开源新星Qwen1.5闪亮登场!不同大小的模型,满足你的各种需求。虽然在对齐上暂时没追上GPT-4-Turbo,但别小看它!在MT-Bench和Alpaca-Eval v2的测试中,Qwen1.5可是把Claude-2.1和GPT-3.5-Turbo-0613都甩在了身后!这就是开源的魔力,未来还有更多可能等待发掘。
开源新星Qwen1.5闪亮登场!不同大小的模型,满足你的各种需求。虽然在对齐上暂时没追上GPT-4-Turbo,但别小看它!在MT-Bench和Alpaca-Eval v2的测试中,Qwen1.5可是把Claude-2.1和GPT-3.5-Turbo-0613都甩在了身后!这就是开源的魔力,未来还有更多可能等待发掘。 那么,Qwen1.5到底还有多少惊喜等着我们?
那么,Qwen1.5到底还有多少惊喜等着我们?
如果有其他疑问,欢迎朋友关注留言!
模型介绍与特点
在这里插入图片描述
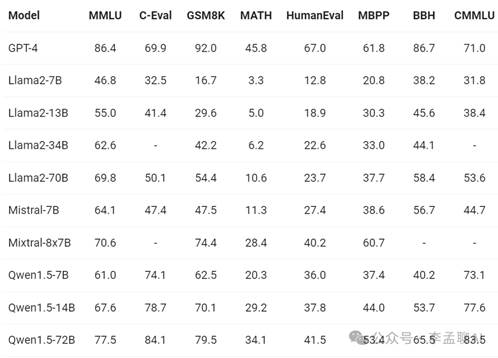
为了深入了解Qwen1.5的实力,我们对其基础和聊天模型进行了全面评估。从语言理解到代码、推理,每一项基础能力都经过严格测试。多语言处理、符合人类喜好、智能体能力,还有检索增强生成,它都游刃有余。
在MMLU、C-Eval等知名数据集上,Qwen1.5大显身手,尤其72B版本,更是远超Llama2-70B。数学、推理,对它来说都是小菜一碟。
小模型也火热,我们拿Qwen1.5的小参数版本和市面上的佼佼者比了比,结果很惊喜。虽然参数少,但实力一点不输。怎么让大模型的能力“传授”给小模型?我们正在研究。
想让AI更懂人,对齐技术很关键。我们用先进的策略优化技术,让Qwen1.5更贴合人类思维。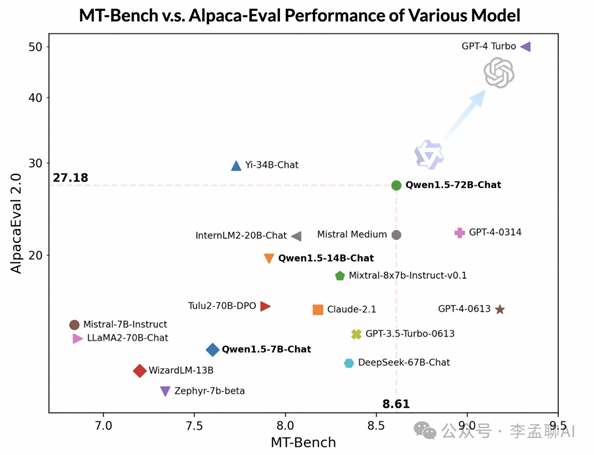
评估AI聊天模型,挑战多多。我们请大模型来当“评委”,在MT-Bench和Alpaca-Eval上给Qwen1.5打分。结果?很不错!虽然没赢过GPT-4-Turbo,但也超过了Claude-2.1等一众高手。
回答长短,不是Qwen1.5的考量。它注重质量,不会为了得分而啰嗦。用户反馈也证明了这一点:新版本的回答,更受欢迎。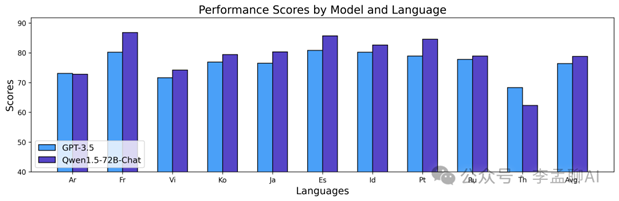
多语言能力如何?我们选了12种语言来测。考试、翻译、数学…Qwen1.5样样行。阿拉伯语、日语、韩语,它都能轻松应对。
这只是Qwen1.5的冰山一角。它还有哪些隐藏技能?等你来探索。
技术合作与生态支持
 在这里插入图片描述
在这里插入图片描述
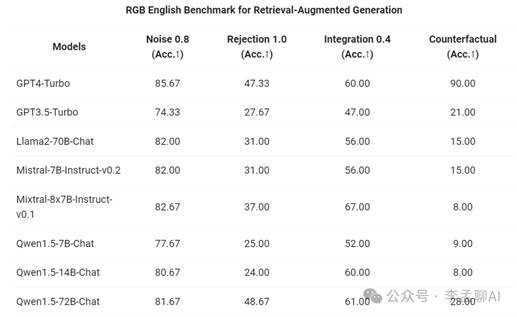
通用语言模型的魅力,可不止于说话。它们还能与外部系统“搭档”,解决大问题。比如,RAG这种新热门任务,就能帮大语言模型避免“胡思乱想”、获取不到最新或私密信息等尴尬。而且,这些模型还能熟练地用API、写代码,就像个智能助手。
我们给Qwen1.5的Chat模型来了个全面体检,看看它在RAG任务上表现如何。结果挺不错!大模型通常比小模型更厉害,快赶上GPT-4了。但在数学和可视化任务上,Qwen1.5还得加把劲,尤其是编码能力。未来,我们打算让所有Qwen模型都更擅长编码,期待它们的进步吧!
不过,这只是开始。通用语言模型与外部系统的结合,还有哪些惊人潜能?
模型效果与评估
长文理解,轻松搞定!Qwen1.5全新升级,支持超长32K tokens上下文。我们在专业基准L-Eval上测试,看它如何应对复杂长文。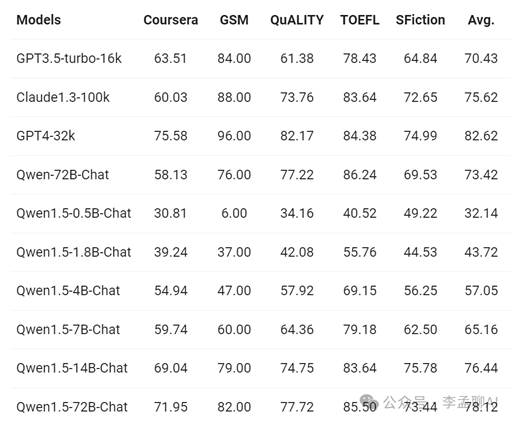
结果惊艳!Qwen1.5小模型就与GPT-3.5不相上下,而72B大模型更逼近GPT4-32k。无论多长的内容,它都能应对自如。
但这还不是极限!想挑战更长文本?试着调整config.json里的设置,可能会有新发现哦!
想要亲自体验Qwen1.5的超能力吗?
开发体验与应用前景
这次的最大看点,就是它与HuggingFace transformers库的完美结合。从4.37.0版本起,你无需加载任何自定义代码,就能轻松调用Qwen1.5。
from transformers import AutoModelForCausalLM
# 以前的用法
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True)
# 现在更简单
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-7B-Chat", device_map="auto")
想跟Qwen1.5聊天?没问题,几行代码就能搞定!
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # 选择你的设备
# 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-14B-Chat-AWQ", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-14B-Chat-AWQ")
# 提出问题
prompt = "给我介绍一下大型语言模型。"
messages = [{"role": "system", "content": "你是一个有用的助手。"}, {"role": "user", "content": prompt}]
# 处理输入
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 生成回答
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
Qwen1.5-72B-Chat
Demo使用,示例逻辑推理和写长文测试。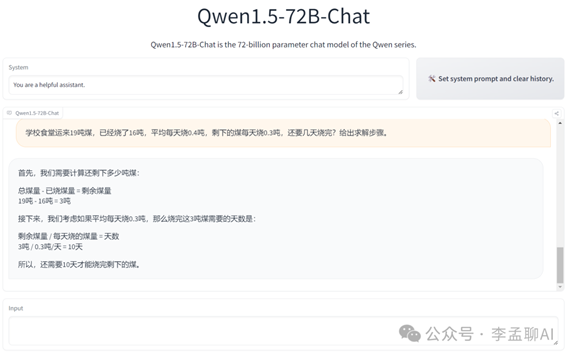

qwen1.5通用性功能没有问题,更深的功能得上开发手段,其他更多功能请参考下面链接!
博客:https://qwenlm.github.io/blog/qwen1.5/
演示:https://hf.co/spaces/Qwen/Qwen1.5-72B-Chat
模型:https://huggingface.co/Qwen
Github:https://github.com/QwenLM/Qwen1.5
结语
Qwen1.5不仅代表着开源AI技术的新高度,更以其卓越的性能、广泛的合作生态和出色的开发体验,为研究者与应用开发者提供了强大的支持。展望未来,Qwen1.5有望在更多场景中发挥其不可替代的作用,推动AI技术的持续创新与发展。
出自:https://mp.weixin.qq.com/s/Z2qezXF4Wjjip2Z8hGiK6w
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip