最近帮朋友实现了一个公积金Agent,能够基于公积金政策回答用户的问题,踩了一些坑,分享出来,以飨读者。
最近帮朋友实现了一个公积金Agent,能够基于公积金政策回答用户的问题,踩了一些坑,分享出来,以飨读者。
在实际的生产环境中,此类知识库应用可能遇到两类问题:知识型和政策型(图1)。
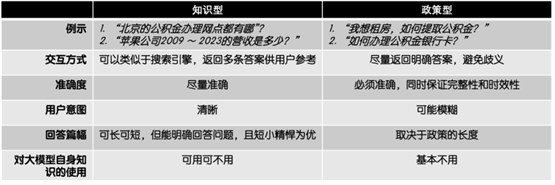
图1: 知识型问题 vs 政策型问题
相较于知识型问题,政策型问题对于知识库应用判定用户意图的能力和回答的准确性上有着近乎苛刻的要求:
100%的准确。基于交互的严肃性,应用输出内容必须能够达到100%的准确,尤其是在针对政策类、法规类和操作手册类文档。“100%的准确”不仅仅包括输出内容的正确性,还包括内容的完整性和时效性。
判定用户的真实意图。很多情况下,用户初始的意图是模糊的,应用必须有能力“追问”或“应对追问”,引导用户找到目标答案。知识型问答中常见的“一问一答”显然无法满足该需求。
那么,基于大模型Finetune和Langchain的知识库应用是否可以满足政策类问题的需求呢?
经过实践,我们抛弃了这两种方案。

抛弃Finetune和Langchain
我们首先排除了Finetune(FT)方式。排除FT的原因不仅仅出于训练数据准备的繁琐和额外的训练成本,而更是因为FT在“Factual Recall”类型任务上的不可靠。实际上,OpenAI早在去年就抛出类似的观点:

GPT can learn knowledge in two ways:
Via model weights (i.e., fine-tune the model on a
training set)
Via model inputs (i.e., insert the knowledge into
an input message)
Although fine-tuning can feel like the more natural
option—training on data is how GPT learned all of its other knowledge, after
all—we generally do not recommend it as a way to
teach the model knowledge. Fine-tuning is
better suited to teaching specialized tasks or styles, and is less reliable for
factual recall.

对于“Factual Recall”类型任务,OpenAI更倾向于Emedding Search。显然FT不是回答政策类问题的最佳方案。
之后,我们“干掉了”Langchain。Langchain + Vectorstore + LLMs是当下最“主流”的知识库方案。但在提升回答的准确度方面,该方案存在一些致命的缺陷,通过分解Langchain的架构,我们可以看到(图2):
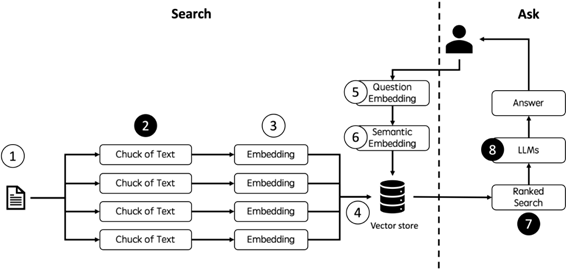
图2: Langchain + Vectorstore + LLMs
首先,在第2步,Langchain的全自动文件切片(Chunk)无法保证语义的准确性。无论如何设置,Langchain的文件切片工具:RecursiveCharacterTextSplitter或CharacterTextSplitter都可能将位置上相邻、但语义上应当区隔的内容放到一个切片中,从而导致最终回答中出现不相干、甚至相反的内容。
其次,在第7步,Langchain无法依据不同的问题提取合适数量的切片。即使切片内容准确,不同问题对切片数量的要求也不同。例如,用1个切片就可以回答诸如“我有租房发票,如何在北京进行线下公积金提取?”等比较明确问题,而需要用更多的切片回答“我想买房,如何提取公积金?”之类较为概括性的问题。Langchain并不具备依据不同的问题来提取不同数量的切片的能力。
再次,在第8步,Langchain将已经很精准的答案送往大模型纯属“画蛇添足”。对于政策型问题,往往原文已经是最佳答案,而大模型对原文的“二次加工”将破坏其语义和完整性,导致准确度下降。
上述原因让我们“抛弃”了FT和Langchain,并改向基于大模型的Classification能力,通过“追问型”Agent满足“政策型”文档问答的需求。
“追问型”Agent
通常而言,对于政策型问题,用户的初始问题和最终其想要的答案之间可能存在鸿沟,而追问就是弥补鸿沟,并提升回答准确性的有效手段。例如,我和HR专员可能有这样的对话:

我:租房能取公积金吗?
HR专员:可以,租房提取公积金需要你的公积金缴存满三个月,且没有自有住房。满足条件的话,你可以申请。你在哪租房?
我:海淀。
HR专员:你有租房发票吗?
我:有。
HR专员:你打算网上申请还是去网点?
我:网申吧,省得麻烦...
HR专员:好,这是网申的方法....

实际上HR专员的脑中有一棵“决策树”,通过不断的“追问”,其可以在决策树中选择正确的路径并最终反馈给我准确的材料。
而模拟这个过程将能够有效提升Agent对政策型问题回答的准确性。受到Autonomous Agent架构的启发(图3),我们将模拟过程切分为三步:
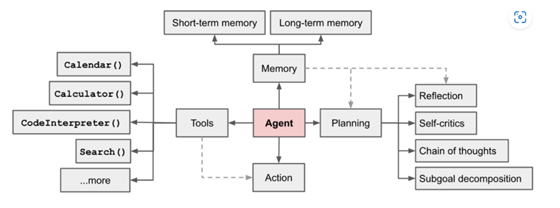
图3. Agent架构
第一步,构建决策树(Planning)。政策型文档往往本身蕴含着知识图谱-决策树,而Agent的工作是将其清晰地描绘出来以应对和引导用户的意图,例如,对于公积金租房场景,Agent可以构建一棵这样的决策树(图4):

图4:租房场景决策树
第二步,挂接知识(Memory)。对于决策树中的每一个节点,Agent都可以挂接一个或者多个知识(文档切片)。这些切片就像是Agent的Short-term Memory,帮助Agent回答问题。我们需要保证挂接切片的准确性,以实现“只要Agent能够正确判断用户的意图,就能反馈准确的内容”(图5)。
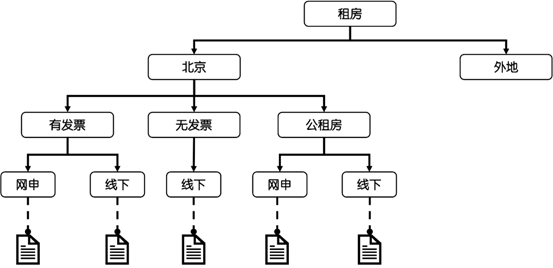
图5:决策挂接文档切片
第三步,使用大模型判断用户意图(Action)。这是最关键的一步,Agent使用大模型的Classification能力不断将用户的意图分类为决策,继而使用其下级节点向用户进行追问,并引导用户找到准确的答案(图6)。
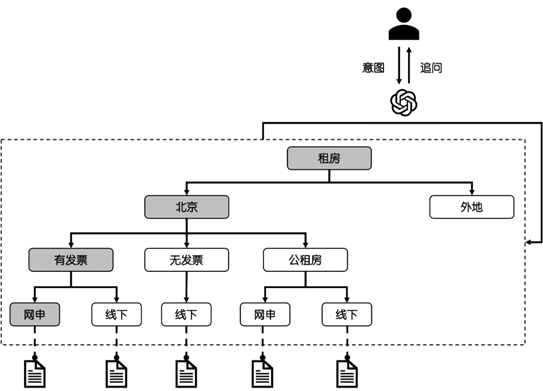
图6: 大模型判断用户意图,并分类为决策
我们可以看一个实际的例子:
,时长01:24
相同的问题,如果使用Langchain,我们得到的回答是这样的(图7):
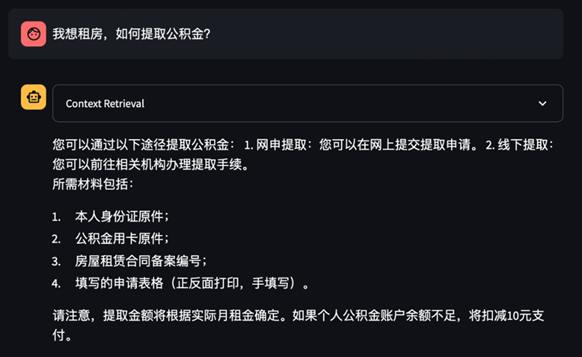
图7:Langchain的回答
这个回答看似正确,实则只是从“喂”进去的切片中随机反馈了一些信息,其忽略了一些关键决策点,并且提供的内容也不准确。这距离政策型问题对答案的要求实在是太远了。
总结
相较于Langchain,“追问型”Agent有如下的特点:
·
准确度极大提升。只要能正确判断用户的意图,就能提供准确的内容。此外,追问的方式也能保证Agent所提供的内容都经由用户确认,避免了胡说的情况。
·
相对安全。Agent并不将文件切片送往大模型,而只是利用大模型作为决策引擎,文档对外的暴露面极小,提升了安全性。
·
灵活。虽然该Agent的使用体验类似于电话客服,但是其决策过程(Planning & Action)是动态的,即基于用户的问题,Agent可以动态计划、动态决策,例如,用户可以从“我想租房”问起,也可以从“如何网申”,甚至从“我有发票”问起,该机制给予用户极大的灵活性。
·
成本低。决策所需要的Token量级远远低于Langchain推送文档切片所需的Token量级,可以省不少钱。
当然该Agent也有一些局限性,例如,Agent的决策能力非常依赖于大模型的Classification的能力,同时,文档的预处理,例如决策树的构建,也暂时无法做到100%的自动化。
但是,我们相信,伴随着大模型能力的不断提升,完美的“追问型”Agent并不遥远。
出自:https://mp.weixin.qq.com/s/OVpgw2lifDn8s74dQQRe1Q
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip