的自由度。
第1条怎么理解?如果说词的数值分布与词义无关,这会使得文本的序列变得过于随机,例如:
句子一:张三在讲话。
句子二:李四在发言。
这两句话有着非常强的同质性,但如果对于字/词的编码不符合性质二,这就会使得以上两句话的序列特征会有非常大的差异。以下的例子或许足够直观:
如果近义词具有相近的量化值,词和值之间的关系或许会是这样,看起来就是相似的形状:
张 --> 105, 李 --> 99
三 --> 3, 四 --> 4
在 --> 200,
讲话 --> 300, 发言 --> 295 |
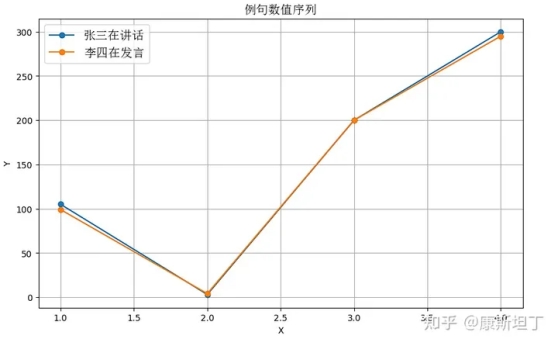
而如果近义词具有不相近的量化值,词和值之间的关系或许会是这样,一眼看上去似乎没什么关系:
张 --> 33, 李 --> 1
三 --> 5, 四 --> 200
在 --> 45,
讲话 --> 2, 发言 --> 42 |
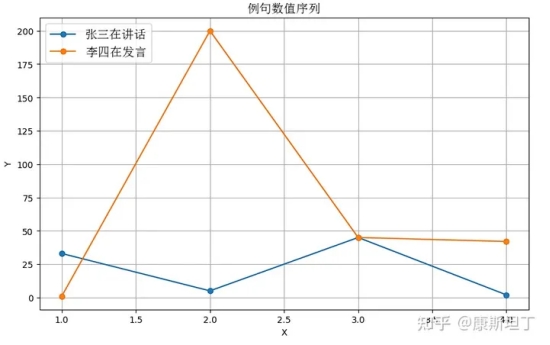
换言之,当性质二得到满足时,同义的句子在序列特征上会更加接近,这将有利于计算机而言更高效地理解共性、区分特性;反之则会给计算机制造非常多的困难。难以捕捉同质内容之间的共性,就意味着模型需要更多的参数才能描述同等的信息量,学习的过程显然困难也会更大。OpenAI 的 Jack Rae 在 Standford 的分享 中提到了一个很深刻的理解语言模型的视角:
语言模型就是一个压缩器。
这个观点已有不少文章都做了阐释[1][2]。所有的压缩,大抵都能被概括在以下框架内:提取共性,保留个性,过滤噪声。带着这个视角去看,就更加容易认识到性质二的必要性。不同词所编码的数值,是否基于词义本身的相似性形成高区分度的聚类,会直接影响到语言模型对于输入数据的压缩效率。
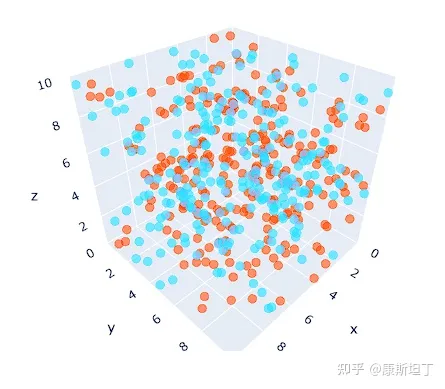
编码值未基于词义形成聚类
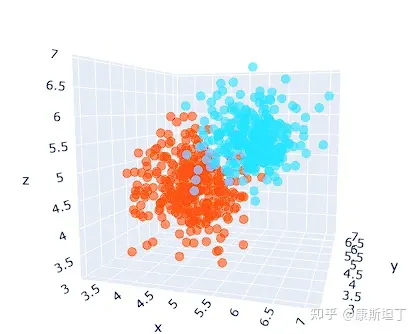
编码值基于词义形成聚类
第2条怎么理解?
因为词是离散分布的,而计算模型的输出 —— 除非只使用非常简单的运算并且约束参数的权重 —— 很难恰好落在定义好的量化值中。对于神经网络模型,每一个节点、每一层都必须是连续的,否则便无法计算梯度从而无法应用反向传播算法。这两个事实放在一起可能会出现的情况是:词的量化值可以全部是整数,但是语言模型的输出不一定。例如当模型输出 1.5,词表只定义了 1 和 2,这时该如何处理呢?我们会希望 1 和 2 都可以,甚至 3 可能也不会太离谱,因此 1 和 2 所代表的词在词义上最好有某种共性,而不是像 "a" 和 "abandon" 一样,几乎找不到词义上的关联。当相近的词聚集到一起,推断出有效输出的概率就会更高。
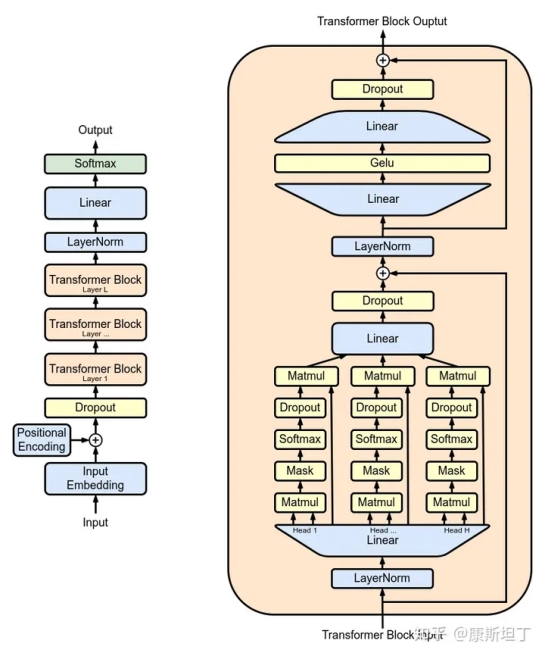
图片来源:https://en.wikipedia.org/wiki/Generative_pre-trained_transformer
—— 理解了这一点,GPT模型的最后一层就非常容易理解了。在最后一层之前,推理的对象是以向量形式表征的语义,输出的是代表语义的一个“模糊”的向量。此处“模糊”指的是,这一向量或许并不对应任何一个已知的词。因此,整个模型最后需要再做一个推测,基于这个“模糊”的向量所包含的语义信息,在词表中寻找最符合这些特征的词,来作为真正的输出。在 transformer 中,最后的输出是一个概率分布,表示每一个词匹配这一“模糊”向量的概率。
现在我们知道了性质二是必要的,在考虑这一点的基础上是否有可能再抢救一下字典编码法?比如.. 找一本近义词字典,针对相近的词赋予相近的数?
问题很快也就出现了:A 和 B 词义相似,B 和 C 词义相似,似乎并不意味着 A 和 C 词义也相近。
例如:
A = ”Love“,B = ”Passion“,C = "Rage"
A = ”Comedy“,B = ”Play“,C = "Game"
在这两个案例中,A 和 B 都是接近的,B 和 C 也是接近,但 A 和 C 却不是。问题在哪呢?
词义的多维性。
当用一个标量来表示一个词时,词和词之间的关系只能基于两个标量间的差值得到,从而只有“远”和“近”两种状态;但实际情况可能是:两个词只在某些维度上接近。 “Love” 和 “Passion” 接近的地方是:情感浓度,都表示存在强烈的情感,但是在情感色彩方面 —— 也就是消极还是积极 —— passion 具有更加中性的色彩,于是同样具有浓烈情感的 “Rage” 也与 “Passion” 相近,但是 “Rage” 的情感色彩却是消极的。
于是我们需要一个多维的数字形态,很自然会想到使用向量 ——— 对于每一个词,我们可以表达为一组数,而非一个数;这样一来,就可以在不同的维度上定义远近,词与词之间复杂的关系便能在这一高维的空间中得到表达 —— 这,就是 embedding,它的意义也就不言自明了。“嵌入”这个名字太糟糕了,不如叫它“词义向量” 吧;而词义向量所处的空间,可以称为“词义空间”。
3 如何设计编码器
目前为止,我们已经找到了可以用于表达词义的数字化形式 —— 向量,也知道了一个好的编码方式应当满足的性质。如何设计一套方法,来完成我们所期望的编码,就成了最后的问题。
一个比较容易想到的方法是,令词义的不同维度和向量不同维度进行关联。例如,对词义的维度进行全面的拆分:名词性、动词性、形容词性、数量特征、人物、主动、被动、情感色彩、情感强度、空间上下、空间前后、空间内外、颜色特征、... 只要维度的数量足够多,一定是可以把词义所包含的信息全都囊括在内;一旦我们给出每一个维度的定义,就可以给出每个词在相应维度上的数值,从而完成词的向量化,并且完美地符合以上给出的两点性质。但这个看似可行的设计,并不具备可实现性。
首先是要能够囊括所有词义的不同维度,需要维度数量必然是极高的,而要对词义进行这么精细的切分,就非常困难,其次即使切分出来了,要将每个词不同维度的意义赋予有效的数值,哪怕是资深的语言学家恐怕也会难以感到棘手。今天大家所熟知的语言模型中,并没有一个是用这一方式对词进行向量化的。但是这个思想方案却是有意义的,词义向量的不同维度之于计算机,就如同上面我们列举的维度 —— 词性、数量、时间、空间等等 —— 之于人类。
纯构建的方式不可行,今天我们也已经知道了一套有效的解决办法:神经网络加大数据暴力出奇迹。这套范式的起源于是:Word2Vec。今天语言模型,无一不是基于词义向量,而词义向量真正开始有效,正是从Word2Vec开始。
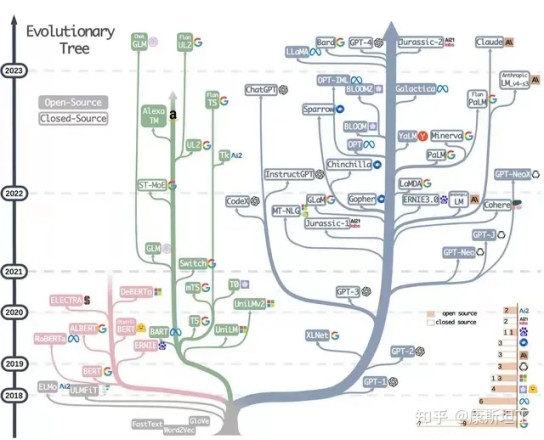
图片来源:https://github.com/Mooler0410/LLMsPracticalGuide
Word2Vec 的关键是一个重要的洞察、一个极具启发性的角度:
一个词的意义,可以被它所出现的上下文定义。
这句话换一种说法又可以表述为:上下文相似的词在词义上也一定存在相似性。想一想是不是很有道理?这个观点是语言学家 Zellig Harris 在1954 提出的“Distribution Hypothesis”,随后被广泛接受。Word2Vec 的两类做法分别是:
中心词 --> 神经网络 --> 上下文
上下文 --> 神经网络 --> 中心词
今天回头看,这个工作从一开始就注定了成功:原理上,是基于广泛接受的“Distribution Hypothesis”;方法上,使用了拟合能力强大的神经网络模型;最重要的,数据要多少有多少。
这个方法当然不是终点,它的局限性是明显的 —— 但开创性已经足够了 —— 只是利用和挖掘了“Distribution Hypothesis”的浅层结构。怎么理解这句话呢?本质上是因为Word2Vec并没有尝试去理解句子内的语义。因此对于完全相同的上下文,不同的中心词的词义相似性是容易捕捉的;当词义向量的聚类逐渐形成,由近义词构成的上下文,也一定程度上能够标记词义相近的中心词。但人类的语言结构非常复杂,当相同语义通过不同句式、语态、修辞进行表达时,某些近义词对的关系就会可能被深埋。
看看ChatGPT举的这个例子:
句子1:Driven by an insatiable thirst for knowledge, she stayed late every night, her eyes dancing across the pages of books as if they were starry skies.
句子2:Isn't it unusual, that she, prompted by an unquenchable intellectual curiosity, burns the midnight oil, pouring over pages as though navigating constellations?
两个句子都在描述一个女性深夜仍在阅读,驱使她的是对知识的无尽渴望,两句话也存在非常多意义相近的词对,在不理解语义的情况下,这些词对之间的相似性是难以被辨识的。
接下来我们可以讨论 GPT 了。
它是一个有能力理解句子的模型。如果说此前讨论的Word2Vec这类构建词义向量的模型是教计算机“认字”的过程,那么GPT模型的训练,则是一个“认字”+“背书”的过程。老师最后只考书背的好不好,但为了把书背好,GPT 也被动地强化了其认字能力。
推理的核心是transformer,transformer的核心是attention机制,attention机制是什么?一言以蔽之:计算词义向量之间的“距离”后 ,对距离近的词投向更多注意力,而收到高注意力的词义则获得更高的激活值,当预测完成后,通过反向传播算法:当特定的激活帮助了最终的预测,对应词之间关联将被强化,反之则被弱化,模型便是通过这一方式学到了词之间的关系。而在“Distribution Hypothesis”这一视角下,“认字”的实质就是认识一个词和其它词之间的关系。于是就形成了认字为了背书,背书帮助认字的结构。这里提炼一个我个人的观点:
attention 机制之所以重要和好用,原因之一是可以有效帮助词义向量(embedding)聚类。
GPT的例子想想其实很有趣,一般的工程思维是将大的问题拆成多个小的问题然后一个一个解决,正如文中开始说的那句:
让计算机理解自然语言,我们需要做什么?
计算的基础是数,而自然语言是文字,因此很容易想到要做的第一步是让文字数字化...
这个表述隐含了一个解决问题的路径:先将文字数字化后,考虑理解句子的问题。有趣的地方是:对词进行向量化编码的最好方法,是直接训练一个理解句子的语言模型;这就像为了让婴儿学会走路,我们直接从跑步开始训练。人类会摔跤会受伤,但机器不会 —— 至少在embodied之前不会,因此人类为了降低代价所建立的步骤化学习过程或许并不适合人工智能 —— 也不难发现,深度学习中,许多好的解决方案往往都是一步到位的。
4 后记
这篇文章把我关于语言模型中embedding的理解都写完了。但,embedding 还不止这些。图像可以有embedding,句子和段落也可以有 embedding —— 本质都是通过一组数来表达意义。段落的 embedding 可以作为基于语义搜索的高效索引,AI 绘画技术的背后,有着这两种 embedding 的互动 —— 未来如果有一个大一统的多模态模型,embedding 必然是其中的基石和桥梁 。
由 AI 掀起的时代浪潮毫无疑问地要来了,今天是一个还难以看清未来的节点。当下能做的为数不多的事情之一还是保持学习。
出自:https://zhuanlan.zhihu.com/p/643560252
和大部分人一样,我对自然语言处理和语言模型的了解从ChatGPT开始。
和大部分人一样,第一次接触就被ChatGPT的能力所震惊 —— 计算机确实做到了理解人类的语言。
我也产生了几乎人人都会有的疑问:怎么做到的?
这篇文章中,我并不试图去解释ChatGPT的一切,而是将从原理出发,思考计算机理解语言的关键要素,这些思考落到了一个具体的切入点 —— embedding —— 一个第一眼难以理解但极为关键的东西。
文章是一个门外汉通过业余的研究和碎片的思考所完成,谬误之处难以避免,欢迎专业的研究人员指正。
1 编码:文字的数字化
Embedding 这个词直译为中文是:嵌入,这是让人头秃的两个字 —— 啥是嵌入?嵌入了啥?跟自然语言又有啥关系?它的体现形式是一组具有固定长度的数组,或者叫做向量,但它究竟是什么?为什么需要它?它在计算机理解自然语言的过程中扮演的是怎样的角色呢?
要回答这些问题,不妨先思考:让计算机理解自然语言,我们需要做什么?
计算的基础是数,而自然语言是文字,因此很容易想到要做的第一步是让文字数字化,为行文方便,我们将这个过程叫做编码。要设计编码的方法,自然需要思考的问题是:哪些性质是编码规则必须要满足的?
有一条是显然可以给出的:
性质一:每一个词具有唯一量化值,不同词需要具有不同的量化值
背后的逻辑不言自明:一词多数,或是多词一数,都会增加计算机理解语言的难度,这种难度就如同多音字或是多义词给人类造成的困难,尽管人类的智慧让我们可以克服这些障碍,但对于仍然处于培育智能阶段的计算机,为它降低一些难度显然是必要的。
满足性质一的方法非常容易设计,例如:首先穷举出人类所有的文字或词组 —— 这个集合必定是有限集,例如汉字有10万个,辞海收录的词大概60万个,字母有26个,英语单词数小于100万个 ——— 由于是有限集,我们可以给每一个词分配一个固定的数字,例如打开一个词典,将遇到的单词依次赋予一个不同的数值:
A --> 1
Abandon --> 2
Abnormal --> 3
... |
这便完成了符合性质一的编码。例如 "Hello World" 这句话就可以作为 ”3942 98783“ 这样的数字序列输入,从而可以被计算机处理。但这一方法的问题是显然的:
数的值与词的义是割裂的。
这种割裂会产生什么问题?可以通过一个简单的例子来思考:在英语中,a 和 an 是完全同质的词,而 a 和 abnormal 则是差异极大的词。如果按照上述编码方式, a 可能会被赋予数值1,abnormal会被赋予数值2,an 会被赋值赋予数值 123 ,这个时候我们可能会发现 a 和 abnormal 似乎在数值上更加靠近,而 a 和 an 这两个同质的词却隔得非常远。这时容易想到要添加一条性质,来确保数字化后的数值与词义之间的关联:
性质二:词义相近词需要有"相近"的量化值;词义不相近的词量化值需要尽量“远离”
2 基于词义的编码
上面的例子中虽然提到了字典编码法会割裂数值和词义,却未能解释为什么数值和词义应该关联 —— 基于直觉的思考会认为这一点是显然的,但模糊的显然容易掩埋值得被清晰梳理的逻辑。我能够想到的原因有两个:
00001. 可以帮助更加高效理解语义;
00002. 允许计算模型的设计有更大的自由度。
第1条怎么理解?如果说词的数值分布与词义无关,这会使得文本的序列变得过于随机,例如:
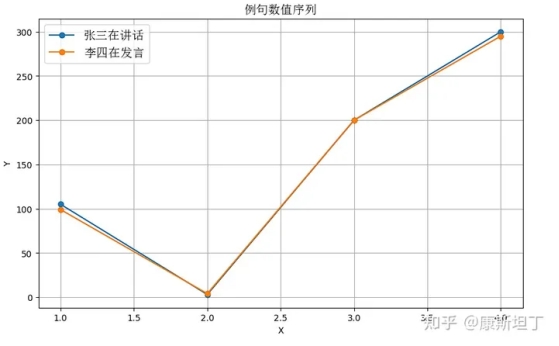
句子一:张三在讲话。
句子二:李四在发言。
这两句话有着非常强的同质性,但如果对于字/词的编码不符合性质二,这就会使得以上两句话的序列特征会有非常大的差异。以下的例子或许足够直观:
如果近义词具有相近的量化值,词和值之间的关系或许会是这样,看起来就是相似的形状:
张 --> 105, 李 --> 99
三 --> 3, 四 --> 4
在 --> 200,
讲话 --> 300, 发言 --> 295 |
而如果近义词具有不相近的量化值,词和值之间的关系或许会是这样,一眼看上去似乎没什么关系:
张 --> 33, 李 --> 1
三 --> 5, 四 --> 200
在 --> 45,
讲话 --> 2, 发言 --> 42 |
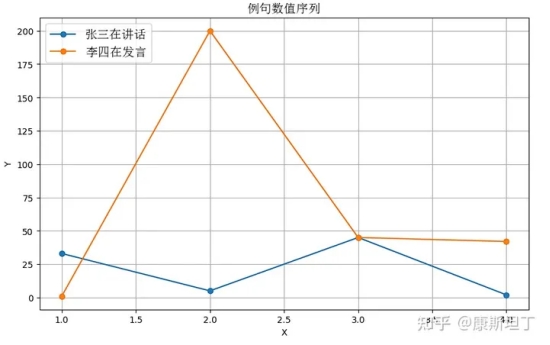
换言之,当性质二得到满足时,同义的句子在序列特征上会更加接近,这将有利于计算机而言更高效地理解共性、区分特性;反之则会给计算机制造非常多的困难。难以捕捉同质内容之间的共性,就意味着模型需要更多的参数才能描述同等的信息量,学习的过程显然困难也会更大。OpenAI 的 Jack Rae 在 Standford 的分享 中提到了一个很深刻的理解语言模型的视角:
语言模型就是一个压缩器。
这个观点已有不少文章都做了阐释[1][2]。所有的压缩,大抵都能被概括在以下框架内:提取共性,保留个性,过滤噪声。带着这个视角去看,就更加容易认识到性质二的必要性。不同词所编码的数值,是否基于词义本身的相似性形成高区分度的聚类,会直接影响到语言模型对于输入数据的压缩效率。
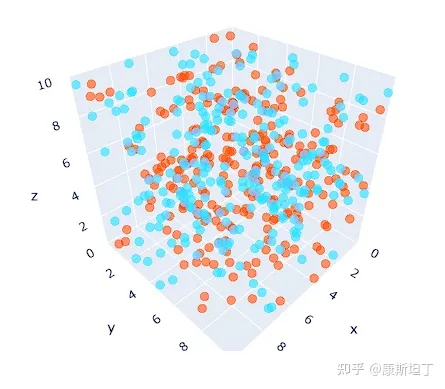
编码值未基于词义形成聚类
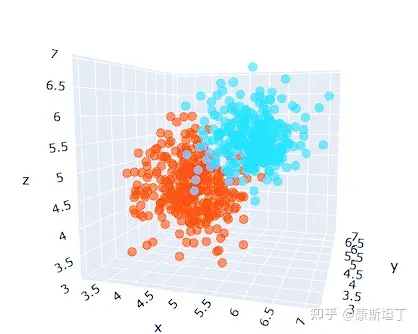
编码值基于词义形成聚类
第2条怎么理解?
因为词是离散分布的,而计算模型的输出 —— 除非只使用非常简单的运算并且约束参数的权重 —— 很难恰好落在定义好的量化值中。对于神经网络模型,每一个节点、每一层都必须是连续的,否则便无法计算梯度从而无法应用反向传播算法。这两个事实放在一起可能会出现的情况是:词的量化值可以全部是整数,但是语言模型的输出不一定。例如当模型输出 1.5,词表只定义了 1 和 2,这时该如何处理呢?我们会希望 1 和 2 都可以,甚至 3 可能也不会太离谱,因此 1 和 2 所代表的词在词义上最好有某种共性,而不是像 "a" 和 "abandon" 一样,几乎找不到词义上的关联。当相近的词聚集到一起,推断出有效输出的概率就会更高。
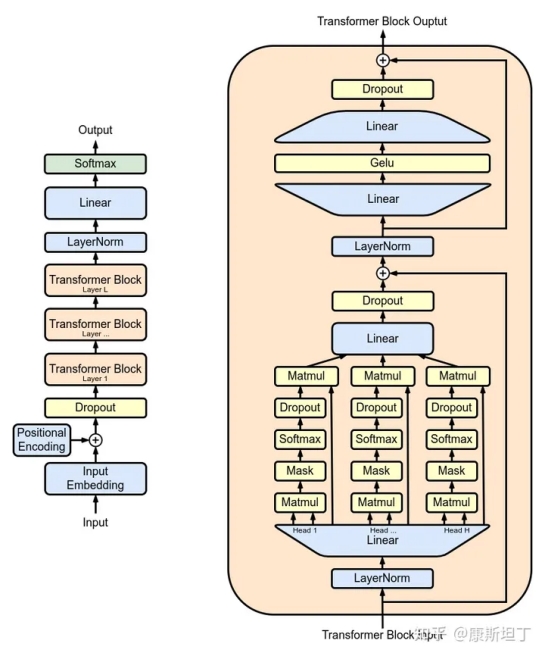
图片来源:https://en.wikipedia.org/wiki/Generative_pre-trained_transformer
—— 理解了这一点,GPT模型的最后一层就非常容易理解了。在最后一层之前,推理的对象是以向量形式表征的语义,输出的是代表语义的一个“模糊”的向量。此处“模糊”指的是,这一向量或许并不对应任何一个已知的词。因此,整个模型最后需要再做一个推测,基于这个“模糊”的向量所包含的语义信息,在词表中寻找最符合这些特征的词,来作为真正的输出。在 transformer 中,最后的输出是一个概率分布,表示每一个词匹配这一“模糊”向量的概率。
现在我们知道了性质二是必要的,在考虑这一点的基础上是否有可能再抢救一下字典编码法?比如.. 找一本近义词字典,针对相近的词赋予相近的数?
问题很快也就出现了:A 和 B 词义相似,B 和 C 词义相似,似乎并不意味着 A 和 C 词义也相近。
例如:
A = ”Love“,B = ”Passion“,C = "Rage"
A = ”Comedy“,B = ”Play“,C = "Game"
在这两个案例中,A 和 B 都是接近的,B 和 C 也是接近,但 A 和 C 却不是。问题在哪呢?
词义的多维性。
当用一个标量来表示一个词时,词和词之间的关系只能基于两个标量间的差值得到,从而只有“远”和“近”两种状态;但实际情况可能是:两个词只在某些维度上接近。 “Love” 和 “Passion” 接近的地方是:情感浓度,都表示存在强烈的情感,但是在情感色彩方面 —— 也就是消极还是积极 —— passion 具有更加中性的色彩,于是同样具有浓烈情感的 “Rage” 也与 “Passion” 相近,但是 “Rage” 的情感色彩却是消极的。
于是我们需要一个多维的数字形态,很自然会想到使用向量 ——— 对于每一个词,我们可以表达为一组数,而非一个数;这样一来,就可以在不同的维度上定义远近,词与词之间复杂的关系便能在这一高维的空间中得到表达 —— 这,就是 embedding,它的意义也就不言自明了。“嵌入”这个名字太糟糕了,不如叫它“词义向量” 吧;而词义向量所处的空间,可以称为“词义空间”。
3 如何设计编码器
目前为止,我们已经找到了可以用于表达词义的数字化形式 —— 向量,也知道了一个好的编码方式应当满足的性质。如何设计一套方法,来完成我们所期望的编码,就成了最后的问题。
一个比较容易想到的方法是,令词义的不同维度和向量不同维度进行关联。例如,对词义的维度进行全面的拆分:名词性、动词性、形容词性、数量特征、人物、主动、被动、情感色彩、情感强度、空间上下、空间前后、空间内外、颜色特征、... 只要维度的数量足够多,一定是可以把词义所包含的信息全都囊括在内;一旦我们给出每一个维度的定义,就可以给出每个词在相应维度上的数值,从而完成词的向量化,并且完美地符合以上给出的两点性质。但这个看似可行的设计,并不具备可实现性。
首先是要能够囊括所有词义的不同维度,需要维度数量必然是极高的,而要对词义进行这么精细的切分,就非常困难,其次即使切分出来了,要将每个词不同维度的意义赋予有效的数值,哪怕是资深的语言学家恐怕也会难以感到棘手。今天大家所熟知的语言模型中,并没有一个是用这一方式对词进行向量化的。但是这个思想方案却是有意义的,词义向量的不同维度之于计算机,就如同上面我们列举的维度 —— 词性、数量、时间、空间等等 —— 之于人类。
纯构建的方式不可行,今天我们也已经知道了一套有效的解决办法:神经网络加大数据暴力出奇迹。这套范式的起源于是:Word2Vec。今天语言模型,无一不是基于词义向量,而词义向量真正开始有效,正是从Word2Vec开始。
图片来源:https://github.com/Mooler0410/LLMsPracticalGuide
Word2Vec 的关键是一个重要的洞察、一个极具启发性的角度:
一个词的意义,可以被它所出现的上下文定义。
这句话换一种说法又可以表述为:上下文相似的词在词义上也一定存在相似性。想一想是不是很有道理?这个观点是语言学家 Zellig Harris 在1954 提出的“Distribution Hypothesis”,随后被广泛接受。Word2Vec 的两类做法分别是:
中心词 --> 神经网络 --> 上下文
上下文 --> 神经网络 --> 中心词
今天回头看,这个工作从一开始就注定了成功:原理上,是基于广泛接受的“Distribution Hypothesis”;方法上,使用了拟合能力强大的神经网络模型;最重要的,数据要多少有多少。
这个方法当然不是终点,它的局限性是明显的 —— 但开创性已经足够了 —— 只是利用和挖掘了“Distribution Hypothesis”的浅层结构。怎么理解这句话呢?本质上是因为Word2Vec并没有尝试去理解句子内的语义。因此对于完全相同的上下文,不同的中心词的词义相似性是容易捕捉的;当词义向量的聚类逐渐形成,由近义词构成的上下文,也一定程度上能够标记词义相近的中心词。但人类的语言结构非常复杂,当相同语义通过不同句式、语态、修辞进行表达时,某些近义词对的关系就会可能被深埋。
看看ChatGPT举的这个例子:
句子1:Driven by an insatiable thirst for knowledge, she stayed late every night, her eyes dancing across the pages of books as if they were starry skies.
句子2:Isn't it unusual, that she, prompted by an unquenchable intellectual curiosity, burns the midnight oil, pouring over pages as though navigating constellations?
两个句子都在描述一个女性深夜仍在阅读,驱使她的是对知识的无尽渴望,两句话也存在非常多意义相近的词对,在不理解语义的情况下,这些词对之间的相似性是难以被辨识的。
接下来我们可以讨论 GPT 了。
它是一个有能力理解句子的模型。如果说此前讨论的Word2Vec这类构建词义向量的模型是教计算机“认字”的过程,那么GPT模型的训练,则是一个“认字”+“背书”的过程。老师最后只考书背的好不好,但为了把书背好,GPT 也被动地强化了其认字能力。
推理的核心是transformer,transformer的核心是attention机制,attention机制是什么?一言以蔽之:计算词义向量之间的“距离”后 ,对距离近的词投向更多注意力,而收到高注意力的词义则获得更高的激活值,当预测完成后,通过反向传播算法:当特定的激活帮助了最终的预测,对应词之间关联将被强化,反之则被弱化,模型便是通过这一方式学到了词之间的关系。而在“Distribution Hypothesis”这一视角下,“认字”的实质就是认识一个词和其它词之间的关系。于是就形成了认字为了背书,背书帮助认字的结构。这里提炼一个我个人的观点:
attention 机制之所以重要和好用,原因之一是可以有效帮助词义向量(embedding)聚类。
GPT的例子想想其实很有趣,一般的工程思维是将大的问题拆成多个小的问题然后一个一个解决,正如文中开始说的那句:
让计算机理解自然语言,我们需要做什么?
计算的基础是数,而自然语言是文字,因此很容易想到要做的第一步是让文字数字化...
这个表述隐含了一个解决问题的路径:先将文字数字化后,考虑理解句子的问题。有趣的地方是:对词进行向量化编码的最好方法,是直接训练一个理解句子的语言模型;这就像为了让婴儿学会走路,我们直接从跑步开始训练。人类会摔跤会受伤,但机器不会 —— 至少在embodied之前不会,因此人类为了降低代价所建立的步骤化学习过程或许并不适合人工智能 —— 也不难发现,深度学习中,许多好的解决方案往往都是一步到位的。
4 后记
这篇文章把我关于语言模型中embedding的理解都写完了。但,embedding 还不止这些。图像可以有embedding,句子和段落也可以有 embedding —— 本质都是通过一组数来表达意义。段落的 embedding 可以作为基于语义搜索的高效索引,AI 绘画技术的背后,有着这两种 embedding 的互动 —— 未来如果有一个大一统的多模态模型,embedding 必然是其中的基石和桥梁 。
由 AI 掀起的时代浪潮毫无疑问地要来了,今天是一个还难以看清未来的节点。当下能做的为数不多的事情之一还是保持学习。
出自:https://zhuanlan.zhihu.com/p/643560252
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip


 试着问问
试着问问