本文总结了多模态推理的概念,涉及视觉和语言等至少两种感知模态的信息融合,旨在获取更全面准确的理解和知识,支持视觉问答、视觉常识推理、视觉语言导航等任务。文章进一步介绍了知识图谱推理及其方法,包括基于规则学习、路径排序、表示学习和神经网络学习。最后,文章阐述了多模态推理任务的具体应用,包括视觉问答、视觉常识推理和视觉语言导航。
 多模态推理
多模态推理
多模态推理涉及至少两种不同的感知模态,最常见的是视觉和语言。这两种模态的信息可以是图片和文本、视频和语音等。多模态推理的目标是从不同模态的信息中获取更全面、更准确的理解和知识,以支持各种任务,包括视觉问答、视觉常识推理、视觉语言导航等。接下来分两部分:知识图谱推理、多模态推理任务,一起来深入了解多模态应用:多模态推理。 多模态推理
多模态推理
一、知识图谱推理
什么是知识图谱(Knowledge
Graph)?知识图谱是一种结构化的知识库,它以图的形式表示和存储现实世界中的实体、概念及其相互关系。这些实体可以是具体的人、地点、事物,也可以是抽象的概念或思想。
- 节点:代表现实世界中的实体(如人、地点、事物、概念等),每个实体通常由一个唯一的标识符表示。
- 边:表示这些实体之间的关系。
知识图谱的基本组成单位是“实体—关系—实体”三元组,以及实体及其相关属性—值对,实体间通过关系相互联结,构成网状的知识结构。KG = (E,R,T),KG表示知识图谱、E表示实体集合、R表示关系集合、T表示知识三元组集合。
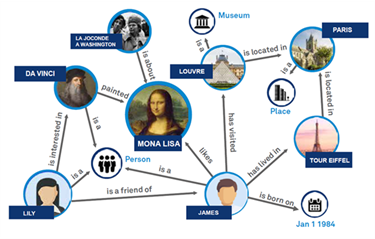
知识图谱
什么是知识图谱推理(Multimodal Reasoning with Knowledge Graph)?知识图谱推理是指基于知识图谱中的事实和关系,通过逻辑、规则、统计或机器学习等方法,从已知的信息中推断出新的信息或关系的过程。知识图谱推理的目标是从有限的事实中推导出更多的知识,填补知识图谱中的空白或增强图谱的表达能力。

知识图谱推理
一、基于规则学习:通过挖掘图谱中的逻辑规则,利用规则匹配和推理来预测新的实体和关系。例如:重写逻辑(Rewriting Logic),将规则表示为重写规则,并通过递归应用重写规则来进行推理。
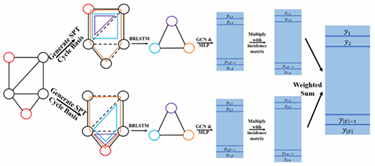
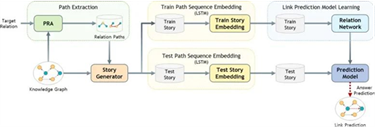
二、基于路径排序:
利用图谱中实体间的路径特征进行排序学习,通过评估路径的可信度来推断实体间的关系。例如:路径排序算法(Path-Ranking Algorithm,PRA),采用随机行走和基于重启的推理机制,执行多个有界深度优先搜索过程来寻找关系路径。
三、基于表示学习:
将实体和关系嵌入到低维向量空间,通过向量运算和相似性度量进行推理。例如:翻译距离模型(如TransE、TransH、TransR等),这些模型为知识图谱中的每个实体和关系学习一个向量表示,并通过向量间的运算关系来推断新的实体和关系。
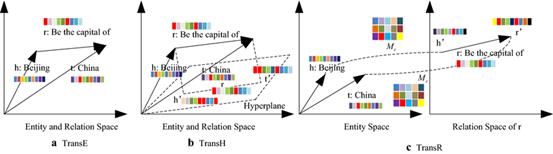
四、基于神经网络学习利用神经网络模型捕捉图谱中的结构信息,通过神经网络的前向传播进行推理预测。例如:基于图神经网络(GNN)的推理方法,如基于注意力机制的图卷积神经网络(Graph Attention Network,GAT),通过对实体之间的相似度进行加权,来推断实体之间的关系。
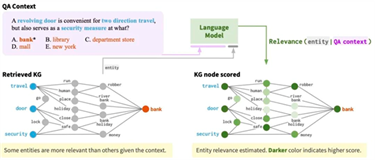
二、多模态推理任务
什么是多模态推理任务(Multi-Modal Reasoning Task)?多模态推理任务是指利用多种感知模态的信息进行综合分析和判断的过程。

多模态推理任务
一、视觉问答(Visual Question Answering,VQA)视觉问答指的是给机器一张图片和一个开放式的自然语言问题,要求机器输出自然语言答案。答案可以是短语、单词、(yes/no)或从几个可能的答案中选择正确答案。
·
VQA是一个典型的多模态问题,融合了计算机视觉(CV)与自然语言处理(NLP)的技术,计算机需要同时学会理解图像和文字。
·
为了回答某些复杂问题,计算机还需要了解常识,并基于常识进行推理(common-sense resoning)。
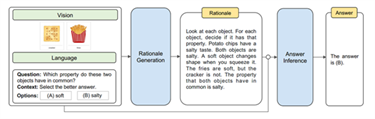
二、视觉常识推理(Visual Commonsense Reasoning,VCR)
视觉常识推理需要在理解文本的基础上结合图片信息,基于常识进行推理。给定一张图片、图中一系列有标签的bounding box,VCR实际上包含两个子任务:{Q->A}根据问题选择答案;{QA->R}根据问题和答案进行推理,解释为什么选择该答案。
·
VCR数据集由大量的“图片-问答”对组成,主要考察模型对跨模态的语义理解和常识推理能力。
·
预训练任务可能包括将BERT经典的MLM和NSP预训练任务扩展到多模态场景等。

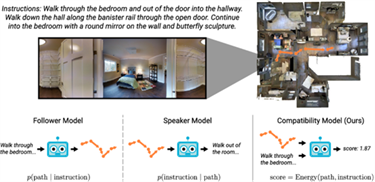
三、视觉语言导航(Vision Language Navigation)
视觉语言导航是一种技术,它结合了计算机视觉、自然语言处理和自主学习三大核心技术,使智能体能够跟随自然语言指令进行导航。
·
智能体不仅能够理解指令,还能理解指令与视角中可以看见的图像信息。
·
智能体需要在环境中对自身所处状态进行调整和修复,最终做出对应的动作,以达到目标位置。
原文出自:
https://mp.weixin.qq.com/s/KnR1aMV5GaPwWiVNghBRdw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip