要问当前AI大型语言模型界万众期待的一件事,以及各通用大模型厂商都在暗自铆足劲干的一件事,一定是追赶GPT-4。
要问当前AI大型语言模型界万众期待的一件事,以及各通用大模型厂商都在暗自铆足劲干的一件事,一定是追赶GPT-4。
回顾过去的2023年,国内整个AI行业度过了繁忙而又充满激情的一年。上半年经历了融资大战、抢人组团队,下半年迎来大模型井喷式爆发,进入模型汹涌期和商业化落地探索初期。据公开资料显示,截至去年10月份国内已经发布了238个大模型,意味着中国过去每天都有一个新的大模型发布,我们会发现大家在介绍自家大模型时,纷纷提到模型能力“接近GPT-4”,有胆大者甚至宣称“赶超GPT-4”。一时间,仿佛中国大模型已经领先国际先进水平,给不懂大模型技术、关注中国AI发展的投资者、用户带来许多不切实际的幻想与信心。因为事实情况远非如此。去年11月时,元象XVERSE科技创始人、腾讯公司前副总裁姚星曾告诉雷峰网,大家都说接近GPT-4,显然不符合实际情况,很多都是刷榜刷出来的,意义不大。“刷榜是我们的一个陋习”,这导致的结果就是大家对中国大模型的能力没有清晰的认知,实际上大家离GPT-4还差得远。虽然,随着OpenAI大模型论文发布、Meta开源强势入局,大模型的神秘面纱被一一揭下,我们与国外大模型的差距在逐步缩短,但别人模型的天花板GPT-4,我们依然还远未触达。这依然是一个有很高门槛的事情,训练模型需要大量钱、需要写过模型训练代码的人、需要坚定的技术路线和公司战略层面坚持不懈的投入,不是谁喊上一嗓子,中国大模型就能跟GPT-4同台竞技。所以,在刷榜成习的时代,我们应该把注意力、资源倾斜给那些真正为中国大模型事业,不断努力付出的团队和人身上,而不需要鱼目混珠之下的“盲目自吹自擂”。追赶GPT-4已然是国产大模型当下最迫切的任务,而对于通用大模型厂商,谁能率先训练出真正比肩GPT-4的大模型,谁就能“先入咸阳”,在商业化、生态上迎来进阶。对于谁能率先突破GPT-4门槛的猜测、讨论和押注,在过去的一年中激烈地进行着,终于,直到今天智谱AI发布了新一代基座大模型GLM-4,模型性能相比上一代全面提升60%,各项指标逼近GPT-4,让我们看到“国产GPT-4”真的来了。意料之中的结果,但没想到他们速度如此快。
01
最强大模型GPT-4,一直无人赶超
2023年春节后,辞旧迎新,一波关注AI的投资人偶然间使用了ChatGPT(GPT-3.5),被震惊,一传十、十传百,在投资圈带起了一波ChatGPT热潮,随着时间不断发酵,遂带动了整个中文互联网“膜拜”ChatGPT的热潮。当人们尚未从ChatGPT带来的震惊中冷静下来,一个月后,OpenAI又推出了新品GPT-4,一个更强大的大模型,再次点燃了人们对大模型的想象力。
它强大到什么程度呢?一张网站的手绘草图,GPT-4能直接生成最终设计的网页代码;GRE考试接近满分;模拟律师考试中GPT-4击败了90%的人类,取得了前10%的好成绩,相比之下GPT-3.5是倒数10%。GPT-4在各种专业测试和学术基准上的表现与人类水平相当。其中,GPT-4最大的突破是能够处理图像,并能准确理解图片的含义,给出解答。种种惊人的表现导致GPT-4一问世,便成为最强的大模型,成为全球科技公司共同追逐的目标。回归自身,在这波大模型竞争中,一致认为中国的突破口和优势在于我们应用场景丰富,拥有超大规模市场,是最能把大模型应用起来的。那我们直接用开源大模型不就行了吗,为什么一定要耗费巨大精力去追逐GPT-4呢?首先,正如智谱CEO 张鹏所说,一个好用的基座大模型,归根结底要看基座大模型的能力够不够用。当前国产大模型真要落地到实际场景中,要给企业带来业务价值,模型的通用能力还需要很大提升。而放眼当前最先进的模型GPT-4,它虽然不断在进化出新的类人能力,但目前依然连最基本的“模型幻觉”问题都没能彻底攻克,AGI短期内依然是一场人类自身的“颅内狂欢”。“真正落实到B端,光靠chat类产品好像也不够。”而张鹏认为,目前大模式商业化落地上遇到的挑战,本质上还是模型能力的突破。既然优等生都还有上升空间,我们又有什么资格不进步,何况国产大模型的模型能力尚且还不足以支撑诸多业务场景的商业化落地,所以目前GPT-4依然是值得奋力追逐的目标。其次,站在国家层面,技术自主可控是大势所趋,仰望最远大的技术理想依然是我们必须要达到的彼岸。“现在主要看谁能赶上或者超过GPT-4,很有可能大部分厂商都过不去。”某深入了解大模型生态的业内人士表示,他还特别指出,Meta的Llama2发布后,模型能力一度接近GPT-3.5,但至今Meta一直没有发布新进展,以此看来大模型技术门槛依然很高,这将对国内很多团队都是一个考验。而国内很多厂商都是基于Llama开源来训练的模型。
02
GLM-4,性能直逼GPT-4
今天,1月16日,智谱AI(以下简称“智谱”)在北京举办了2024智谱AI技术开放日,发布了新一代基座大模型GLM-4。据智谱透露,GLM-4在基础能力上实现大幅提升,性能相比上一代GLM-3全面提升60%,而根据智谱提供的测评数据显示,GLM-4性能逼近GPT-4。首先是基础能力上,MMLU 81.5 达到GPT-4 94% 水平,GSM8K 87.6 达到GPT-4 95% 水平,MATH 47.9 达到GPT-4 91%水平,BBH 82.25 达到 GPT-4 99% 水平,HellaSwag 85.4 达到GPT-4 90%水平,HumanEval 72 达到 GPT-4 100%水平。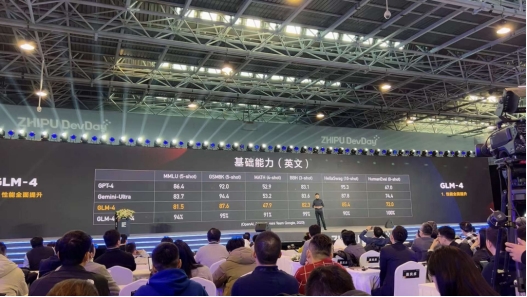
指令跟随能力上,和 GPT-4 相比,IFEval在Prompt提示词跟随(中文)方面达到 88% 水平;在指令跟随(中文)方面,达到 90% 水平。大大超过GPT-3.5。对齐能力上,基于AlignBench数据集,GLM-4超过了GPT-4在6月13日发布的版本,逼近GPT-4最新(11月6日版本)效果,在专业能力、中文理解、角色扮演方面超过GPT-4精度。在中文推理方面的能力还有待进一步提升。令人讶异的是,智谱本次发布,展示了GLM-4过去一年里努力追赶GPT-4的成绩,在多个模型测评中基础能力都达到GPT-4的90%水平,取得的这个成绩已然非常难得,但他们并没有干脆称“赶超GPT-4”,而是秉持着实事求是的低调态度,展示了GLM-4性能只是“逼近”GPT-4,与GPT-4仍然有差距,甚至还特地指出了自己当前的不足之处,需要“更进一步提升”。与当下浮夸风盛行不同,智谱给人的感觉一直是那个“低调的学霸”。除了性能上的提升,GLM-4支持带来 128K 上下文窗口长度,单次提示词可处理文本达到 300 页。在 needle test 大海捞针测试中,128K 文本长度内 GLM-4 模型均可做到几乎百分之百精度召回。基于GLM模型拥有的强大的Agent能力,智谱推出了GLM-4-All Tools,能根据用户意图,自动理解、规划复杂指令,自由调用WebGLM搜索增强、Code Interpreter代码解释器和多模态生成能力以完成复杂任务。多模态已经成为AI发展的重要方向和路径,可以看到头部大模型厂商都在往多模态发展,例如Meta的SAM、OpenAI的GPT-4V到谷歌Gemini,再到今天的CogView3,智谱一直在“对齐”世界先进水平。模态指表达或感知事物的方式,每一种信息的来源或形式都可以称为一种模态。视觉模态是直接从现实世界获取的初级模态,数据源丰富且成本低廉,相比语言模态更直观更易于理解。现实应用中,文本、图像、声音是经常穿插在一起交互的,并不都是纯文本。在一些复杂的应用场景中,纯文本的交互方式会受到文本表达能力的限制,使得复杂的概念或需求难以传达,相比之下,多模态模型中的图像交互方式门槛就更低,更为直观。一位证券分析师认为,多模态技术的一小步将带来产业应用落地的一大步。多模态是大语言模型走向千行百业乃至通用人工智能重要的里程碑。所以,AI要渗透到各行各业,大模型向多模态发展是必然趋势。而此时,智谱在大模型产业落地上,已经奔跑了十个多月。本次,GLM-4的多模态能力也实现了明显提升,文生图和多模态理解都得到增强,CogView3效果明显超过开源最佳的Stable Diffusion XL,逼近最新OpenAI发布的DALLE3。在对齐、保真、安全、组合布局等各个评测维度上,CogView3的效果都达到 DALLE3 90%以上水平。智谱AI CEO张鹏在技术开放日上表示:GLM-4的推出标志着国产大模型水平看齐世界先进水平,为我们全面开辟国产大模型产业新局面奠定了根本性基础。GLM-4的发布,将会成为国产大模型发展的一个分水岭,给大模型商业化、产业落地带来更多想象空间。
03
GLM-4让大模型进入商业化加速时代
在去年ChatGPT刚刚点燃中文互联网时,智谱就决定开始做商业化。据智谱透露,从今年3⽉以来,见过的客⼾超过2000家,与其中1000多家形成合作,与超过200家进行了深度共创。站在整个大模型前进的历程中,我们可以看到,智谱过去一年始终围绕着商业化紧锣密鼓地展开,相比较于其他头部大模型创业公司10月以后才开始喊商业化,智谱的商业化差不多领先行业半年。而商业化也一度面临着挑战。CEO张鹏在去年10月底时曾坦诚地告诉雷峰网,智谱的大模型面临“叫好不叫座”的挑战,即很多人认可,但提到付费购买,就会打退堂鼓。一方面是大家对大模型的认知不够,另一方面的原因很现实,有GPT-4在前面摆着,用户对大模型即便不甚了解,但都知道GPT-4,就会问智谱的模型离GPT-4还有多远。对于商业化,当时张鹏认为,如果某一天做到GPT-4的水平,当前面临的很多问题都会迎刃而解,甚至连商业模式都不用考虑,只提供API就行。没想到仅仅只过去了两个多月,GLM-4便能比肩GPT-4,这对智谱整体发展和商业化都将是重大利好。而这次技术开放日上,智谱还推出了一系列推动GLM模型生态加速构建的重要措施。其中最重要的就是GLMs个性化智能体。基于GLM-4 模型强大能力,任何用户用简单的提示词指令就能创建属于自己的 GLM 个性化智能体。GLM模型智能体和智能体中心已经于技术开放日当天上线。除此,智谱AI还针对商业客户、开源社区和大模型小微企业等合作伙伴推出多项针对性措施。比如价格,GLM-4升级后,API调用价格维持0.1元/千tokens不变,这已经是行业内较低水平。另外,智谱AI还将成立总额1000万元人民币的大模型开源基金,以及对面向全球大模型创业者的智谱AI“Z计划”进行升级,联合生态伙伴发起总额10亿人民币的大模型创业基金用于支持大模型原始创新。以上推动GLM模型生态的多种措施,为构建智谱的生态圈,其本质也是为智谱的商业化落地添砖加瓦。根据智谱AI 首席运营官张帆所说,在过去的9个月里,他带领着智谱走过了从最初“卖模型”到一整套商业化体系的搭建。智谱的商业化体系呈一个金字塔,最基层是开源层,开源拥有千万下载,非常大的群体,张帆在跟客户聊的时候发现,很多技术人员入门都是用ChatGLM;上一层是API层,核心的日常调用API的客户;再往上一层是云端私有化,面向中型企业,中型企业不但有使用模型的需求,它也希望能够把业务中的数据资产转化为自己的竞争壁垒;最高层就是本地私有化,很多企业对安全性要求极高,或者很多企业希望把模型能力转化为自己的,希望自己能够驾驭模型,这一类量会更少一些。对于智谱来说,每一层都有自己的生态位,商业化目标是希望下层用户不断往上层移动,逐步丰盈智谱的商业化。这非常符合智谱的发展策略:始终坚持技术与商业化两条腿走路。GLM-4的发布,将会给整个大模型行业带来震动,促使大模型转身进入商业化加速时代。
04
后记
2023年3月14日,GPT-4发布的同一天,智谱AI跟着便发布了基于千亿基座模型的对话模型ChatGLM,并开源了中英双语对话模型ChatGLM-6B,可支持在单张消费级显卡上进行推理使用。智谱AI对标OpenAI的野心就此凸显。而今天GLM-4的成功发布,是智谱过去一年里践行向世界最先进水平看齐的谦逊,也是智谱的决心与信心的实现。智谱对标OpenAI的目标正在一步步实现。而今天的GLM-4性能直逼GPT-4,给国产大模型追赶甚至超越GPT-5、GPT-6……在实现AGI这条道路上赋予了信心与坚持。就像Sam Altman说的,“永远要更快”,大模型时代把一切都加速了。在2024年的第一个月智谱AI率先出击,可谓给2024年的激烈竞争定下了基调,不禁让人更加期待未来人工智能行业还会带给我们怎样的惊喜。
出自:https://mp.weixin.qq.com/s/kUZ4ppL9ZMFM2oEn6dtLkA
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip