OCR 后处理一直是麻烦的事情,如果用传统的算法会有训练需要准备大量的数据,迭代更新效果差的问题,不过速度确实快。我在做的 OCR 识别商务名片这个项目上也积累了些经验,大家可以根据我的经验选择合适的算法。
OCR 后处理一直是麻烦的事情,如果用传统的算法会有训练需要准备大量的数据,迭代更新效果差的问题,不过速度确实快。
我在做的 OCR 识别商务名片这个项目上也积累了些经验,大家可以根据我的经验选择合适的算法。
传统算法
一般情况 OCR 识别商务名片会分为两步:
·
OCR 算法识别出文字和坐标。
·
文字后处理。
·
第一步大家可以参考百度 PaddleOCR ,其对中文的准确率是非常高的,截止目前,我使用上没遇到识别文字错误的问题:https://github.com/PaddlePaddle/PaddleOCR
本文重点讨论的是文字的后处理问题。
文字的后处理手段主要分为两种:
·
规则匹配,提取出文字
·
命名实体识别
·
规则匹配提取文字
这个不用我多说,之前有发文讲过电话号码的匹配。如
1[3-9]\\d{1}[\\s\\-\\.\\)]?[\\s]?\\d{4}[\\s\\-\\.]?\\d{4}
匹配出各种类型的电话号码。
同样的如果是身份证这些有固定格式类型的,确实通过规则匹配抽取出我们想要的关键信息。
这种方式的优点是:准、快。不管怎么样现在的 AI 算法很少有用响应速度作为指标的,特别是大模型,响应速度惨不忍睹。
命名实体识别
命名实体识别(Named Entity
Recognition, NER)是自然语言处理(Natural Language Processing,
NLP)的一个分支,它的任务是识别文本中具有特定意义的实体,例如人名、地名、组织名、时间表达、数值表达等。这些实体通常是信息检索、问答系统、内容分析、客户关系管理等领域的关键元素。
在命名实体识别中,算法会分析文本,并将每个单词或短语标记为预定义的类别之一。例如,文本“苹果公司发布了新的iPhone”中,“苹果公司”可能被标记为组织名,而“iPhone”可能被标记为产品名。
命名实体识别通常涉及以下步骤:
1.
分词(Tokenization):将连续文本分割为单词或词汇单元。
2.
词性标注(Part-of-Speech tagging):为每个单词指定词性,如名词、动词等。
3.
实体识别(Entity Detection):确定哪些词汇单元属于感兴趣的实体类别。
4.
实体分类(Entity Classification):将识别出的实体分配到预定义的类别,如人名、地点等。
5.
命名实体识别技术可以基于规则、基于统计或使用机器学习模型,包括最近流行的深度学习模型,如循环神经网络(RNNs)、长短时记忆网络(LSTMs)、和 Transformers 等。随着技术的进步,命名实体识别系统的准确性和复杂性都有了显著提升,能够在多种语言和领域中有效地识别和分类实体。
上面是理论,我自己的命名实体识别的实践,发现:还是别人已经训练好的模型好用,自己曾使用 HanLP 来训练 NER,效果并不是很好。我试过效果比较好的模型有:https://www.modelscope.cn/models/iic/nlp_deberta_rex-uninlu_chinese-base/summary
RexUniNLU 零样本通用自然语言理解-中文-base 模型,这是在魔塔上面开源的一个模型。
这个模型包含命名实体识别的功能。
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
semantic_cls = pipeline('rex-uninlu', model='damo/nlp_deberta_rex-uninlu_chinese-base', model_revision='v1.2.1')
# 命名实体识别 {实体类型: None}
semantic_cls(
input='1944年毕业于北大的名古屋铁道会长谷口清太郎等人在日本积极筹资,共筹款2.7亿日元,参加捐款的日本企业有69家。',
schema={
'人物': None,
'地理位置': None,
'组织机构': None
}
)
另外如果你不想部署这个模型,可以直接在魔塔上面体验效果。
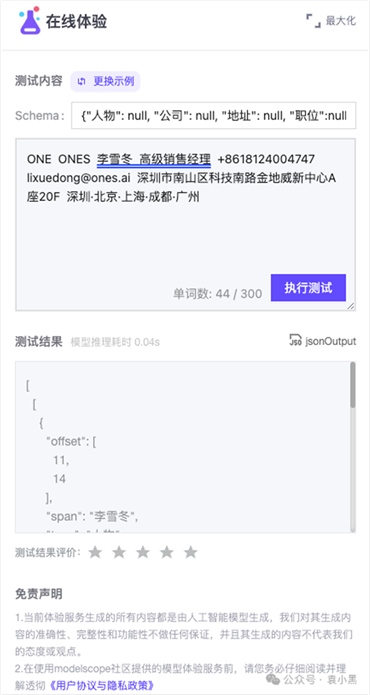 image.png
image.png
我们可以直接看看效果:
# 我的输入
schema:{"人物": null, "公司": null, "地址": null, "职位":null, "电话号码":null, "邮件":null}
识别的目标:
阿里巴巴 广州阿里游戏科技有限公司 李雪冬 高级销售经理 +8618224004747 lixuedong@ones.ai 深圳市南山区科技南路金地威新中心A座20F 深圳·北京·上海·成都·广州
输出结果:
[ [ { "offset": [ 0, 17 ], "span": "阿里巴巴 广州阿里游戏科技有限公司", "type": "公司" } ], { "offset": [ 11, 14 ], "span": "李雪冬", "type": "人物" } ], [ { "offset": [ 16, 22 ], "span": "高级销售经理", "type": "职位" } ], [ { "offset": [ 59, 80 ], "span": "深圳市南山区科技南路金地威新中心A座20F", "type": "地址" } ] ]
虽然没把我想要的所有信息抽取出来,可能做完训练之后效果更好。但是规则匹配不好匹配的信息都抽取出来了,如姓名、职位、地址、公司。至于电话号码、邮件使用规则匹配或者我们单独训练一下,能抽取出来难度应该不大。
大模型做命名实体识别
使用大模型做命名实体识别就是写 prompt 了,之前的有发文讲过就不细说了。
多模态大模型做 OCR
上面介绍了传统的大模型分两步处理才能获取识别后的名片信息,那么有没有可能一步识别出结果呢?
多模态的大模型确实能做到。
多模态大模型是一类采用深度学习技术构建的人工智能模型,它能够处理和理解多种类型的数据模态,如文本、图像、声音等。这些模型通常是大型的神经网络,它们经过大量数据的训练,能够捕捉不同模态之间的关联,并执行跨模态的任务。
特点:
1.
数据模态: 多模态模型能够同时处理多种类型的输入数据,例如,它可以分析文本信息和相关的图像信息,以获得更全面的理解。
2.
大规模: 这些模型通常很大,含有大量的参数,需要大量的计算资源来训练和运行。它们通常使用了成千上万个处理单元(比如GPU或TPU)进行训练。
3.
预训练和微调: 多模态大模型通常采用预训练加微调的范式。它们首先在大规模的数据集上进行预训练,学习通用的特征和跨模态的关系,然后可以针对特定任务或领域进行微调。
4.
跨模态理解: 通过捕捉不同模态之间的内在联系,这些模型能够在一个模态中获取信息,并用于理解或生成另一个模态的数据。例如,它们可以从文本描述生成图像,或者从图像中回答关于所见内容的问题。
应用:
·
图像标注: 从图像内容生成描述性文本。
·
视觉问答: 回答关于图像内容的问题。
·
多模态翻译: 在翻译文本的同时考虑与文本对应的图像或声音信息。
·
情感分析: 分析文本和语音中的情感表达。
·
交互式机器人: 结合视觉、听觉和语言信息,与人类自然交互。
技术示例:
·
OpenAI 的 GPT-4:大名顶顶,业界遥遥领先。
·
Google的BERT: 虽然BERT本身是文本处理模型,但它的变种可以扩展到多模态任务。
·
OpenAI的CLIP: 能够理解图像和与之关联的文本描述。
·
Facebook 的 BART: 一个多模态模型,可以同时处理文本和图像数据。
·
智普的 VisualGLM:多模态大模型,只支持英文。
·
阿里的 Qwen-VL-Plus:完全开源,业界良心,支持中文,强烈推荐。
多模态大模型的研究和开发是人工智能领域的前沿方向,它在提高机器对世界的理解和提升人机交互体验方面具有重要作用。随着技术的进步,这些模型将在更多实际应用中发挥作用。
这里使用阿里的 Qwen-VL-Plus 给大家做个案例。
体验地址是:Qwen-VL-Plus · 创空间 (modelscope.cn)
输入:
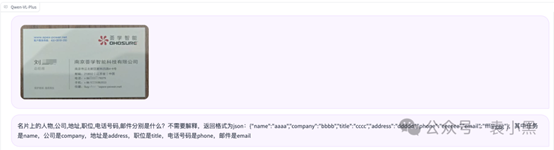 image.png
image.png
prompt 如下:
名片上的人物,公司,地址,职位,电话号码,邮件分别是什么?不需要解释,返回格式为json:{"name":"aaaa","company":"bbbb","title":"cccc","address":"ddddd","phone":"eeeeee","email":"fff@ggg"},其中任务是name,公司是company,地址是address,职位是title,电话号码是phone,邮件是email
大模型返回:
 image.png
image.png
非常精准,效果非常好。响应速度也很快。可以说是目前最好的选择。
当然大模型有的时候返回结果并不是这么标准,这个时候需要用户多
run 几次。下次我也可以分享如何处理大模型返回结果不标准的问题。
另外阿里 Qwen 私有化需要 24GB 显存,资源消耗还是比较大的,如果量不大可以调用云端 API 接口:https://help.aliyun.com/zh/dashscope/developer-reference/vl-plus-quick-start
这样也少了PaddleOCR的模型显存,但是PaddleOCR显存需要很少,我使用的是P40显卡8GB显存,可以运行Paddle Serving OCR 2个定位进程,1个识别进程,并发10+没问题。多模态的并发没进行测试验证,有测试验证的朋友请告诉我结果。
总结
然后我们需要做一下比较
|
解决方案
|
优点
|
缺点
|
|
PaddleOCR+规则匹配
|
快、准
|
很多场景如姓名、地址这些自然语言类型的关键词提取不了
|
|
PaddleOCR+命名实体识别+规则匹配
|
快、准
|
泛化能力差,加一个识别的字段可能就需要重新训练
|
|
PaddleOCR+大模型做命名实体识别
|
相对上面两种方案,更加准确,泛化能力更好,能识别的关键信息更多
|
慢
|
|
私有化多模态大模型如Qwen-VL-Plus
|
较快、准、泛化能力强
|
以 Qwen 为例子,需要 24GB 显存,并发低。
|
|
多模态大模型 API 调用
|
较快、准、泛化能力强,资源消耗低
|
图片需要上传到云端服务商如阿里那里。
|
PaddleOCR的显存大概需要6GB左右,RexUniNLU模型大概需要2G显存,Qwen-VL-Plus需要24GB显存,大家可以根据自己的情况选择自己需要的解决方案。
出自:https://mp.weixin.qq.com/s/wlxhPBjqlgreJlOrq9yZmQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip