跨年之前,想总结一下去年上半年以来关于LLM Agents的学习经历,同时记录一下我在其中过程的一些想法。明年应该会去到一个新的平台学习和干活,所以今年得好好总结一下之前的学习和想法。本文会系统地组织起来,尽量多一些干货,并同时考虑普适性和专业性,也会有我个人的一些见解和思考。全文1.1w字,阅读时间约25分钟。
跨年之前,想总结一下去年上半年以来关于LLM Agents的学习经历,同时记录一下我在其中过程的一些想法。明年应该会去到一个新的平台学习和干活,所以今年得好好总结一下之前的学习和想法。本文会系统地组织起来,尽量多一些干货,并同时考虑普适性和专业性,也会有我个人的一些见解和思考。全文1.1w字,阅读时间约25分钟。
个人阅历有限,加上成文仓促,恳请各位包容。恳请诸位指出错误或不足,尽情提出需要补充内容的部分,我会尽力让本文变得更完善。感恩!
1 基准:LLM Agents 是什么
首先要明确LLM Agents是什么,这是讨论的基准。在此提供三个视角供大家参考:一是用户认识LLM Agents的方式,二是所有人都可以用来认识LLM Agents的方式,三是生产者(整个生产链条:研究人员、开发人员、产品经理、游戏策划等)认识LLM Agents的方式。学术上的定义已有很多文章提到,这里只是我比较喜欢的三个视角。
1.1 面向用户:实用主义定义
“能帮助某类用户的,基于大语言模型的产品就是LLM Agents。”我个人认为这是适合Agents用户认识LLM Agents的方式。
例如:对于需要日常助手的用户来讲,一个产品能够通过传统交互为主,自然语言为辅的方式,帮助用户安排好日程,提醒好会议,给出一些日常的生活工作建议,那这就是一个LLM Agent。
又例如:对于正在一个开放世界游玩的玩家来讲,一个NPC能够通过某种基于自然语言的方式同玩家进行交互,这种交互要么涉及到玩法,要么提供情绪价值,那这也是一个LLM Agent。
1.2 面向所有人:一种直觉定义
“只要是以LLM为核心的玩意,这玩意在一定外部环境下行动,有一定的内部模块,能够进行某种形式输入和进行某种形式输出,就是LLM Agents。”这是一种比较简单地认识LLM Agents的方式,强调了其基本性质和核心特点,即“以LLM为核心”和“内部模块”。提取一下相关要素:
00001.
以LLM为核心
00002.
00003.
外部环境
00004.
00005.
内部模块
00006.
00007.
输入和输出
00008.
举一个简单的例子:一个能联网搜索的LLM助手。其上述要素分别为:和用户交流以及和互联网接触的外部环境,进行搜索并处理结果的相关模块,接收用户输入并生成回复输出的LLM。
1.3 面向生产者:一种学术定义
我个人认为复旦NLP组的一篇综述所提出的LLM Agents框架,是比较全面的。这里给出原文的插图,并基于原文作一定分析,会相对难读一点,请诸位见谅。
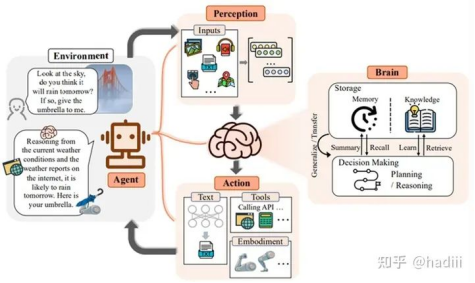
Conceptual framework of LLM-based agent with three components: brain, perception and action.
Agent首先是“运动”在“环境”(Enviroment)中的,环境描述了Agent所在的状态空间,运动则是一个抽象概念,可以将其理解为Agent所有行为的总和。Agent的一切都是和这个环境相关联的:包括其感知(输入),大脑(各种类型的内部处理)和行动(输出)。Agent也是环境的一部分,因而Agent的行动改变环境时也可以改变Agent自身。
Agent的“运动”可以被大致分类为感知,内部处理,行动三个部分。分别对应图中Perception,Brain,Action三个模块。Brain模块承担记忆、思考和决策等内在的任务;Perception模块负责感知和处理来自外部环境的多模态信息;Action模块负责使用工具执行任务并影响周围环境。三个模块也描述了一个Agent自身状态的全部组成。
其机理分别于类似于人类用眼睛耳朵等获得信息,用大脑用于处理信息和驱动四肢,用四肢改变环境和改变人类自身。
Agent的内部信息通路是Perception->Brain->Action,而信息通路的设计本身也应该是Agent的一部分。这类似于人类的神经信号传输,决定了一些Agent可表征的信息范围、信息损失和计算效率问题。宏观来看,Agent应该通过一轮或多轮的”输入->处理->输出“来完成一个任务,是否结束任务应由外界或内部的反馈信息来确定。
作为人类,很多时候我们完成了一件事才能看到结果,然后会通过对上一件事的结果再次"输入->处理->输出"。我们会得到反馈并推理出上一件事完成的效果如何,而正是通过这种反馈,我们才决定要不要继续做这件事和下一步怎么进行。这其实是多轮的"输入->处理->输出",只是对于人类是时时刻刻进行着的。
当然,还可以做更多的细分,详见原文:
《The Rise and Potential of Large Language Model Based Agents:A Survey》arxiv.org/pdf/2309.07864v1.pdf
2 深入:LLM Agents 的细分技术
了解了基本概念和框架之后,有必要简单了解一下其细分技术。在此大概分解一下LLM Agents所用到的一些技术点:大致是RAG,CoT,意图识别与执行,数据通路和行动框架,SFT,多模态这六点。细分技术部分由于个人能力有限,无法详尽,仅作抛砖引玉。但会尽量写一点新的东西,以减轻诸位食之无味的程度。
2.1 RAG:知识,记忆与技能库
2.1.1 RAG简介
RAG应该是大家耳熟能详的技术。官方一点地讲:RAG模型的核心思想就是将传统的语言生成模型(如GPT系列)与一个检索系统相结合,在处理一个输入时,RAG首先使用检索系统从一个大规模的文档集合中检索出相关的文本片段,然后将这些检索到的文本作为额外的上下文信息输入到生成模型中,以此来生成更加丰富和准确的输出。说白了就是给LLM一个字典让它查。
RAG在LLM Agents的用途包括:知识库导入,长期记忆支持,技能库支持等等。知识库导入不一定就是一条条干瘪的知识,也可以是一些风格化,个人化的东西。检索不一定就是只算语义相似度,也可以使用其他的一些检索函数。
RAG往往是结合向量数据库,但是对于简单应用而言,只需要JSON格式文件就能实现,甚至能轻易指向其他格式文件(如图像)。注意:这里的embedding是text embedding,即句向量,需要和词向量分开。句向量是将整个句子映射到向量空间,而计算句子语义相似度最常见的方式则是计算其text embedding之间的余弦相似度。而这种语义相似度除了可以进行文本检索以外,也可也用于识别用户意图,进行情感分析等等。
RAG有一个经典开源实现,即LangChain-ChatGLM。因为确实经典,所以这里只挂上其实现过程,不多赘述。感兴趣的读者可自行搜索。
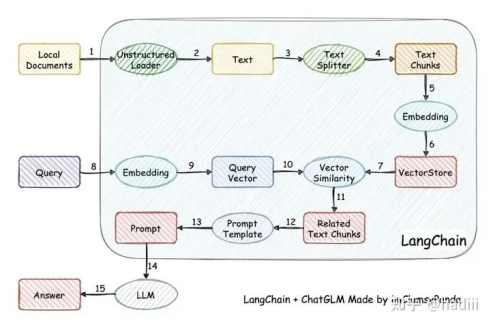
LangChain-ChatGLM
2.1.2 聊聊《Generative Agents》的检索函数
前面谈到,RAG的检索函数不一定只算语义相似度,可以有其他实现形式。比如《Generative Agents》里记忆流的检索函数。其检索函数的要素有三点,即[时效性,重要性,相关性]。时效性代表记忆最近被检索出的时间,重要性表明Agents对该记忆事件的重要性评估(一般是结合人设让LLM给出个分数,或许也可以用一个小模型做评分),相关性就是语义相似度。
检索记忆时,不再是按照语义相似度进行排序。而是在对三个特征进行最小最大归一化之后,计算一个综合评分,然后取Top k:
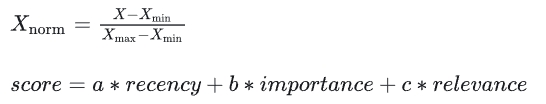
详见原文:
arxiv.org/pdf/2304.03442.pdfarxiv.org/pdf/2304.03442.pdf
2.1.3 RAG的语义孤立问题
RAG同样会出现一些问题。除了chunk本身就会丢失一些上下文以外(可以用交叠上下文来缓解),chunk的语义本身也是“孤立”的。这里是指:一段chunk中的文本可能需要chunk外的内容来帮助理解。例如有三个chunk分别为:
胡桃和宵宫是好朋友。
宵宫是“长野原烟花店”的现任店主。
胡桃是璃月“往生堂”第七十七代堂主。
对于一个通用LLM而言,如果它拿到的最相似匹配是“胡桃和宵宫是好朋友”,那其实LLM并不知道胡桃和宵宫是谁,并不一定能答好这个问题。这是因为:要理解一个知识,就需要理解其上层知识。在这个例子里,即“胡桃和宵宫到底是谁”。
针对于这个问题,向大家介绍一个比较简单的,面向原生JSON格式文件的优化方法,类似于分层检索:通过将知识库分层,首先在较高层次上对用户的查询进行理解和定位,然后再在更具体的层次上检索细节信息。这样一来,每次RAG时会拿到多级的语义,既有宏观认识也有最匹配用户Query的内容,或许能改善RAG效果。
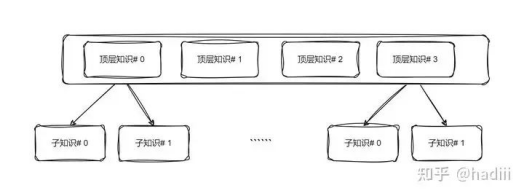
多级RAG结构
对于上面的例子,其两级组织格式就应该是:
顶层知识:宵宫是“长野原烟花店”的现任店主。胡桃是璃月“往生堂”第七十七代堂主。
↓指向
子知识:胡桃和宵宫是好朋友。
如此一来,每次检索到最相似的匹配是“胡桃和宵宫是好朋友。”时,就必然会附带上对胡桃和宵宫的简介。需要指出的是,由于没有向量数据库等高效存储检索系统,这并不是一种生产环境适用的高效方法。只适用于小型项目,如独立游戏。具体实现可以参考文章末尾的链接。
2.1.4 另一种方法
我之前也有看到过另外一种做法:即按照语义去切分段落。合并语义上相关联的段落,然后对段落生成一个描述句,以该描述句来生成嵌入向量。即以段落描述句的嵌入向量为键,段落的完整内容为值。我们可以简单对比一下这两种方法:
分层检索通过建立层级结构,使得检索能够从大范围的上下文逐步深入到具体细节,保持了信息之间的关联性,但可能会因为结构的复杂性和维护难度而影响检索效率。语义切分合并则侧重于将语义相似的内容动态组织在一起,通过为每个内容块生成描述性的句子来创建索引,这样可以提高检索效率,但有时可能会因为合并不当而丢失关键上下文。
实际上,这两种方法可以结合起来使用。例如,可以先通过分层检索方法构建一个宏观的知识框架,然后在具体的层级内使用语义切分合并方法来进一步细化信息组织。这样,既保留了层级结构带来的上下文关联优势,又能够利用语义相似度进行高效检索。
此处花了一些篇幅阐述RAG的问题和可能的解决方案,只是想说明RAG还是有很多可能性的。
2.2 CoT:问题分解与推理
2.2.1 CoT简介与两个例子
CoT指的是大家耳熟能详的思维链及其变种。即让LLM将一个复杂问题分解为级联的子问题,并依次进行顺序处理,可以显著提升LLM处理较复杂的性能。说白了就是让它多想几步。CoT既可以用在单次内容生成里,也可用在一条内容生成的Pipeline里。一般的例子的是用CoT做数学题,但大家可能看腻了:

Few-Shot CoT(图源:绝密伏击)
我这里倒是想给出一个基于想法进行风格化回复的例子,其广义上也是CoT的思路,并且很好理解,希望能让大家耳目一新。
直接让LLM做角色扮演对话会出现一些问题:例如,LLM喜欢抽取Prompt的要素而非好好说话;或是不怎么利用Prompt的要素而说一些无关紧要的话;又或是LLM干脆不知所措,说一些莫名其妙的话。我认为问题在于:LLM是需要“思考”后才能好好说话的,角色扮演(风格化对话)对于LLM其实是一个复杂问题。
因而可以将CoT的思想应用于风格化对话生成任务中,把对话生成分解为两个步骤:首先生成角色的内心思考内容,然后基于这些内容构建角色的回复。这样可以确保对话既符合角色的人设,又能够自然地融入到对话的流程中,经简单的主观测试,回复效果的确有提升。请大家重点关注下图左侧的生成部分(红框圈起来的部分):
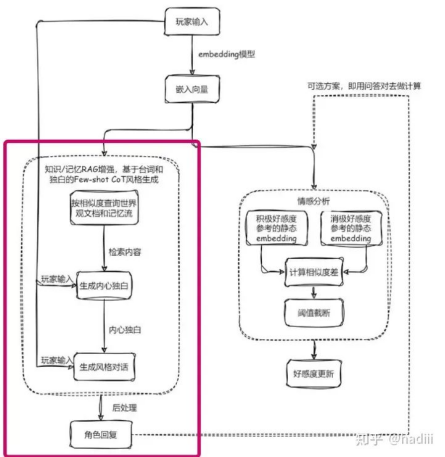
风格化对话-情感分析系统
具体的Prompt是这样组织的,应该比较好理解。请重点关注两段Prompt之间是如何联动的,即第一段生成的结果如何被嵌入到第二段Prompt当中:
thought_prompt = f"""
角色名称:{self.name}
初始记忆:{self.seed_memory}
当前心情:{self.mood}
任务:根据角色当前的相关记忆,相关知识,对话上下文进行分析,基于角色第一视角进行思考,给出角色的心理反应对和相关事件的判断。
字数限制:不超过100字。
<<<
相关记忆:“{memory['description']}”
相关知识:“{knowledge_text}”
对话上下文:
{self.language_style}
{context}
>>>
请仅返回{self.name}第一人称视角下的思考内容,不要添加额外信息或格式。
"""
response_prompt = f"""
角色名称:{self.name}
初始记忆:{self.seed_memory}
当前心情:{self.fsm.mood}
任务:基于角色的思考内容和对话上下文进行回复。
字数限制:不超过100字。
<<<
思考内容:“{thought}”
对话上下文:
{self.language_style}
{context}
>>>
请在思考内容和对话上下文的基础上,以{self.name}的身份回复。不要扮演其他角色或添加额外信息,不要添加其他格式。
"""
具体实现可以参考文章末尾的链接,仅以此作为例子介绍。CoT相关内容详见原文:
[2201.11903] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (arxiv.org)arxiv.org/abs/2201.11903
2.2.2 CoT变种
CoT的两个经典变种是ToT和Self-consistency。ToT是CoT的一个扩展,它不仅仅以线性的方式构建思维链,而是创建一个更为复杂的树形结构来进行推理。Self-consistency是另一种变种,强调在推理过程中保持一致性,会对语言模型进行多次采样, 生成多个推理路径。然后再对不同推理路径的生成结果,基于投票选择最一致的答案输出。
2.3 意图识别与执行
2.3.1 函数调用的例子
意图识别与执行是指让LLM基于上下文从一组备选项中选择合适的类别,根据需要填入相应的参数,并进行格式化输出的能力(注:意图识别与执行这个说法不一定准确,这里向大家讨教正确说法)。我个人认为这种能力在构建LLM Agent时非常重要。意图识别与执行包括工具使用,行为状态切换,理解环境反馈等(环境反馈的一个例子是:LLM生成的代码运行失败,Agent根据代码解释器返回的相关错误信息进行修改)。
事实上,对于工具使用,函数调用就是一个典型例子。我们这里以OpenAI对话接口的函数调用功能Function Calling为例。Function Calling的工作方式是:首先,我们提供一个工具函数或外部API的接口描述,包括其用途和参数;然后,根据用户的查询(Query),让LLM生成一个格式化的函数调用。
假设一个函数描述大概长这个样子,其描述了一个用于检索wiki百科的函数接口:
{
"name": "use_wiki",
"description": "检索wiki百科以补充不了解的知识",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "需要检索的事物"
}
},
"required": ["query"]
}
}
在这个例子中,LLM会解析用户的查询,并生成一个格式化的调用请求,如use_wiki(query="特定主题的关键词")。
2.3.2 状态切换的例子
意图识别与执行不止是函数调用。例如:在上下文中给定LLM一些情绪种类描述和情绪程度说明,要求LLM分析一段用户输入的情绪种类和情绪程度数值,并格式化地返回。又例如:要求LLM分析上下文中给出的一些状态和场景,并要求LLM根据场景决定其中的角色应该如何行动。这一类问题也算是意图识别与执行,这种能力往往作为某种中间步骤被使用。
意图识别与执行是构建LLM Agent时的一个重要能力,因为它允许模型进行决策并生成可操作的输出,这也是建立其数据通路与行动框架的基础。
这里给出一个最简单的用Prompt切换状态的例子,仅作示范:
任务:推理角色的下一个心情应该是什么。
<<<
角色当前心情:{self.mood}
观察到的事件:{trigger}
角色的想法:{thought}
可能的心情列表:{self.mood_list}
>>>
现在请根据角色目前的心情,观察到的事件和角色想法,从可能的心情列表中选择一个心情。例如:{self.mood_list[0]}。
心情可以是不变的。精确地输出心情名称,不要进行额外的输出。
2.4 数据通路与行动框架
数据通路通常指的是在Agent内部信息流动的机制,包括感知环境的输入、处理这些输入的中间步骤,以及生成输出或行动的最终步骤。行动框架则指的是Agent决策的算法和策略,它定义了Agent如何根据输入的数据和内部状态来选择行动。
两者共同定义了Agent到底以什么规则在对应的环境下行动。这里给出一些经典的框架图供参考,我倒是觉得不用过于纠结这个框架,面向业务去定义就好了:
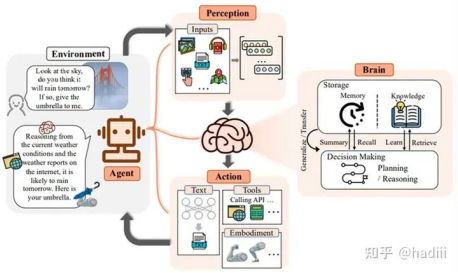
Conceptual framework of LLM-based agent with three components: brain, perception and action.
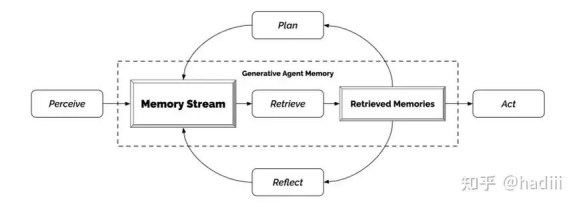
generative agent architecture.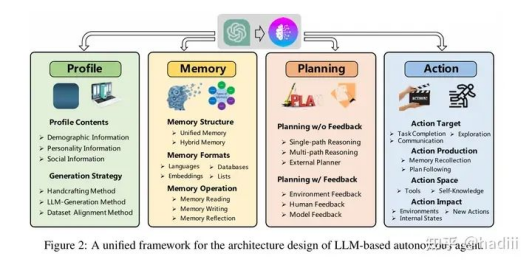
举个具体例子。《Voyager:LLM 驱动的具身终身学习智能体》用LLM来自我掌握技能和发现新事物,该智能体的数据通路与行动框架可以概括为以下几个构件:
00001.
自动课程(Automatic Curriculum):为智能体提供一系列逐步增加难度的任务,鼓励多样化行为和施加约束的指令,以促使其不断学习和进步。
00002.
00003.
迭代提示机制(Iterative Prompting Mechanism):用于引导智能体迭代和提升自身的技能,并引入环境反馈,程序解释器的执行错误,自我验证等。
00004.
00005.
技能库(Skill Library):用于存储智能体掌握的各种技能。通过存储成功解决任务的行动程序来逐渐构建技能库。
00006.
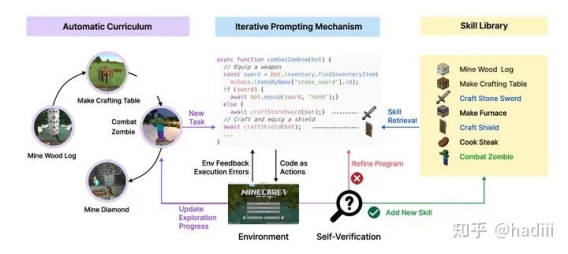
Voyager
Agent会试图解决由自动课程提出的越来越难的任务,不断地生成代码和接受反馈,自我纠错和自我验证。直到自我验证模块确认任务完成后,就把生成的代码技能添加到技能库。后续就可以使用技能库里的相关技能来辅助完成相关新的任务。
总结一下,其完成“自我进化”的行动要素就是三点:
00001.
保持Agent持续活动,不断地接受任务要求,进行学习尝试,进行自我验证。
00002.
00003.
自我验证成功后,把学习成果添加到知识库中。
00004.
00005.
Agent后续的活动可以以某种方法,使用之前添加到知识库的知识。
00006.
仅以此作为例子描述什么是数据通路与行动框架,详见原文:
[2401.01275] CharacterEval: A Chinese Benchmark for Role-Playing Conversational Agent Evaluation (arxiv.org)arxiv.org/abs/2401.01275
2.5 SFT简介:参数级别支撑
SFT当然不是Agent专有的话题,但对于LLM Agents而言,同样是重要的技术点。SFT即监督微调(Supervised Fine-Tuning)。SFT的一般目的是强化通用LLM在某个垂直任务上的能力,但也会出现“灾难性遗忘”这样的问题。
全参微调非常吃显存和计算资源,因而后续出现了各种各样的低资源微调方法。全参微调、Prompt Tuning、LoRA、P-Tuning等都在SFT这个范围里面。
最简单的SFT就是针对{prompt,response}的单轮问答pair进行微调,其数据格式组织如:
{
"prompt": "<prompt text>",
"response": "<response text>"
}
有必要指出的是,微调本身就是一门大学问,尤其是在真实业务场景中的微调。这些任务需要进行数据建设,模型训练,模型迭代的全过程,是复杂的工程和业务问题。此处做一简介,主要是为了文章结构上的完整性,不作为重点案例介绍。
SFT和RAG往往是被二选一的,也常被横向比较各自的优劣。但如果用对齐的RAG格式问答对去微调LLM,或许也是可行的。即用微调增强LLM通过{检索内容+上下文}来生成内容的能力。
2.6 多模态简介
多模态和FST一样,当然不是Agent的专有话题,但聊Agent往往也会谈到。同SFT,此处做一简介,主要是为了文章结构上的完整性,不作为重点案例介绍。多模态LLMs不仅能够理解和生成文本,还能够理解和生成与其他模态相关的信息,如图像。以GPT-4V为例:

GPT-4V
3 反思:LLM Agents 的一些问题
聊完LLM Agents的概念和部分细分技术,我们也必须认识到LLM Agents现有的问题。在此大概分解一下LLM Agents现有的一些问题:大致是绝对能力,能耗比与效率,安全,产品力这四点。
3.1 绝对能力
我将绝对能力定义为:不考虑算力和时间开销,或者说,给定极宽容的条件,一个LLM Agent最好能做到什么程度。这当然是基于细分任务去定义的。比较悲观地说:当前的LLM Agents事实上连绝对能力都是不够的。就算给定极宽容的条件,LLM Agents也解决不了很多复杂问题,甚至一些人类觉得很简单的问题。
一是因为当前的LLM本身能力不足:通用知识不够丰富,也只能做比较浅的推理。二是因为一些外部框架(如RAG)也不够灵活,比较生硬:对于RAG而言,与理想状态需要什么就能检索到什么相比,还是有一定距离。
3.2 能耗比与效率
第二点当然就是能耗比与效率了。当前的LLM Agents大多还是在一个很宽松的条件下运行的,甚至有一些模拟是某种类似“离线渲染”的做法。如果考虑能耗比与效率,比较悲观地说:绝大多数LLM Agents都会败下阵来,一无是处。LLM Agents真正落地是必须考虑能耗比与效率问题的,因为这意味着服务开销和实时性。
3.3 安全
LLM Agents的产品能力和产品安全几乎永远是双刃剑。当一个LLM Agent需要更好地为一个业务或客户服务时,就不得不获取相关业务或者相关客户的数据,来提高其服务能力。如何获取,存储,处理相关数据,都需要考虑到安全性。理解这一点最好的例子可能是支付软件的“免密支付”功能。然而,LLM Agents更有数据色彩,可能更需要考虑这些问题。
另一个方面则是LLM或LLM Agents本身的安全能力:例如幻觉问题,有害内容输出问题(安全能力好像尤其容易被SFT破坏),Prompt注入问题等等。
3.4 理想主义与产品力
LLM Agents必须面向某个场景,提供某种具体服务,而不是抽象的能力个体。当前的LLM Agents多多少少还是有一些理想主义色彩的(当然绝对不是说有一些理想主义不好,我自己就有一点理想主义)。虽说也有一些确实面向了业务,是确实有用的LLM Agents,但离“Agents遍地开花”一说,似乎还有很长的路要走。我个人最期待的是游戏场景的落地。
4 展望:与Agents有关的愿想
作为爱好者,当然会有一些愿想。我当然也有很多关于Agents的想象。这些想象,也一定程度上为我提供了一些干活的动力,本节也会相对主观一点。以下是我从脑海中复杂的愿景里抽离出的一些典型,不分好坏先后:
4.1 单兵能力
希望看到超强的单兵LLM Agents。举个具体例子的话:大概就是《ATRI》里的亚托莉这样的存在,不过不一定要有实体。具体来讲,需要看到这些方面的能力:
00001.
超强的生成能力,能耗比和实时性:生成能力当然是基础。流畅性,连贯性和一致性必须保证。再就是能耗比和实时性:效率要高,速度要快。
00002.
00003.
超强的记忆系统:只要内存管够,就能高效地存储LLM Agents原始感知输入,存储内部推理结果,存储相关环境反馈。并且能在将来真正高效地检索到相关记忆链条。
00004.
00005.
超强的知识系统:只要内存管够,就能准确存储和检索精确的知识。并且能保持知识是最新的,能够进行知识自检或高级别推理。
00006.
00007.
真正的角色一致性:即“真的像是一个具体的角色”。关于这一点,我认为CharacterEval这篇论文给出的指标比较靠谱。如下图所示,RPCA是指角色扮演会话Agent。
00008.

角色一致性的五个评价要素
|
KE(知识曝光 Knowledge Exposure):智能体在对话中展现的知识量,为后续的知识表达能力评估提供支持。
|
|
KA(知识准确性 Knowledge Accuracy):智能体能够根据角色档案中的知识,准确地生成回应。
|
|
KH(知识幻觉 Knowledge Hallucination):避免智能体在对话中创造或引用与角色身份不一致或不存在的知识。
|
|
PB(人格行为 Personality Behavior):通过描述角色的动作、表情和语调,智能体应保持一致的行为表现,以增强用户的沉浸感。
|
|
PU(人格言辞 Personality Utterance):智能体在对话中保持与角色表达习惯一致的言辞风格。
|
详见原文:
[2401.01275] CharacterEval: A Chinese Benchmark for Role-Playing Conversational Agent Evaluation (arxiv.org)arxiv.org/abs/2401.01275
4.2 游戏玩法
希望看到出色的LLM Agents+游戏玩法的成果。具体来讲,希望看到这些玩法要素:
00001.
真正能好好说话的智能NPC:比如我掏出手机给一个NPC发消息,NPC真的能根据目前的人设状况和剧情设定,动态地进行风格化回复。基本要求是:NPC真的像这个NPC在说话,没有AI味。进阶要求是:能通过智能NPC来反映世界观中的一些隐藏信息等。这是比较通用的要素,可以在大多数游戏中为沉浸感和养成系统服务。
00002.
00003.
玩法上结合LLM Agents:例如一种剧情解密类游戏,需要和NPC对话来推动一些分支或获得一些信息来帮助主线。这种想法很简单,甚至已有Demo,问题是怎么才好玩,怎么才可控,怎么才不会让玩家疲劳等。其他玩法亦可结合,但需要想象力和工程力。
00004.
4.3 私有化部署
希望看到能私有化部署的个人助理。举个例子的话,大概就是贾维斯那种,这里强调的不是能力,而是私人性。具体需要看到这些方面的能力:
00001.
绝对安全的隐私数据管理:能够让人完全安心地交付个人数据,包括隐私,健康,社交数据等,并保持更新时效性数据。
00002.
00003.
高自由度的私有定制:能根据个人行动特点进行分析,并给出相应推荐。能够以个人爱好定制语言风格和语音声线等。其他的请诸位发挥想象力。
00004.
00005.
能作为某种级别的个人代理存在:当Agent获取了个人数据,理解个人行为模式(也是数据)之后,在用户允许的情况下,能够以用户个人风格代表用户个人完成某种任务。可以进行聊天回复,邮件回复,购买物品这些行为。如果用户真的真的真的允许,甚至可以完全复刻用户的语言风格和行为模式,作为用户的数字分身。
00006.
出自:https://mp.weixin.qq.com/s/PNBr6vE7qijtm3XUYj0G2Q
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip