AI“同声传译”新进展!Google发布,无监督,语音识别:Translatotron 3!
前有Meta发布eamless-communication,后又Google发布最新研究成果:Translatotron 3!

Translatotron
3解决了什么问题?
语音识别(ASR)是指将人类的语音转换为文本的技术,然而,目前的语音识别技术还面临着一些挑战,其中最大的一个就是如何支持更多的语言。
据统计,世界上有超过7000种语言,但是目前的语音识别系统只能覆盖其中的一小部分,而且对于一些低资源语言,由于缺乏足够的标注数据,训练高质量的语音识别模型非常困难。
因此,如何利用无标注的语音数据和文本数据,实现无监督的语音识别,是一个非常有价值的研究方向。
Translatotron 3怎么样?
近日,Google研究团队在其博客上发布了一篇文章,介绍了他们的最新研究成果:无监督语音到语音(Unsupervised Speech-to-Speech,简称USS)AI模型。
这是一个基于自监督学习和对抗学习的端到端的语音识别系统,它可以从没有任何标注的语音数据和文本数据中学习,支持100多种语言的语音识别,包括一些低资源语言,例如阿姆哈拉语、宿务语、阿萨姆语和阿塞拜疆语等。
该模型的性能在一些公开的语音识别数据集上达到了与有监督学习相当甚至超越的水平,展示了无监督语音识别的巨大潜力。
Translatotron 3如何做到的?
Translatotron 3结合了三种技术:掩码自编码器、无监督的嵌入映射、和反向翻译,来实现这个目标。
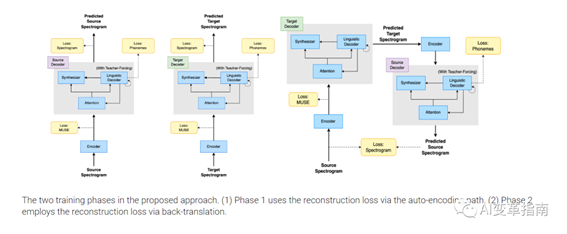
掩码自编码器(Masked Autoencoder):这是一种可以从语音信号中提取有用的信息,同时去除无关的信息的模型。
它的原理是,把输入的语音信号随机地掩盖一些部分,然后让模型尝试重建完整的语音信号。
这样,模型就可以学习到语音信号中的结构和含义,而不是简单地复制输入。这种模型可以用单语言的语音-文字数据集来训练,不需要有双语言的语音数据集。
无监督的嵌入映射(Unsupervised Embedding Mapping):这是一种可以把不同语言的语音或文字的内部表示,映射到一个共同的空间的方法。
它的原理是,利用一些无监督的损失函数,来度量不同语言的语音或文字的相似性,然后让模型尝试最小化这些损失函数。这样,模型就可以学习到不同语言的语音或文字的对应关系,而不需要有双语言的配对数据。
反向翻译(Back Translation):这是一种可以提高翻译质量的方法。它的原理是,把目标语言的语音或文字,翻译成源语言的语音或文字,然后再翻译回目标语言的语音或文字,然后让模型尝试最大化这两个目标语言的语音或文字的相似性。
这样,模型就可以学习到更准确和更流畅的翻译方式,而不需要有真实的双语言的语音数据集。
这三种技术的结合,使得语音到语音翻译模型可以用单语言的语音-文字数据集来训练,而不需要有双语言的语音数据集,也不需要有专门的模型来复制语言外的信息,如停顿、说话速率、和说话者身份。这样,语音到语音翻译模型就可以实现更高效和更高质量的语音到语音翻译。
效果展示(更多内容可以见官网)
3,AI变革指南,1秒
2,AI变革指南,1秒
1,AI变革指南,2秒
USS模型是一个具有突破性的语音识别系统,它展示了无监督语音识别的巨大潜力,也为语音识别的发展开辟了新的可能性。我们期待USS模型能够在未来为更多的语言和用户提供高质量的语音识别服务,让语音识别成为人类交流的桥梁官网介绍:
https://google-research.github.io/lingvo-lab/translatotron3/
论文地址:
https://arxiv.org/pdf/2305.17547.pdf
出自:https://mp.weixin.qq.com/s/3d5LRcfnPWVkcj4dEaTl8Q
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip