大模型效果提升的关键在于训练数据集的质量。开源数据集为提升大模型效果提供了有效途径。最近出现的开源数据集包括SFT微调数据集和多个中文数据集。为推进中文AI的发展,成立了知识岛(KnowledgeDAO)项目,呼吁网友参与中文数据集的建设。高质量数据集的获取成本高昂,需要大家的共同努力。相关数据集地址已提供。
大模型的算法模型开源越来越多,大模型工程化也越来越稳定。但是大模型的效果,还是需要持续提升。大模型训练数据集的质量是提升大模型效果最有效的途径,也是最苦最累的脏活,积累前人已经整理开源的数据集,站在数据集巨人的肩膀上,持续迭代大模型。持续关注数据集,优化数据集。
下面是最近看到的开源数据集,后面也会持续积累,不断提升数据集的量和质,促进大模型效果步步提升。
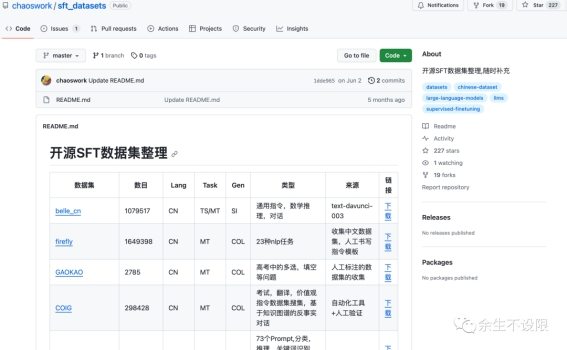
数据集一,开源SFT微调数据集。
数据集二,中文数据集:
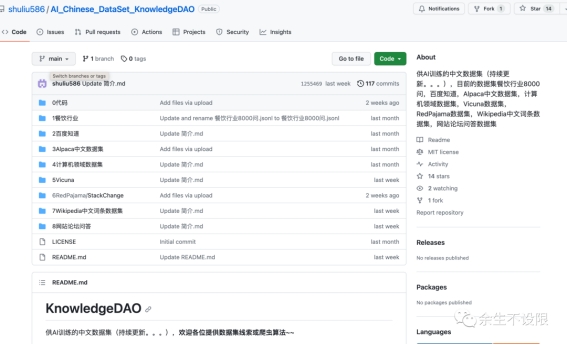
供AI训练的中文数据集,目前的数据集餐饮行业8000问,百度知道,Alpaca中文数据集,计算机领域数据集,Vicuna数据集,RedPajama数据集,Wikipedia中文词条数据集,网站论坛问答数据集。
为了推进中文AI的发展,促进AI技术公开化、国际化,我们成立了知识岛(KnowledgeDAO)项目,希望借助大家的力量推进中文AI数据集的建设。
数据、算法和算力,是AI发展的三大基石,其中数据的质量对模型最终性能至关重要。然而,从Hugging Face上的模型数据集数量来看,5W多的数据集中,英语的占比超过90%,优质中文数据少之又少。
高质量数据集的获取花费巨大,我们无力承担如此巨大的开销,于是需要各位有志于筹建开放获取语料,并有一定技术基础的网友们献上自己的力量。
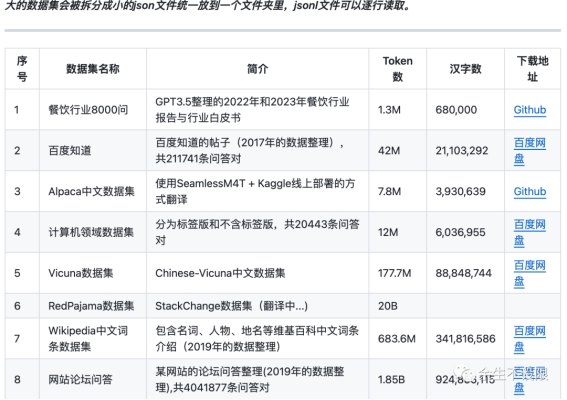
相关数据集地址:
https://github.com/chaoswork/sft_datasets/tree/master
https://github.com/shuliu586/AI_Chinese_DataSet_KnowledgeDAO
出自:https://mp.weixin.qq.com/s/g_eKxN6ej5xGuHvBU9oyHQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip