本文介绍了声音克隆技术,特别是GPT-SoVITS和Bert-VITS2两个开源项目,它们分别适用于快速实现声音克隆和追求更高质量的语音合成。GPT-SoVITS因其快速训练时间和跨语言能力受到推荐,并提供了详细的教程指导如何在OpenBayes平台上使用该项目克隆声音。文章还强调了数据集质量对生成结果的重要性,并以李雪健老师的声音为例,展示了克隆声音的效果。整体而言,本文为声音克隆技术的初学者提供了一个实用且易懂的入门指南。
一直没有写过关于声音克隆的文章,所以这次补上,毕竟这个用的还真是有点多,也为后面更多的个性化配音做好准备。
TTS 的英文全名是 Text To Speech,中文译名是“文本转语音”。它是一种将文本内容转换为语音的技术,通过TTS技术,计算机可以将文字信息转换成人类可听懂的语音输出,实现语音合成的功能
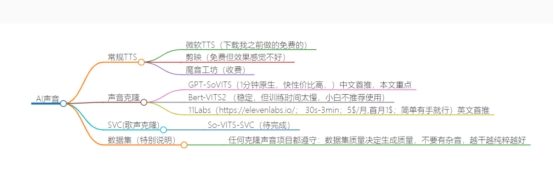
目前市场上的AI声音
我们最多用的还是普通的TTS,即把文字通过软件输出指定人的声音,这块微软做的不错,之前自己写过一个免费的TTS小软件,API用的就是微软的,如有需要,请看自己开发一个免费的文本转语音小工具
如果你觉得功能少,可以使用国内的魔音工坊,但是要收费的哈
但这些都不能指定声音转换,所以这里使用声音克隆,来将指定人声训练成模型,然后文字转音频。
接下来说重点声音克隆
开源项目地址:
https://github.com/fishaudio/Bert-VITS2
https://github.com/RVC-Boss/GPT-SoVITS
GPT-SoVITS
GPT-SoVITS是由RVC变声器的创始人(GitHub昵称为RVC-Boss)与AI音色转换技术专家Rcell合作开发的一个开源项目。它是一个跨语言音色克隆工具,专注于声音的转换和克隆。
Bert-VITS2
Bert-VITS2是由社区开发者fishaudio发起的一个开源项目,它基于VITS(Variational Inference for Text-to-Speech)模型进行开发,旨在提供高质量的文本到语音(TTS)服务。
GPT-SoVITS在训练时间上具有明显的优势,因为它支持Few-shot学习,能够在短时间内(如一分钟的语音数据)训练出具有相似音色的模型。
Bert-VITS2可能需要更长的训练时间(1-4个小时)来达到高质量的语音合成效果,尤其是在数据集较大或模型较为复杂的情况下
简单来说就是如果你需要更稳定和标准的声音,辛苦一次永久使用就选择Bert-VITS;
如果你想快速实现声音克隆,跨语言就选择GPT-SoVITS;
这里以GPT-SoVITS为例,写一篇详细教程,因为他简单有效还节省时间,至于Bert-VITS,我感觉即使写了,他几个小时的训练时间加上大量的素材收集,许多人也没时间去尝试,效果也不一定能好很多,这里力推GPT-SoVITS!让我们开始吧!
开始前准备,注册 OpenBayes 平台账号
新用户注册OpenBayes即可获得3小时免费RTX4090使用时长,用下方注册链接你我都可以多加一个小时免费时长哈
https://openbayes.com/console/signup?r=huawang_zL1B
使用原先绑定的数据集(原神可莉),尝试训练一下
1 GPT-SoVITS一键克隆环境:
选择公共资源下的公众教程,选择GPT-SoVITS 音频合成在线 Demo
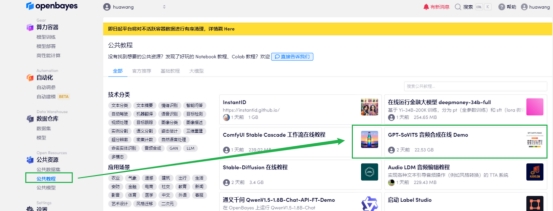
2 GPT-SoVITS一键克隆环境
点击右上角克隆,之后选择审核并执行,继续执行
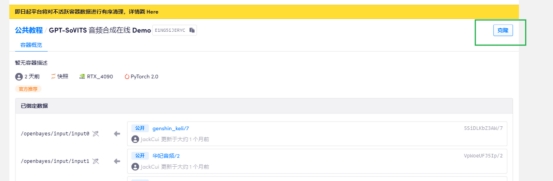
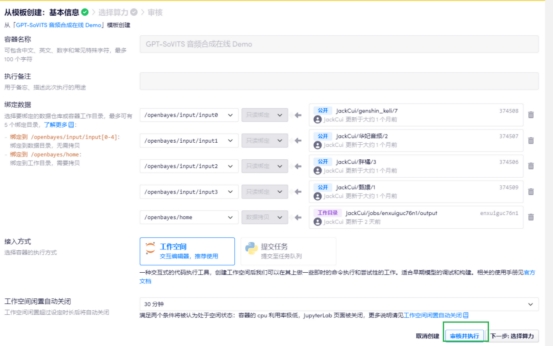
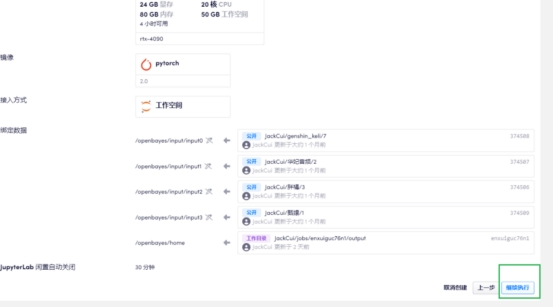
等待几分钟,等待数据同步成功
3 完成后 打开工作空间
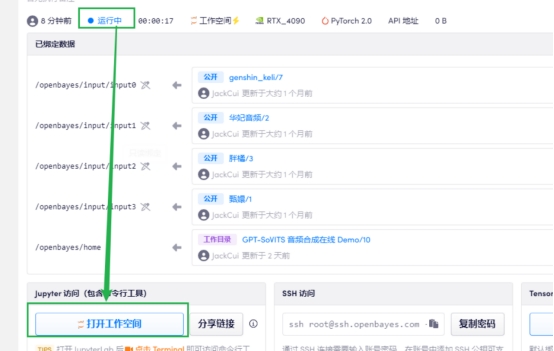
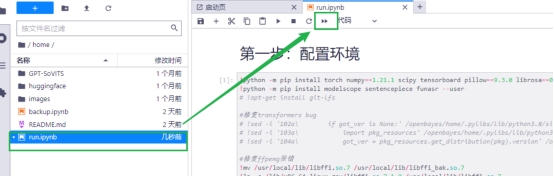
4 打开 run.ipynb,一键运行所有单元格
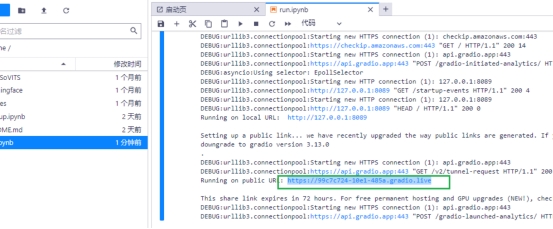
5 等几秒钟运行完毕,打开输出的 public URL
6 打开音频选择数据类型

7 点击开始选练
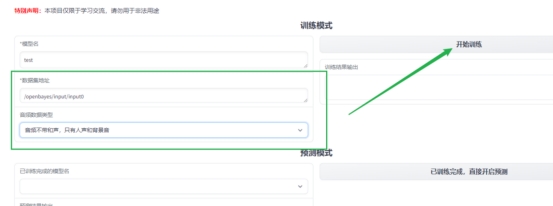
8 等待几分钟训练时间
可以后台看到训练15epoch后训练成功,前端显示模型开始预测
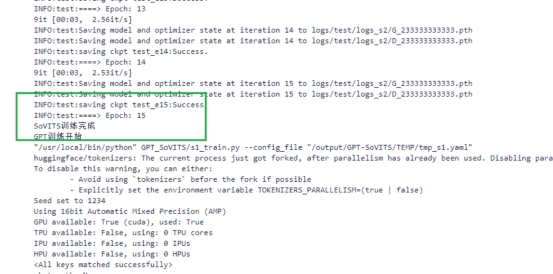
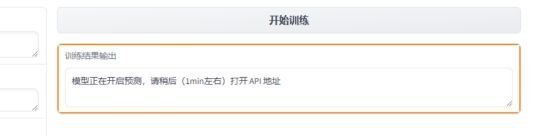
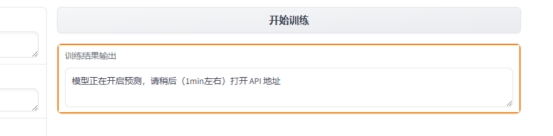
9 打开原来的Jupyter 工作空间,选择API地址
API地址需要实名认证,如果没认证认证后再回来,就可以看到地址了
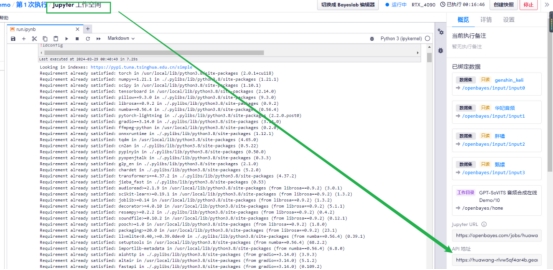
10 打开API地址,开始玩耍
选择训练好的GPT模型和SoVITS模型,输入你想要推理的文字,比如:“欢迎你成功训练成功了”,点击开始推理
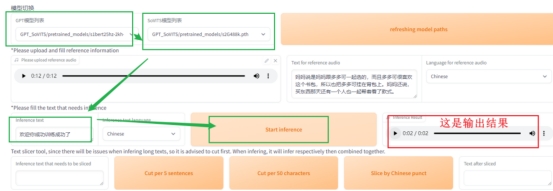
(这里上面选择错了,一般训练好的是最后一个,看你开始定义的模型名字就好哈)
这样你在原本绑定的数据集上就成功训练的一个声音模型
效果如下
克隆元神可莉声音,电子灵魂华尔兹,2秒
开始选择自己的数据集
先关闭自己之前启动的容器
1 准备30s-1min的音频素材
这里以李雪健老师为例
任何克隆声音项目都遵守;数据集的质量决定生成的质量,不要有任何杂音,越干净、越纯粹越好
通过录音软件(声音录制软件),录取相关音频,放到剪映处理,把人声音的能开的都开了,处理结果就不放了,免得麻烦哈,这里我处理大概1分36s的录音
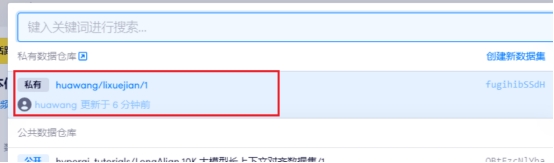
2 上传数据集
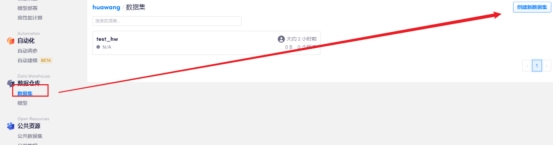

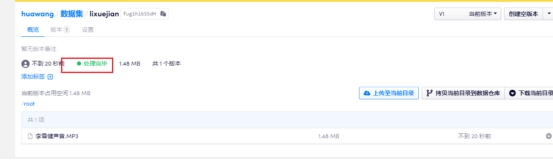
3 修改配置并启动
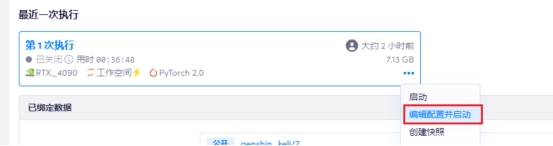
点击模型训练,进入刚才跑的项目

点击编辑配置并启动
配置自己的数据并执行
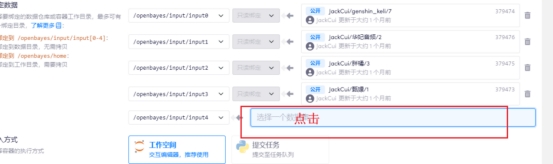
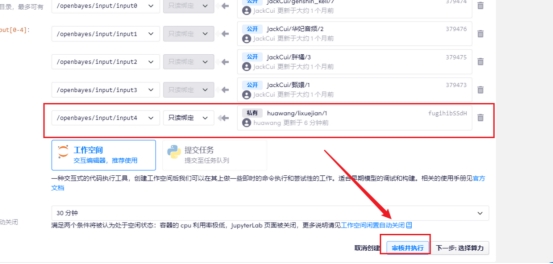
一直点点点,到启动成功,打开工作空间,重复以上的训练步骤即可
4 训练填写新绑定的数据集目录
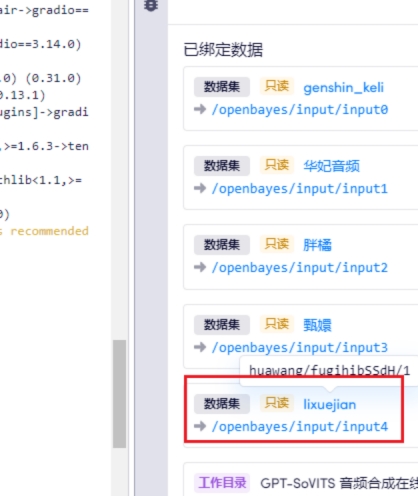
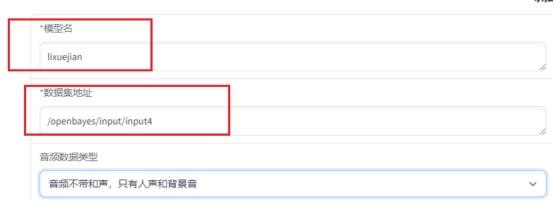
5 重复之前开头的步骤,最后我们看下效果
说中文效果
克隆李雪健-中文,电子灵魂华尔兹,8秒
说英文效果
克隆李雪健English-version,电子灵魂华尔兹,12秒
最后,这个教程看着多了点,其实可能我只是尽可能把每个步骤的图贴完整,尽量满足各种不懂编程的人都够顺利克隆声音成功
这个项目还是蛮牛皮,重点在于省时省力,简单有效,当之为当前性价比速度之神,也期待你能有更多更好玩的用处
如果是英文,建议去llElevenlabs
出自:https://mp.weixin.qq.com/s/FybxMhI00pSL61VHjCJp5Q
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip


 试着问问
试着问问