2D/3D/视频生成最近都有很多值得关注的工具,但是要输出完整的AIGC作品,肯定少不了声音。其实声音生成也有很多革命性的工具,例如高质量的声音识别、文字转成人声、人声克隆、音乐生成,已经能组成完整工作流了,其中一些工具甚至已经打包好了,只要下载解压就能用!
2D/3D/视频生成最近都有很多值得关注的工具,但是要输出完整的AIGC作品,肯定少不了声音。其实声音生成也有很多革命性的工具,例如高质量的声音识别、文字转成人声、人声克隆、音乐生成,已经能组成完整工作流了,其中一些工具甚至已经打包好了,只要下载解压就能用!

语音转文字
•Const-me/Whisper(解压就能用): OpenAI Whisper自动语音识别模型的高性能GPGPU推理 ,基于DirectCompute技术,对Windows系统进行了优化,并且在性能和内存使用上优于原始OpenAI实现。
•➡️链接:https://animate124.github.io/
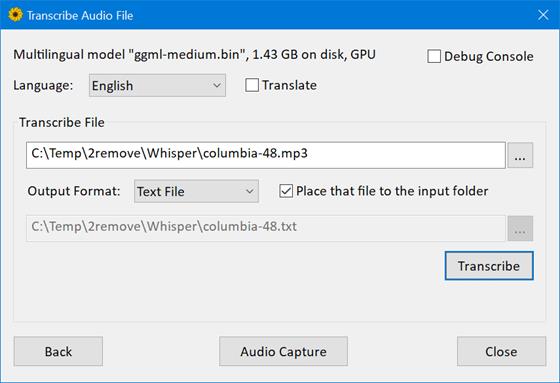
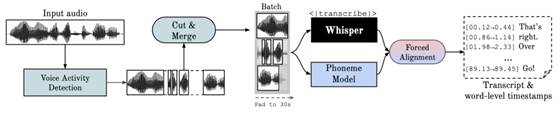
•WhisperX(需要配环境):带有单词级时间戳和说话人分离功能的自动语音识别。提供了比原始 Whisper 模型快 70 倍的实时语音转录速度,并使用了更快的后端 faster-whisper。● 通过 wav2vec2 对齐技术,WhisperX 能够实现准确的单词级时间戳。● 该工具还支持多说话人的自动语音识别,并通过 pyannote-audio 实现说话人分离
•➡️链接:https://github.com/m-bain/whisperX
文字转声音+声音克隆
•clone-voice(解压就能用):这是一个基于Web界面的声音克隆工具,可以将文字或声音转换为特定音色的音频,支持多种语言,•➡️链接:https://github.com/jianchang512/clone-voice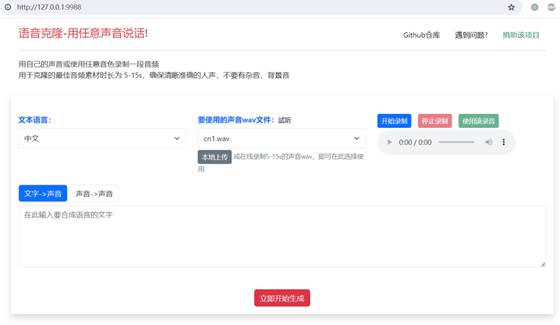 •SeamlessExpressive:可实现高质量的语音翻译,在翻译输出中保持原始说话者的声音风格、语气和独特的表达方式。目前还要申请acess,包含模块:
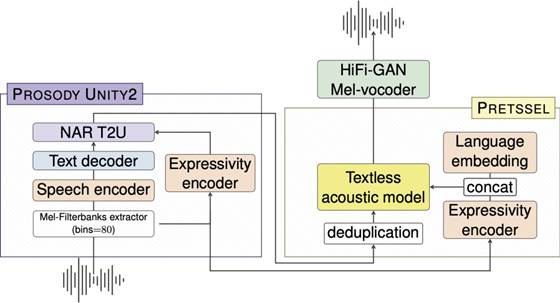
•SeamlessExpressive:可实现高质量的语音翻译,在翻译输出中保持原始说话者的声音风格、语气和独特的表达方式。目前还要申请acess,包含模块:
Prosody UnitY2是基于UnitY2架构的语音到单元转换模型,能够转换短语级别的语调,如语速或停顿。
PRETSSEL是一个表达性单元到语音生成器,能够有效地从语音中分离语义和表达性成分,并转移话语级别的表达性,如个人的声音风格。
mExpresso(多语言Expresso)是一个包含七种朗读风格(默认、快乐、悲伤、困惑、清晰、耳语和笑声)的表达性语音到语音翻译数据集,涵盖英语和其他五种语言。
-––•➡️链接:https://huggingface.co/facebook/seamless-expressive
音乐+音效生成
•Stable Audio:一个可以用文字描述生成音乐的网页工具,打开即用;也包括了文生语音和声音克隆功能。 •➡️链接:https://www.stableaudio.com/
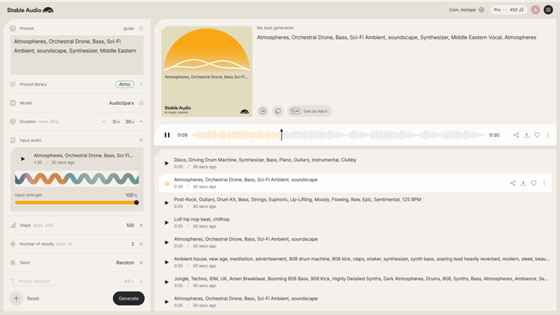 •Suno.ai:一个运行在discord中的工具,你只需要输入一段文字描述即可,包括你需要的音乐风格和对音乐的期望,Suno即可帮你生成2段30秒左右带歌词的音乐。
•Suno.ai:一个运行在discord中的工具,你只需要输入一段文字描述即可,包括你需要的音乐风格和对音乐的期望,Suno即可帮你生成2段30秒左右带歌词的音乐。
 •➡️链接:https://www.suno.ai/
•➡️链接:https://www.suno.ai/
根据人声生成人物对口型动画(talking
head)
•SadTalker:单张图+音频即可生成对口型视频,已加入stable
diffusion A1111全家桶。
•➡️链接:https://github.com/OpenTalker/SadTalker/blob/main/docs/webui_extension.md

•DreamTalk: 基于扩散概率模型的音频驱动表情丰富的人头生成框架,它可以处理多种语言和噪声音频,生成高质量的视频,并提供了对表情风格和头部姿态的控制,但对输出视频的分辨率并未优先考虑(应该是目前这类工具的Sota?)。•➡️链接:https://github.com/ali-vilab/dreamtalk
 •GeneFace: 高度泛化和高保真的音频驱动3D说话面部合成。效果好,但是对于每个人物要单独训练模型。•➡️链接:https://github.com/yerfor/GeneFace/blob/main/README-zh.md
•GeneFace: 高度泛化和高保真的音频驱动3D说话面部合成。效果好,但是对于每个人物要单独训练模型。•➡️链接:https://github.com/yerfor/GeneFace/blob/main/README-zh.md

综合类工具(几乎包含所有和声音相关的功能,但是使用更复杂)
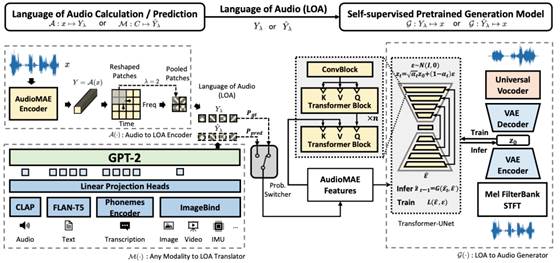
•AudioLDM 2 一个效果非常好的音乐、音效生成工具 。AudioLDM 2框架提出了一种统一的方法来生成语音、音乐和音效。该框架利用音频的通用表示作为“音频语言”,并结合语言模型和潜在扩散模型进行音频合成。
•➡️链接:https://audioldm.github.io/audioldm2/
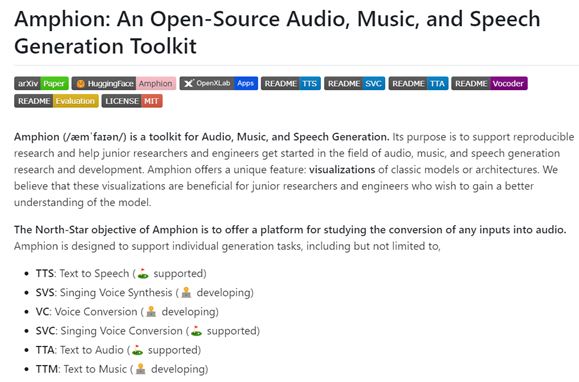
•Amphion:支持多种音频生成任务,包括文本到语音(TTS)、歌声合成(SVS)、声音转换(VC)、歌声转换(SVC)、文本到音频(TTA)和文本到音乐(TTM)等。 •➡️链接:https://github.com/open-mmlab/Amphion
•AudioGPT: 支持的任务包括音频文本转换、音频翻译、音频字幕、音频风格转换、音频增强、语音分离、单声道转立体声、填补音频空白、音频事件提取、声音检测、语音生成头像视频、文本语音生成、图像音频生成以及乐谱生成歌声等多种音频理解与生成任务。 •➡️链接:https://github.com/AIGC-Audio/AudioGPT
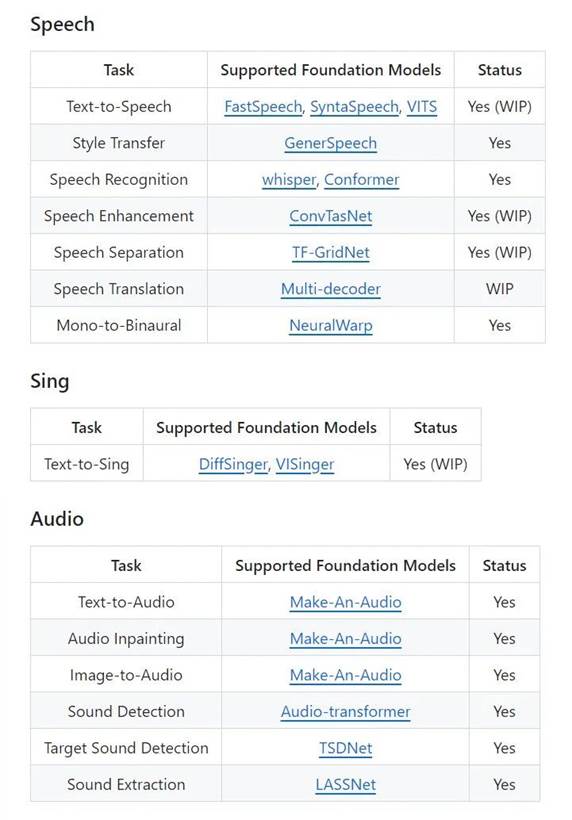
出自:https://mp.weixin.qq.com/s/kV160MMwks6XJMEcI-04ww
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip