文章介绍了文本到图像生成技术的最新进展,特别是稳定扩散模型(SD)和潜在一致模型(LCM)。SD模型能够生成高质量、高分辨率的图像,但生成速度慢。LCM通过知识蒸馏技术将SD模型压缩为更小、更快的模型,将生成步数从25到50步降低到4到8步,提升了生成速度5到10倍,实现实时生成。LCM保留了SD模型的生成质量,同时实现了与SD模型潜在空间的一致性,可用于编辑和操作图像。LCM训练高效,原理基于低秩适应技术,可作为通用的稳定扩散加速模块嵌入各种模型中。LCM为文本到图像生成领域带来新可能性,相关论文和代码已在公开平台上发布。
近年来,随着SD和Midjourney的火热,文本到图像生成(Text-to-Image Generation)的研究取得了令人瞩目的进展,让我们能够用自然语言指导AI创造出各种各样的图像。文末有地址⬇
最强绘画AI midjourney的美图欣赏!

文本到图像生成的核心技术之一,就是稳定扩散模型(Stable Diffusion Models,简称SDM或SD)。
SD模型的优点,它可以生成高分辨率、高质量、高多样性的图像,而且可以很容易地与其他模型结合,比如变分自编码器(VAE)或对抗生成网络(GAN)。
SD模型也有一个明显的缺点,那就是生成速度很慢。由于扩散过程需要多次迭代,每次迭代都要用到一个神经网络,所以SD模型的生成过程需要大量的计算资源和时间。一般来说,SD模型需要25到50步才能生成一张图像,这对于实时应用来说是不可接受的。
Latent Consistency Models是什么?
为了解决这个问题,清华大学的研究者提出了一种新的技术,叫做潜在一致模型(Latent Consistency Models,简称LCM)。

LCM的思想是,通过对原始的SD模型进行知识蒸馏(Knowledge Distillation),将其压缩为一个更小、更快的模型,从而大大减少生成所需的步数。
LCM可以将SD模型的生成步数从25到50步降低到4到8步,这可以将SD模型的生成速度提升5到10倍,从而实现实时生成的效果。
我们来看看网上发出的效果!
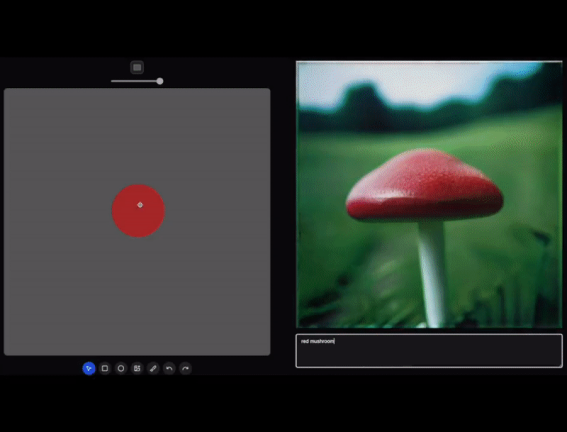

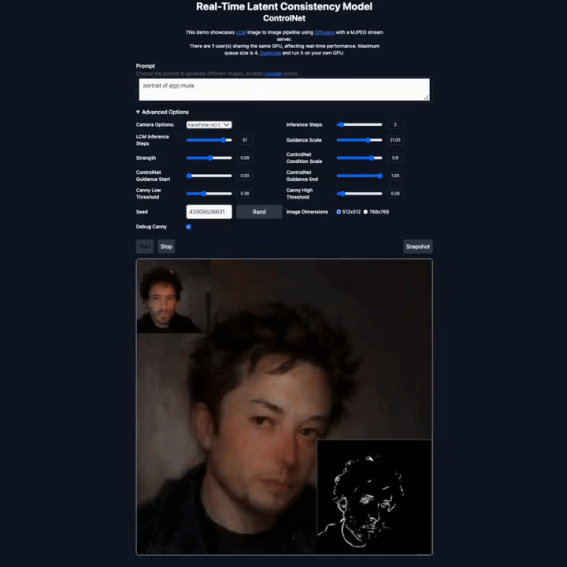
效果看起来是不是很赞?!
LCM和传统的SD漫长的时间相比,可以算实时生成了!
LCM的特点!
LCM不仅保留了SD模型的生成质量,而且还能够实现与SD模型的潜在空间(Latent Space)的一致性,即用LCM生成的图像可以用SD模型进行编辑和操作,反之亦然。
LCM的效果非常显著,它可以将SD模型的生成步数从25到50步降低到4到8步。这意味着,生成速度提升5到10倍,从而实现实时生成。
LCM的训练过程也很高效,只需要大约32个A100 GPU的训练时间,就可以完成对SD模型的蒸馏。
LCM的原理是什么呢?
简单来说,LCM是一个基于低秩适应(Low-Rank Adaptation,简称LoRA)的神经网络,它可以对SD模型的扩散过程进行近似。
LoRA是一种用于模型压缩和加速的技术,它的基本思想是,将一个大的神经网络分解为一个低秩的核心网络和一个高秩的适应网络,从而减少参数的数量和计算的复杂度。
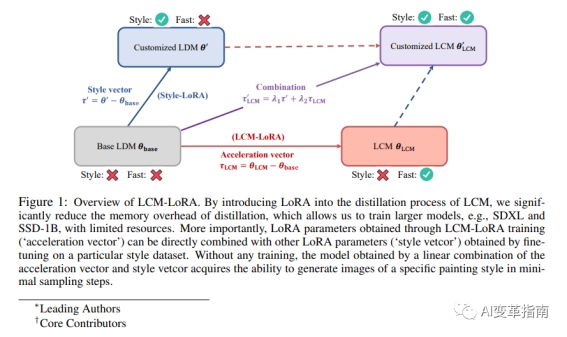
LCM利用LoRA的技术,将SD模型的神经网络分解为一个低秩的LCM网络和一个高秩的SD网络,然后用LCM网络来近似SD网络的输出,从而实现对扩散过程的加速。
LCM的优势不仅仅是速度,还有通用性。LCM可以作为一个通用的稳定扩散加速模块,即LCM-LoRA,直接嵌入到各种稳定扩散模型中,比如SD-V1.5、SSD-1B、SDXL等,而不需要重新训练。
这样,LCM-LoRA就可以为这些模型提供快速的生成能力,而且还能够保持与原始模型的兼容性。LCM-LoRA还可以与其他的LoRA模型结合,比如用于风格迁移或图像编辑的LoRA模型,从而实现多样化的图像生成任务。

LCM-LoRA是一种非常有前景的技术,它为文本到图像生成领域带来了新的可能性。
论文地址:
https://arxiv.org/pdf/2311.05556.pdf
代码地址:
https://github.com/luosiallen/latent-consistency-model
出自:https://mp.weixin.qq.com/s/mILqN7_F1FnPNW4IzKyIdw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip