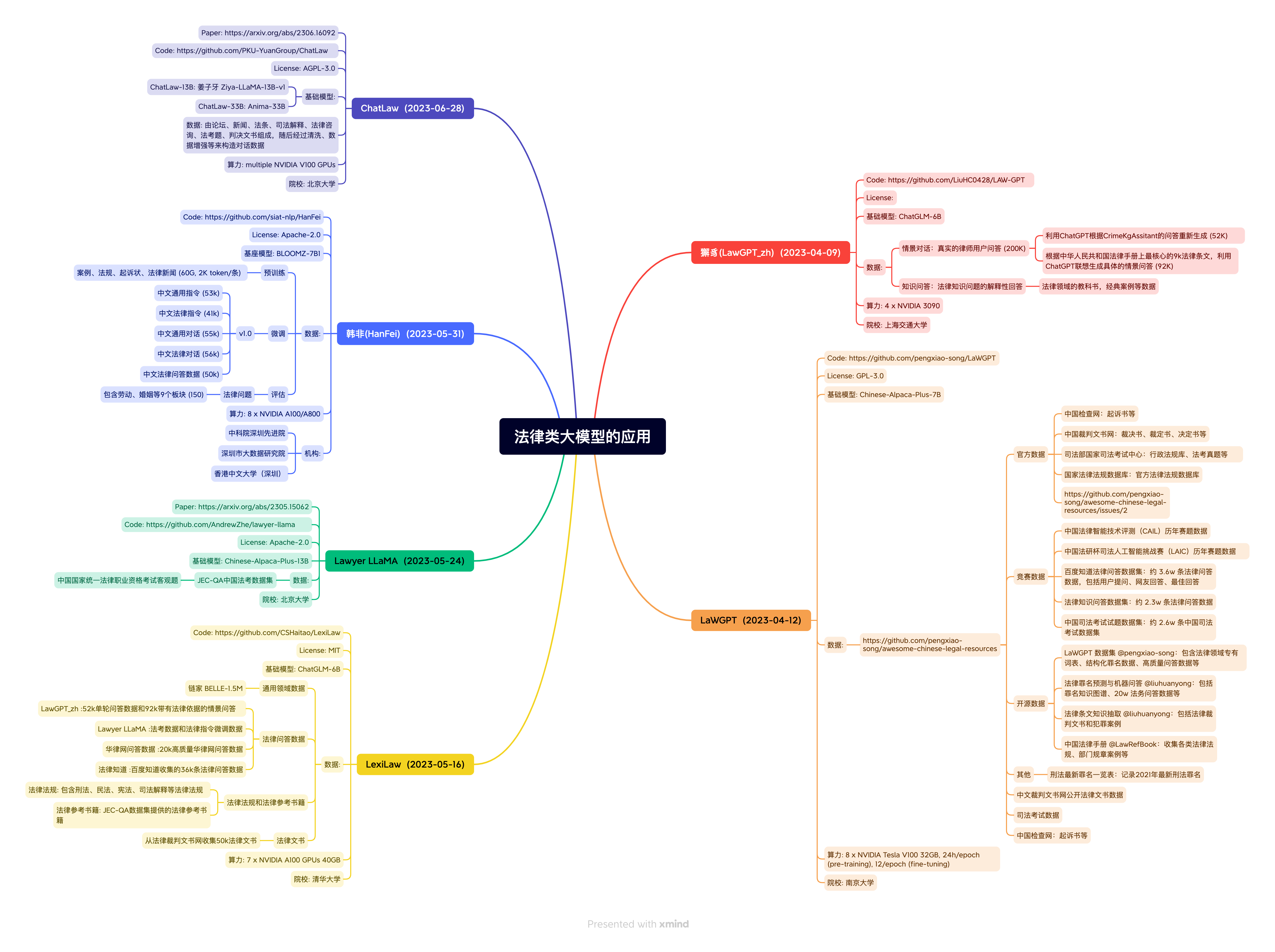
这篇文章列出了国内法律领域的大型语言模型,包括ChatLaw、韩非、Lawyer LLaMa、LexiLaw、LawGPT_zh和LawGPT。每个模型的基础架构、数据来源、预训练、开源数据和评估等方面进行了详细的描述。此外,文章还提到了各模型的学校或机构背景,以及模型的开源代码链接。这些模型在法律知识问答、法律咨询和法律文档处理等方面具有重要的应用价值。
国内法律类大模型列表:
1. ChatLaw (2023-06-28)
*
基础模型:ChatLAW-13B
*
数据:论文、新闻、法规、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造训练数据
*
算力:multiple NVIDIA V100 GPUs
*
学校:北京大学
*
Code: https://github.com/PKU-YuanGroup/ChatLaw
2. 韩非(HanFei)
(2023-05-31)
*
基础模型:HanFei-2.0
*
数据:案例、法规、起诉状、法律新闻(40G,2K词库)
*
预训练:中文通用指令(53k)、中文法律指令(4k)、中文通用对话(55k)、中文法律对话(54k)、中文法律问答数据(50k)
*
包含模块:聊天、摘要等各个模块(150)
*
评估:法律问题
*
算力:8 x NVIDIA A100/40GB
*
机构:中国科学院深圳先进技术研究院、深圳市大数据研究院、香港中文大学(深圳)
*
Code: https://github.com/siat-nlp/HanFei
3. Lawyer LLaMa (2023-05-24)
*
基础模型:Chinese-Alpaca-Plus-13B
*
数据:中国国家统一法律职业资格考试题库、JEC-QA中国法考数据集
*
算力:7 x NVIDIA A100 GPUs 40GB
*
学校:清华大学
*
Code: https:/github.com/AndrewZhe/lawyer-llama
4. LexiLaw (2023-05-16)
*
基础模型:ChatGLM-6B
*
数据:法律问答数据、法律知识、百度收集的54k条法律问答数据、法律法规、包含刑法、民法、宪法等法规、法律参考书籍、JEC-QA数据集提供的法律参考书籍、从裁判文书网收集的50k法律文书
*
开源数据:LaWGGT数据集(@pengxiao-song:包含法律领域专有词汇、专业名词、高引指令等)、法律各领域词表和词向量 @lihuanyong * 包括法律词表、20w法律问答数据、法律文书和犯罪案例、中国法律术语 @lawBook:收集各类法律法规、部门规章案例等
*
算力:8 x NVIDIA Tesla V100 32GB、24h/epoch
(pre-training), 12/epoch (fine-tuning)
*
学校:南京大学
*
Code: https://github.com/csHaitao/LexiLaw
5. LawGPT_zh (2023-04-9)
*
基础模型:ChatGPT-6B
*
数据:ChatGPT根据CrimeAssistant的问题重新生成(52k);根据中华人民共和国手上最核心的法律条款,利用ChatGPT接收生成的情境问答(92k);法律领域的教科书、经典案例等数据
*
知识问答:法律知识问题的精准回答
*
算力:4 x NVIDIA 3090
*
学校:上海交通大学
*
Code: https://github.com/LiuHC0428/LAW-GPT
6. LawGPT (2023-04-12)
*
基础模型:Chinese-Alpaca-Plus-7B
*
数据:情境对话:真实的律师用户问答(200k)
*
知识问答:法律知识问题的模糊回答
*
利用ChatGPT根据CrimeAssistant的问题重新生成(52k)
*
根据中华人民共和国手上最核心的法律条款,利用ChatGPT接收生成的情境问答(92k)
*
法律领域的教科书、经典案例等数据
*
算力:8 x NVIDIA V100 32GB、24h/epoch
(pre-training), 12/epoch (fine-tuning)
*
中国裁判文书网:裁判书、裁定书、决定书等
*
官方数据:司法部国家司法考试中心:行政法规、法考真题等
*
国家法律法规数据库:官方法律法规库
*
中国法律智能技术测评(CAL)历年赛题数据
*
中国法研杯人工智能挑战赛(LAC)历年赛题数据
*
百度知道法律问答数据集:约 3.6w 条法律问答数据,包括用户提问、问题回答、最佳回答
*
法律知识问答数据集:约 2.3w 条法律问答数据
*
中国司法考试试题集:约 2.6w 道中国司法考试试题
*
LaWGPT 数据集(@pengxiao-song:包含法律领域专有词汇、专业名词、高引指令等)
*
法律各领域词表和词向量 @lihuanyong * 包括法律词表、20w法律问答数据、法律文书和犯罪案例
*
中国法律术语 @lawBook:收集各类法律法规、部门规章案例等
*
刑法最新罪名一览表:记录2021年最新刑法罪名
*
中文裁判文书网公开法律文书数据
*
司法考试试题
*
Code:Code: https://github.com/pengxiao-song/LaWGPT
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip