为了深入探索大语言模型的发展历程,我们精心挑选了一系列经典论文进行分享,希望能与大家共同学习和理解大语言模型背后的技术。首期,我们将共同探索ChatGPT的起源:GPT-1,跟随论文深入理解其技术细节,见证人工智能新篇章的启幕。
为了深入探索大语言模型的发展历程,我们精心挑选了一系列经典论文进行分享,希望能与大家共同学习和理解大语言模型背后的技术。首期,我们将共同探索ChatGPT的起源:GPT-1,跟随论文深入理解其技术细节,见证人工智能新篇章的启幕。
摘要
GPT-1是一种半监督的语言模型,它巧妙地结合了无监督预训练和有监督微调,以优化语言理解任务。其目标是学习一种通用的语言表示,只需微调,就能在各种任务中灵活迁移。GPT-1首先利用大量未标注文本进行预训练,然后针对特定任务进行有监督的微调。它采用了Transformer作为模型架构,这种架构提供了更加结构化的记忆,以便处理文本中的长期依赖关系,从而实现了卓越的迁移性能。在迁移训练过程中,GPT1能够在最小化模型结构更改的同时,有效地进行微调。
GPT-1基本原理
GPT-1模型主要包含两个阶段:
1.利用大量未标注的语料预训练一个语言模型;
2.对预训练好的语言模型进行微改,将其迁移到各种有监督的NLP任务,并对参数进行fine-tuning。
无监督预训练
给定一个无标记的大语料库u,GPT-1通过最大化以下似然函数来训练语言模型:
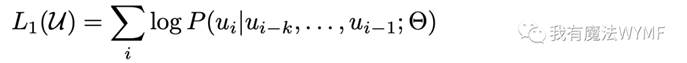
其中, k 是上下文窗口的大小。
GPT-1使用12层的Transformer解码器作为语言模型,模型结构如下所示:
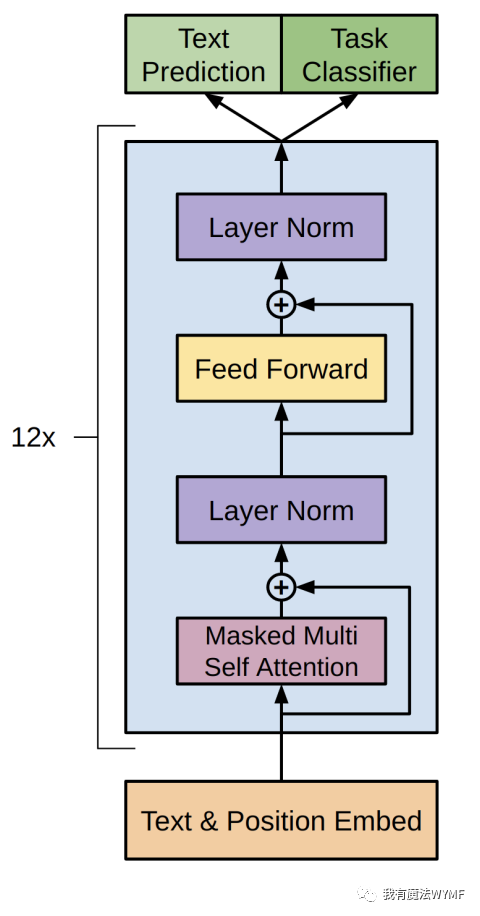
计算过程如下所示:
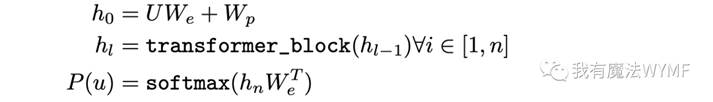
其中,U=(u-k,...,u-1)是上下文向量,n 是层数。
有监督微调
在预训练模型之后,我们在有监督的NLP任务上对预训练模型进行微调。假设有一个带有标签的数据集C,其中每个样本由一系列输入x1,...,xm以及一个标签y组成。对于每一个输入,经过预训练后的语言模型后,可以直接选取最后一层Transformer的输出向量h,然后在其后面接一层全连接层,即可得到最后的预测概率:
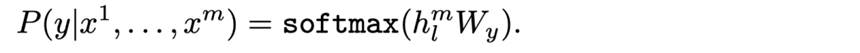
其中,Wy为全连接层的权重参数,最大化目标函数如下所示:
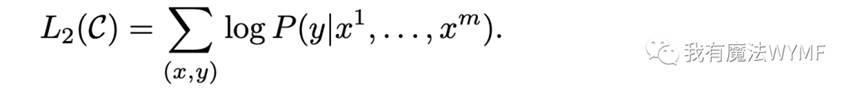
在具体的NLP任务中,作者发现在fine-tuning时把语言模型的目标作为辅助目标引入到目标函数中有助于学习,具体表现为:
1.改进了有监督模型的泛化能力
2.加速了收敛速度。
具体而言,将优化一下目标,形式如下所示:
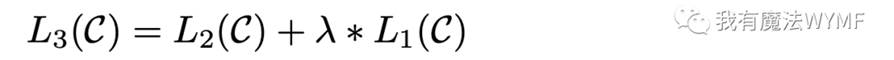
不过,对于某些任务,如文本分类,我们可以直接微调模型。
但对于其他任务,如问答或文本蕴含,输入是结构化的,如有序的句子对或文档、问题和答案的三元组。
为了适应这些任务,GPT-1将结构化输入转换为预训练模型可以处理的有序序列,以避免大量修改模型架构。
所有的输入转化都要添加起始和结束标记。
文本分类 对于文本分类任务,可以直接微调模型。

文本蕴含 对于文本蕴含任务,我们将前提(premise)和假设(hypothesis)连接起来,并在中间添加一个分隔符$。

相似性 对于相似性任务,两个待比较的句子没有固定的顺序。为了反映这一点,修改输入序列,包含两种可能的句子顺序,并将它们分别处理生成两个序列表示,然后将它们相加后输入到线性输出层中。

问答和常识推理 对于这些任务,我们给定一个上下文文档z、一个问题q和一组可能的答案{ak}。我们将文档上下文和问题与每个可能的答案连接起来,中间添加一个分隔符$。然后,分别处理这些序列[z; q; $; ak],并通过softmax层生成答案的输出分布。

出自:https://mp.weixin.qq.com/s/vXAZqU7LCSPYt-Y2r2NIOw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip