前言
Stable Cascade 模型最大的优点是
是能生成带有文字的图片,文字出错率相比以前模型少很多;
其次是硬件要求降低,甚至与sd1.5相比,该架构比之前版本实现了16倍的成本降低;
最后一大亮点是模型更加理解提示词语义。
这篇文章带大家详细了解Stable Cascade 模型。最后我整理打包了此模型,【Stable cascade模型+安装方法+工作流】整套放在了文章最后,伙伴们自行下载~
01
前言
Stable Cascade 模型最大的优点是
§
是能生成带有文字的图片,文字出错率相比以前模型少很多;
§
§
其次是硬件要求降低,甚至与sd1.5相比,该架构比之前版本实现了16倍的成本降低;
§
最后一大亮点是模型更加理解提示词语义。
§
这篇文章带大家详细了解Stable Cascade 模型。最后我整理打包了此模型,【Stable cascade模型+安装方法+工作流】整套放在了文章最后,伙伴们自行下载~
02
效果对比(Cascade 模型与SDXL模型)
左边使用Cascade模型出的效果图片
右边使用SDXL模型出图效果:


提示词:
text“stable”,Made from green shrub leaves,


提示词:
text“stable”, The text is made of colorful energy.


提示词:
A cute cat


提示词:
a cat eating a piece of cheese


提示词:
A high-definition full body photo of a beautiful Asian
girl in a summer park,full-size photograph,full-size
photograph
通过以上的图片,小伙伴更喜欢哪种模型出的效果呢~
根据官方给到的评估结论,在几乎所有比较中,Stable Cascade 在理解提示词语义方面和美观质量方面都表现最好。
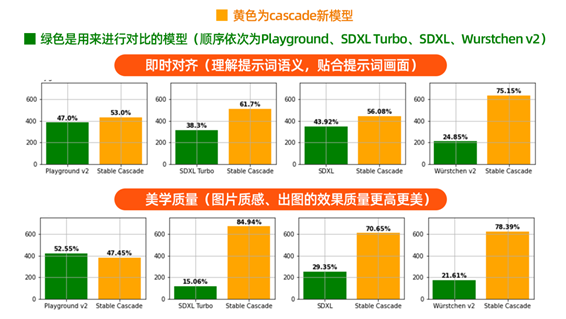
Stable Cascade 模型和其他模型的数据对比
03
Cascade模型是什么?
Cascade模型与之前的sd模型相比,主要区别是可以在更小的潜空间中工作。
潜空间可以简单理解为ai计算生成图片的区域,潜在空间越小,推理速度就越快,训练成本也就越低。
之前的sd模型如果想要生成一张1024*1024的图片,在潜空间的编码为128*128,使用的压缩因子为8,可以简单的理解为1024*1024的图片除以8(压缩因子)等于在潜空间的编码大小128*128。
而Stable Cascade 的压缩系数为 42,这意味着可以将 1024x1024 图像,在潜空间的编码为 24x24,这样就可以使用更小的潜空间尺寸,并且实现清晰的图像输出。甚至与sd1.5相比,该架构比之前版本实现了16倍的成本降低。
因此,这种模型非常适合快速的生成高质量图片。并且当前已知的扩展(如微调、LoRA、ControlNet、IP 适配器、LCM 等)也可以通过此方法实现。
04
Cascade的文件结构
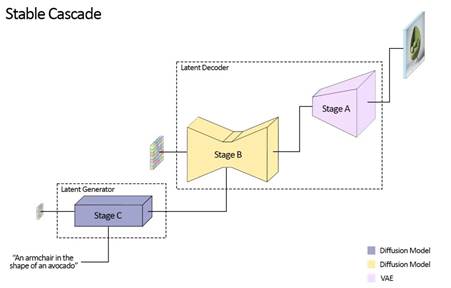
Stable Cascade 模型逻辑流程图
1.Stable Cascade由三个模型组成
Stage A、Stage B和Stage C,代表级联生成图像。
【级联】是指多个系统、设备或组件按照一定的顺序依次连接起来,形成一个整体,其中前一个系统、设备或组件的输出作为后一个的输入。因此得名“Stable Cascade”。
2.Stable Cascade如何级联运行
A 阶段和 B 阶段用于压缩图像,类似于stable diffusion中
VAE 的工作。然而,通过这种设置,可以实现更高的图像压缩。此外,阶段 C 负责在给定文本提示的情况下生成小的 24 x 24 潜伏。
比如输入提示词“鳄梨形状的扶手椅”,就会进入到第一步潜在的生成器,并且使用stage C模型生成较小的潜在图像,生成完成后,会进入到stage B和stage A,对生成的潜在图像内容还原到像素空间。
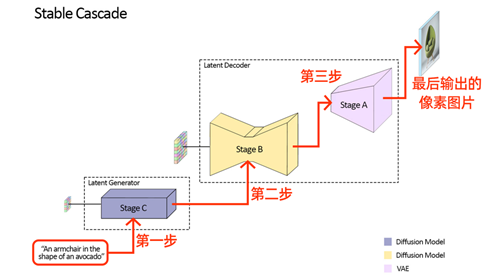
Stable Cascade 模型输入提示词后的生成流程
05
使用Cascade模型的流程和工作流搭建
 下载模型
下载模型
1.模型下载分为两个部分:Cascade模型+clip模型;
2.cascade模型又分为stageA,stageB,stageC,官方对stage C和stage B分别提供了两个版本,每个模型只需要下载其中一个即可;
3.其中stage C 提供 10 亿和 36 亿参数版本,官方强烈建议使用 36 亿版本,生成的图像会有更加有细节。
Stage B 的两个版本分别达到 7 亿和 15 亿个参数。15 亿擅长重建微小而精细的细节。
4.最后,Stage A 包含
2000 万个参数,只有一个版本直接下载默认版本的即可。
如果你的电脑性能足够,当前建议直接下载较大文件体积的模型,能够获得更好的结果。
clip模型在text_encoder文件夹,只有一个版本,下载model.safetensors模型即可。
这些模型我也打包好了,放在文章的最后,可以直接下载使用。
 安装模型
安装模型
将stage C和stage B这两个模型放置到ComfyUI根目录\ComfyUI\models\unet文件夹中。

stage C和stage B这两个模型放置的文件位置
stage A模型放置到ComfyUI根目\ComfyUI\models\vae文件夹中

stage A模型放置的文件位置
最后将clip模型放置到ComfyUI根目录\ComfyUI\models\clip文件夹中,这样使用cascade的模型安装也完成了。
clip模型放置的位置
 更新Comfyui版本
更新Comfyui版本
将comfyui更新到最新版本即可,官方将需要的模块已经同步进模型包了,
comfyui的更新方法,打开秋葉的启动器,具体怎么将秋葉启动器安装到官方的comfyui包中,可以参考这条视频的方法。
【设计师学Ai】哔哩哔哩搜索账号可看
一分钟教你使用秋葉启动器对Comfyui进行升降版本,版本管理:
https://www.bilibili.com/video/BV1Hg4y1Z7jX/?spm_id_from=333.999.0.0&vd_source=dc3d11f39507747c7c5bdabc3c1bf2c5
点击“版本管理”-右上角的“一键更新”按钮,即可将comfyui更新到最新版本。
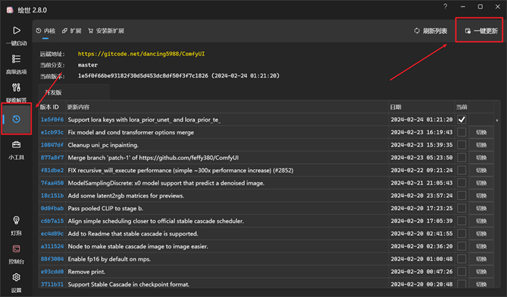
秋葉启动器安装到官方的comfyui包,进行一键更新
 工作流搭建
工作流搭建
拿到官方更新的cascade工作流之后,工作流应该会默认安装好这四个模型,你也可以点击模块上的模型加载位置检查模型是否加载完成。
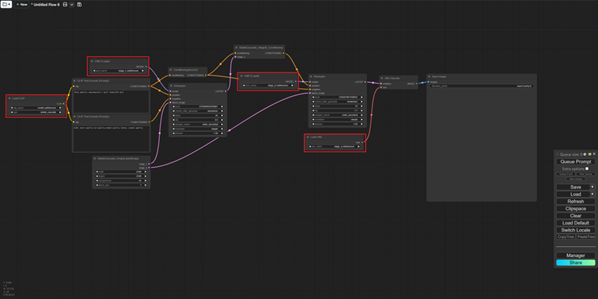
四个模型安装位置
并且需要注意load clip模块上,模型的种类是否选择的是“stable_cascade”,并且加载的是刚刚下载的clip模型,你也可以给这个clip模型修改一下名称,例如“cascade_clip_model”这样就不会与其他的clip模型混淆。
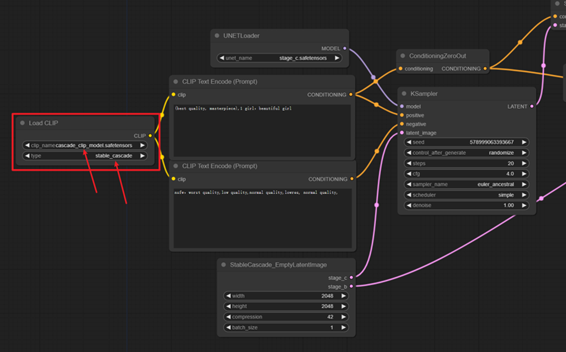
确定模型种类的位置,千万别混淆了
完成以上设置之后,就可以填写提示词,进行图像生成了。
 Cascade模型效果展示
Cascade模型效果展示
文字相关:在6个及以下字母的单词生成的准确率非常高,准确率能达到80%。但是超出7个字母后,想要直接生成拼写无误的单词比较困难,准确率在20%左右。
文字效果如下:








电影海报效果如下:








06
文章末尾:最后总结
新模型发布:Stable Cascade 在研究预览中发布,采用三阶段方法,提高了质量、灵活性、微调能力和效率,同时进一步降低了硬件要求。
技术细节:Stable Cascade 包括三个阶段(A、B、C),通过分层压缩图像,实现了使用高度压缩的潜在空间达到显著的输出效果。
训练和微调:提供了针对不同阶段的训练和微调脚本,特别是Stage C,可以单独进行训练或微调,显著降低成本。
参数规模与效率:Stage C 提供10亿与36亿参数两种模型,Stage B 提供7亿与15亿参数两种模型,强调了效率和质量的平衡。
出自:https://mp.weixin.qq.com/s/2u6RYjZccgm_4x3Cxy_vAw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip