MLScraper是一个强大的Python库,利用机器学习和自然语言处理技术自动解析和提取网页数据。它支持各种网页类型,并提供灵活的选择器来定位和提取数据。MLScraper还具备智能识别能力和高效性能,适用于数据采集、价格比较、舆情分析和学术研究等领域。尽管在处理复杂和动态网页时可能需要额外配置,但总体上,它是一个值得推荐的网页数据提取工具。
1. 简介
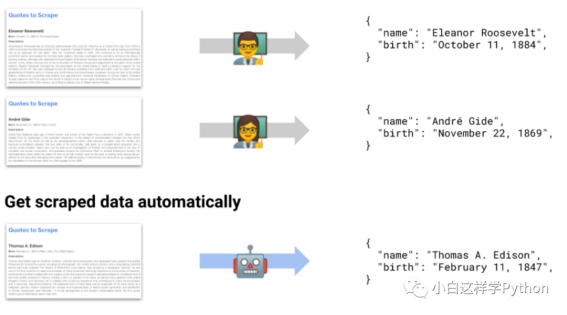
MLScraper是一个强大的Python库,用于从网页上提取结构化数据。它利用机器学习和自然语言处理技术,能够自动解析网页并提取所需的信息。MLScraper可以用于各种数据抓取和分析任务,包括网页内容提取、数据挖掘、舆情分析等。
2. 特点
MLScraper具有以下几个特点:
自动解析:MLScraper能够自动分析网页的结构,并提取出有用的数据。它可以处理各种类型的网页,包括静态网页和动态网页。
强大的选择器:MLScraper提供了灵活而强大的选择器,可以根据HTML标签、CSS选择器、XPath等方式定位和提取数据。
智能识别:MLScraper内置了智能识别算法,可以自动识别数据的类型,如文本、数字、日期等。
高效性能:MLScraper使用了高效的并行处理技术,可以快速地处理大量的网页数据。
3. 安装和使用方法
安装MLScraper非常简单,只需使用pip命令即可:
pip install mlscraper
使用MLScraper的基本步骤如下:
Step 1: 导入MLScraper库
from mlscraper import MLScraper
Step 2: 创建MLScraper对象
scraper = MLScraper()
Step 3: 指定要抓取的网页URL并执行抓取
url = "https://example.com"
data = scraper.scrape(url)
Step 4: 提取所需的数据
title = data["title"]
content = data["content"]
4. 应用场景
MLScraper可以应用于多个领域和场景:
数据采集:可以用于抓取新闻文章、产品信息、社交媒体数据等,并进行后续的分析和处理。
价格比较:可以从多个电商网站中抓取商品价格信息,用于进行价格比较和分析。
舆情分析:可以抓取社交媒体上的用户评论和观点,用于进行舆情分析和情感分析。
学术研究:可以用于抓取学术论文、研究报告等科研资料,用于学术研究和文献综述。
5. 优缺点
MLScraper的优点包括:
自动解析能力强,可以处理各种类型的网页。
提供灵活而强大的选择器,方便定位和提取数据。
内置智能识别算法,可以自动识别数据类型。
并行处理技术保证了高效性能。
MLScraper的缺点包括:
对于复杂的网页结构,可能需要手动调整选择器。
对于动态网页,可能需要额外的配置和处理。
6. 总结
MLScraper是一个功能强大的Python库,可以帮助用户快速、准确地从网页中提取结构化数据。无论是进行数据采集、舆情分析还是学术研究,MLScraper都能提供便利的解决方案。尽管在处理复杂的网页结构和动态网页时可能需要额外的工作,但MLScraper凭借其自动解析能力、强大的选择器和智能识别算法,仍然是一款值得推荐的网页数据提取工具。
出自:https://mp.weixin.qq.com/s/NgsgkBse-q1fbO_BTuc6kA
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip