Facebook研究院开发了audio2photoreal技术,能根据音频生成逼真人物视频。项目基于深度学习图像生成模型,提取语音特征驱动人脸和身体动画。该技术可生成高分辨率、高帧率、高逼真度视频,适用于虚拟社交、视频会议、教育培训等领域。但还需优化改进,并考虑伦理和社会问题。项目已开源并提供代码和项目地址。
你想要了解audio2photoreal这个项目吗?这是一个由Facebook研究院开发的技术,可以根据音频生成逼真的人物视频!
audio2photoreal的全称是From Audio to Photoreal Embodiment:
Synthesizing Humans in Conversations,意思是从音频到逼真的人体表现合成对话中的人类。
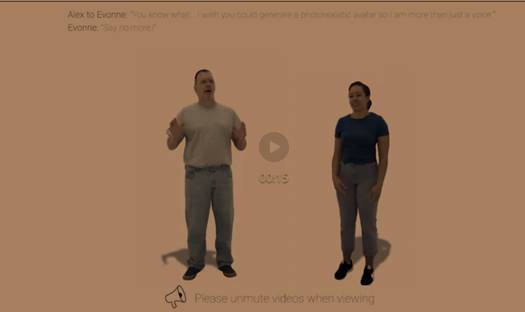
这个项目的目标是通过音频驱动,生成高质量的人脸和身体动画,从而实现人物的完整呈现。这样,你就可以用你的声音,创造出任何你想要的角色,无论是自己的形象,还是你喜欢的明星,甚至是虚拟的人物。
项目已开源,可以自行部署体验

audio2photoreal如何做到的?
audio2photoreal的核心技术是基于深度学习的图像生成模型,它可以从音频中提取语音特征,然后用这些特征来控制人脸和身体的运动。
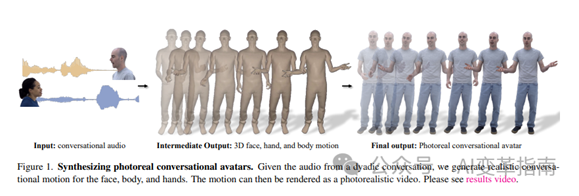
具体来说,它分为三个部分:
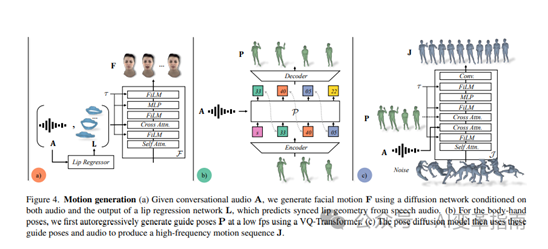
人脸生成模型:这个模型可以从音频中生成逼真的人脸表情,包括嘴唇同步,眨眼,眉毛等细节。它使用了一种叫做扩散模型的新颖方法,可以有效地处理不同的人脸形状和肤色,以及不同的光照和背景条件。
身体生成模型:这个模型可以从音频中生成逼真的身体姿态,包括手势,头部转动,身体倾斜等动作。它使用了一种叫做变分自编码器的方法,可以从大量的人体数据中学习出一个低维的表示空间,然后用这个空间来生成多样的身体姿态。
身体指导模型:这个模型可以从音频中生成一个身体姿态的序列,作为身体生成模型的输入。它使用了一种叫做变换器的方法,可以捕捉音频中的语义和情感信息,然后用这些信息来指导身体姿态的变化。
audio2photoreal的优点缺点
audio2photoreal的优点是它可以生成高分辨率,高帧率,高逼真度的人物视频,而且可以适应不同的人物形象,不同的音频内容,不同的场景环境。它的应用场景非常广泛,比如可以用于虚拟社交,视频会议,教育培训,娱乐媒体,艺术创作等等。
audio2photoreal的缺点是它还需要进一步的优化和改进,比如提高生成速度,减少生成噪声,增加生成多样性,增加生成交互性等等。它也需要考虑一些伦理和社会的问题,比如保护用户的隐私,防止滥用和误用,尊重版权和肖像权等等。
代码地址:
https://github.com/facebookresearch/audio2photoreal/
项目地址:
https://people.eecs.berkeley.edu/~evonne_ng/projects/audio2photoreal/
好了,今天的内容就分享到这里希望你们喜欢!
出自:https://mp.weixin.qq.com/s/_t8uhnjQ6Jz-2z_wA_NHTQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip