①chatglm3-6b有哪些亮点?有什么新功能?
②手把手!0基础把他部署下来!试试是不是那么玄乎!
10月27日,国内大模型提供商首例!现场开演示发布会的!看起来信心满满!
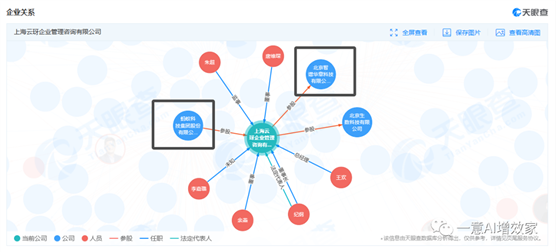
蚂蚁集团全资子公司:上海云玡企业管理咨询有限公司,10月16号正式入股智谱!被资本选中的人,跑得不会慢!
话不多说!今天就这2点分享:
①chatglm3-6b有哪些亮点?有什么新功能?
②手把手!0基础把他部署下来!试试是不是那么玄乎!
明天抽空,再详细测测工具调用、Agent的具体性能!一定要跟进啊!
第一部分:chatglm3-6b有哪些亮点?功能?
也是六点多,公司伙伴说已经上传完成了,雄哥刚到家吃完饭,也就十多分钟,就部署完了!
看完整个宣发文案,雄哥觉得最大的亮点!不是1000%性能提升!或者更多的功能!是最底部的几行小字:
自2022年初,GLM 系列模型已支持在昇腾、神威超算、海光 DCU 架构上进行大规模预训练和推理,当前已支持10余种国产硬件生态,包括昇腾、神威超算、海光DCU、海飞科、沐曦曦云、算能科技、天数智芯、寒武纪、摩尔线程、百度昆仑芯、灵汐科技、长城超云等。通过与国产芯片企业的联合创新,性能不断优化,期待有一天国产原生大模型与国产芯片能够在国际舞台上闪光。
相信前几天漂亮国将一众业内公司录入“实体名单”,大家都义愤填膺!
一心想学部署的,直接移动到第二部分!
1. 更强大的性能:
评测显示,与 ChatGLM 二代模型相比,在44个中英文公开数据集测试中,ChatGLM3在国内同尺寸模型中排名首位。其中,MMLU提升36%、CEval提升33%、GSM8K提升179% 、BBH提升126%。
2. 瞄向GPT-4V的技术升级:
瞄向GPT-4V,ChatGLM3 本次实现了若干全新功能的迭代升级,包括:
多模态理解能力的CogVLM,看图识语义,在10余个国际标准图文评测数据集上取得SOTA;
代码增强模块 Code Interpreter 根据用户需求生成代码并执行,自动完成数据分析、文件处理等复杂任务;
网络搜索增强WebGLM,接入搜索增强,能自动根据问题在互联网上查找相关资料并在回答时提供参考相关文献或文章链接。
ChatGLM3的语义能力与逻辑能力大大增强。
3. 全新的 Agent 智能体能力:
ChatGLM3 本次集成了自研的 AgentTuning 技术,激活了模型智能体能力,尤其在智能规划和执行方面,相比于ChatGLM二代提升 1000% ;开启国产大模型原生支持工具调用、代码执行、游戏、数据库操作、知识图谱搜索与推理、操作系统等复杂场景。
4. Edge端侧模型:
ChatGLM3 本次推出可手机部署的端测模型 ChatGLM3-1.5B 和 ChatGLM3-3B,支持包括Vivo、小米、三星在内的多种手机以及车载平台,甚至支持移动平台上 CPU 芯片的推理,速度可达20 tokens/s。精度方面 ChatGLM3-1.5B 和 ChatGLM3-3B 在公开 Benchmark 上与 ChatGLM2-6B 模型性能接近。
5. 更高效推理/降本增效:
基于最新的高效动态推理和显存优化技术,我们当前的推理框架在相同硬件、模型条件下,相较于目前最佳的开源实现,包括伯克利大学推出的 vLLM 以及 Hugging Face TGI 的最新版本,推理速度提升了2-3倍,推理成本降低一倍,每千 tokens 仅0.5分,成本最低。
第二部分:手把手!0基础把他部署下来!
默认情况下,模型以 FP16 精度加载,需要大概 13GB 显存!显存不够的!在知识星球,等等雄哥的量化版吧!或者云部署!
整个过程非常的简单!
①下载模型权重、②下载依赖、③安装部署环境、④启动推理!
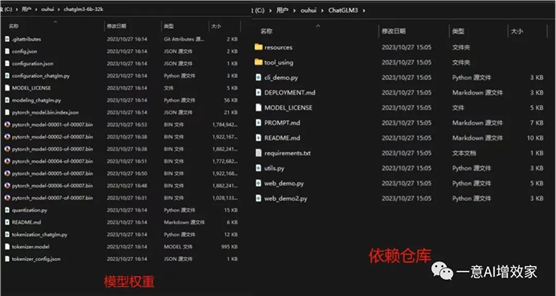
2.1 下载模型权重+下载依赖
模型权重+仓库依赖,同步上传到知识星球会员独享专用网盘,快去下载!
价值内容是会员专属的!
如果你是非星球会员,可以在这里申请加入,在这个浪潮中!一起踏浪!
也可后台直接回复:“glm3”获取下载链接!
2.3 安装部署环境
整个部署过程是基于CUDA、win11系统,miniconda环境实践的!如果你是MAC、CPU环境,请留言吧!下次雄哥再出!
之前雄哥已经详细教过怎样搭建环境了,自行去搭!
第四天!0基础微调大模型+知识库,部署在微信!手把手安装AI必备环境!4/45
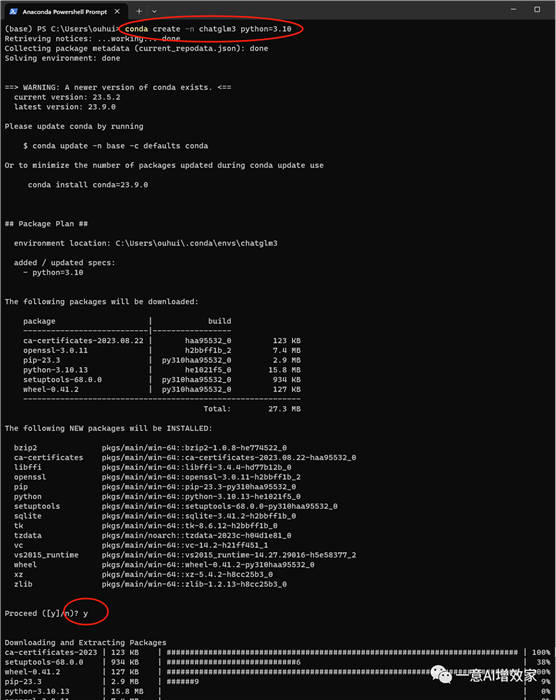
现在,先在miniconda创建一个python3.10的虚拟环境!
名字:chatglm3
·
conda create -n chatglm3 python=3.10
激活刚刚创建的环境
·
conda activate chatglm3
然后,我们要进入到下载依赖的目录中(不能有中文或空格)
你如果是保存在其他目录,要把路径替换一下!
·
cd ChatGLM3
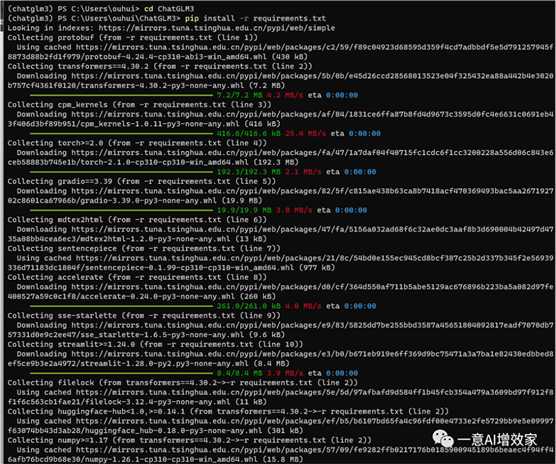
开始安装依赖!
这里雄哥已经替换了国内的镜像源,速度非常快!如果你这一步出错了!
进群里反馈吧!
·
pip install -r requirements.txt
接下来,我们要准备启动了!改启动模型路径!
把下载的模型权重放到启动目录中!然后打开web_demo2.py!

把原先的路径删掉,改为以下名字,否则他会自动在网上重新下载模型!
如果你放在其他地方,请你把绝对路径填上去,并且用反斜杠表示路径!
·
·
tokenizer = AutoTokenizer.from_pretrained("chatglm3-6b-32k", trust_remote_code=True) model = AutoModel.from_pretrained("chatglm3-6b-32k", trust_remote_code=True).cuda()
智谱说做了一个比vllm还快的推理框架,我们试试!开始启动!
回到环境中,输入启动命令!回车!
·
streamlit run web_demo2.py
他会自动在浏览器打开对话UI!
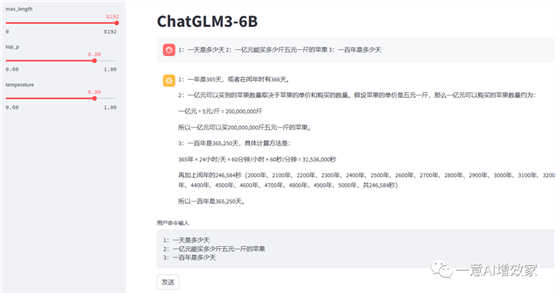
先问一个简单的吧!
1:一天是多少天
2:一亿元能买多少斤五元一斤的苹果
3:一百年是多少天
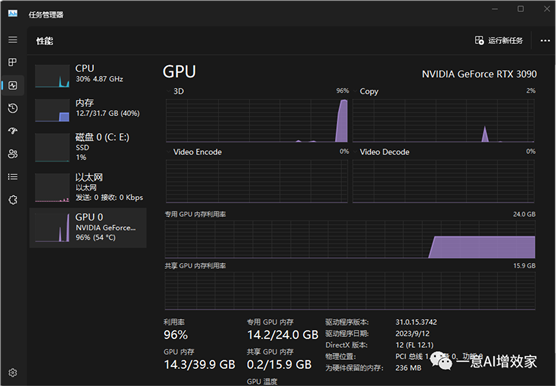
家里的电脑3090显卡,未量化,占用显存14G!
出自:https://mp.weixin.qq.com/s/md6nqITrsFjZkYbFsT-NYg
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip