clone-voice是一款免费开源的声音克隆工具,利用先进的人工智能技术实现高质量的声音克隆,支持多语言,并提供了详细的技术原理、使用方法及广泛的应用场景,如娱乐、教育、媒体广告和语音交互等。同时,文章也探讨了声音克隆技术的发展意义与挑战。
在当今科技飞速发展的时代,声音克隆技术作为人工智能领域的一项重要成果,正逐渐走进我们的生活。今天,就让我们一同深入了解一款备受瞩目的声音克隆工具——clone-voice。
一、什么是clone-voice
clone-voice是一款免费开源的声音克隆工具,它凭借先进的人工智能技术,能够分析和模拟人类声音的特征,从而实现高质量的声音克隆. 只需提供一段简短的音频样本,它就可以根据该样本生成与原始声音极其相似的克隆声音,并且支持多种语言,目前包括中文、英文、日语、韩语等,甚至还扩展到了法语、德语、意大利语等16种语言,为用户提供了更广泛的应用可能性.

二、技术原理剖析
clone-voice的核心技术基于深度学习模型,特别是WaveNet和Tacotron系列模型,这些模型在语音合成领域有着出色的表现. 其具体的技术流程主要包括以下几个关键步骤 :
1、数据预处理:首先,对输入的音频文件进行采样率转换和分帧等预处理操作。这一步就像是为后续的分析和处理搭建好了基础框架,确保音频数据能够以合适的形式被模型所接受,为特征提取做好充分准备。
2、特征提取:接着,使用Mel-spectrogram对音频信号进行表示。Mel-spectrogram是一种能够有效捕捉音频信号频谱特征的工具,它将音频信号转换为一种更适合机器学习模型处理的图像形式,成为许多语音合成模型的标准输入形式,有助于模型更好地理解和学习声音的特征。
3、模型训练:基于Tacotron模型进行端到端的语音合成训练。在这个过程中,模型通过大量的音频样本数据学习如何从文本生成对应的Mel-spectrogram,逐渐掌握声音的韵律、语调、发音方式等各种细节特征,从而能够根据输入的文本生成相应的语音特征表示。
4、波形生成:最后,利用WaveNet或其他类似的声码器将Mel-spectrogram转换回自然的语音波形。声码器的作用是将模型生成的语音特征还原为可听的声音信号,通过这一步骤,最终生成与原始声音高度相似的克隆语音,实现声音克隆的效果。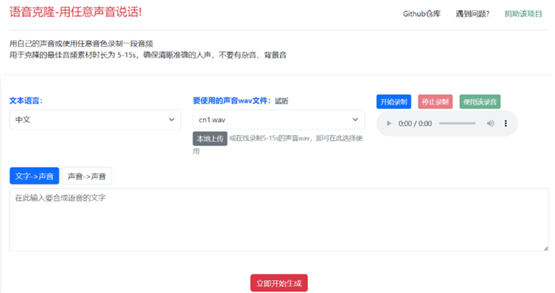
三、使用方法介绍
1、window预编译版使用方法
点击此处打开[Releases](https://github.com/jianchang512/clone-voice/releases)下载页面,下载预编译版主文件(1.7G) 和 模型(3G)
下载后解压到某处,比如 E:/clone-voice 下双击 app.exe ,等待自动打开web窗口,请仔细阅读cmd窗口的文字提示, 如有错误,均会在此显示
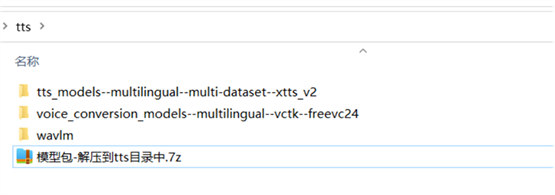
模型下载后解压到软件目录下的 tts 文件夹内,解压后效果如图
转换操作步骤
- 选择【文字->声音】按钮,在文本框中输入文字、或点击导入srt字幕文件,然后点击“立即开始”。
- 选择【声音->声音】按钮,点击或拖拽要转换的音频文件(mp3/wav/flac),然后从“要使用的声音文件”下拉框中选择要克隆的音色,如果没有满意的,也可以点击“本地上传”按钮,选择已录制好的5-20s的wav/mp3/flac声音文件。或者点击“开始录制”按钮,在线录制你自己的声音5-20s,录制完成点击使用。然后点击“立即开始”按钮
2、源码部署(linux mac window)
1) 要求 python 3.9->3.11, 并且提前安装好 git-cmd 工具,下载地址
2) 创建空目录,比如 E:/clone-voice, 在这个目录下打开 cmd 窗口,方法是地址栏中输入 cmd, 然后回车。使用git拉取源码到当前目录 git clone git@github.com:jianchang512/clone-voice.git .
3) 创建虚拟环境 python -m venv venv
4) 激活环境,win下 E:/clone-voice/venv/scripts/activate,
5) 安装依赖: pip install -r requirements.txt --no-deps, windows 和 linux 如果要启用cuda加速,继续执行 pip uninstall -y torch 卸载,然后执行pip install torch torchaudio --index-url
https://download.pytorch.org/whl/cu121。(必须有N卡并且配置好CUDA环境)
6) win下解压 ffmpeg.7z,将其中的ffmpeg.exe和app.py在同一目录下, linux和mac 到 ffmpeg官网下载对应版本ffmpeg,解压其中的ffmpeg程序到根目录下,必须将可执行二进制文件 ffmpeg 和app.py放在同一目录下。
7) 首先运行 python code_dev.py ,在提示同意协议时,输入 y,然后等待模型下载完毕。
8) 下载模型需要挂全局代理,模型非常大,如果代理不够稳定可靠,可能会遇到很多错误,大部分的错误均是代理问题导致。
9) 如果显示下载多个模型均成功了,但最后还是提示“Downloading WavLM model”错误,则需要修改库包文件 \venv\Lib\site-packages\aiohttp\client.py, 在大约535行附近,if proxy is not None: 上面一行添加你的代理地址,比如 proxy="http://127.0.0.1:10809".
10) 下载完毕后,再启动 python app.py
注意:其他具体操作可以参考官网
四、应用场景展望
clone-voice的应用场景十分广泛,涵盖了多个领域:
- 娱乐领域:用户可以克隆自己喜爱的明星、动漫角色或影视人物的声音,为自己的创意视频、音频作品等进行个性化配音,增添独特的趣味性和吸引力。比如制作一段以某明星声音讲述的搞笑故事,或者让动漫角色用特定的声音演绎新的剧情,为娱乐创作带来更多的可能性和创意空间.
- 教育领域:教师可以利用clone-voice将自己的讲解录制成语音资源,方便学生随时复习,无需教师重复讲解,提高教学效率和资源的可重复性利用。同时,也可以为语言学习类的教育软件或在线课程提供更加生动、个性化的语音示范,帮助学生更好地学习和模仿发音.
- 媒体与广告行业:媒体从业者能够快速生成各种不同风格和音色的语音旁白,用于新闻报道、纪录片、广告宣传等内容的制作,丰富音频素材的多样性,提升作品的质量和表现力。还可以根据不同的目标受众和宣传场景,选择合适的音色来传递信息,增强广告的吸引力和感染力。
- 语音交互应用:对于语音助手、智能客服等语音交互产品的开发者来说,clone-voice可以帮助他们为产品赋予更加个性化、独特的声音特征,使其在众多同类产品中脱颖而出,提高用户的使用体验和产品的辨识度,增强用户与产品之间的情感连接.
五、技术的意义与挑战
clone-voice所代表的声音克隆技术的发展具有重要的意义。它为我们提供了一种全新的创作和娱乐方式,让每个人都能够轻松地拥有个性化的语音资源,丰富了数字内容的创作形式和表达手段.然而,与此同时,这项技术也带来了一些挑战和问题,例如可能会涉及到声音版权、隐私保护以及虚假信息传播等方面的风险. 因此,在享受声音克隆技术带来的便利和乐趣的同时,我们也需要关注和思考如何在技术发展与伦理道德、法律法规之间找到平衡,确保其合理、合法、安全地应用和发展.
项目地址:https://github.com/jianchang512/clone-voice
原文地址:https://mp.weixin.qq.com/s/1gbLdigjTgA-veu3upJnrQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip