“Claude 3、Gemini 1.5等大语言模型因其超长的上下文窗口,被业界视为可能终结RAG(检索增强生成)技术的流派。RAG依赖外挂知识库提供准确知识,提高生成内容质量。尽管大模型的超长上下文窗口在某些方面显示出优势,但其在速度、价值、体量和多样性等方面仍存在明显缺陷。相比之下,RAG得益于向量数据库技术,能规避这些缺陷。腾讯云发布的VectorDB向量数据库,通过提供高效的存储、检索和分析能力,成为连接数据与AI的桥梁。该数据库支持多种索引类型和相似度计算方法,并通过与英特尔合作,在CPU平台上实现显著性能加速。尽管AI模型能力不断提升,但AI系统的综合性能还需考虑其他组件的配合。因此,向量数据库等技术在AI平台化发展中仍具重要价值。”
“Claude 3、Gemini 1.5,是要把RAG(检索增强生成)给搞死了吗?”
随着新晋大语言模型们的上下文窗口(Context Window)变得越发得长,业界人士针对“RAG终将消亡”观点的讨论也是愈演愈烈。
之所以如此,是因为它们二者都是为了解决大模型的幻觉问题(即那种一本正经地胡说八道),可以说是属于两种不同顶尖技术流派之间的对峙。
一方面,以Claude 3、Gemini 1.5为代表的流派,陆续支持200K和100万token的上下文窗口,用大力出奇迹的方式让大模型能够精准检索到关键信息来提供准确答案。
另一方面,RAG则是一种外挂知识库,无缝集成外部资源,为大语言模型提供了准确和最新的知识,以此来提高生成内容的质量。
诚然有很多人在体验过超长上下文窗口大模型后,觉得这种方式已经让AI在回答的准确性上做到了突破,无需再用RAG:

而且从Claude、Gemini等玩家在测评榜单的数据来看,在回答准确性上的成绩也是屡创新高。
但事实真是如此吗?不见得。
因为在此期间,与“RAG要消亡了”背道而驰的声音也是越发坚定:

从各种评价和讨论来看,这派的观点可以概括为——你(长上下文窗口)强任你强,但缺点也是蛮明显的。
有网友便列举了长上下文窗口的四大通病(四个V):
§
Velocity(速度):基于Transformer的大型模型,在检索长上下文时要想达到亚秒级的速度响应仍然具有挑战性。
§
§
Value(价值):长上下文窗口毕竟属于大力出奇迹,但它高支出的特点对于日常应用来说,在成本上是不切实际的。
§
§
Volume(体量):即使上下文窗口越发得长,但和全网庞大的非结构化数据相比就是小巫见大巫;尤其是企业级动辄GB、TB这种体量,还涉及众多私有数据的情形。
§
§
Variety(多样性):现实世界的用例不仅涉及非结构化数据,还包括各种结构化数据,它们可能不容易被LLM捕获用来训练;而且企业场景中往往知识是需要实时变化的。
§
相反,RAG因为得益于其关键结构之一的向量数据库,反倒是可以较好地规避上述的“4V”缺陷。
向量数据库让大模型能够快速有效地检索和处理大量的向量数据,从而增强了模型的整体性能和应用范围。
一言蔽之,关键看能不能“快好省”地用起来。

△图源:由DALL·E 3生成
那么以RAG、向量数据库为代表的这一派技术,在现实场景中到底用得如何呢?
为了解答这个问题,我们找到了刚刚发布相关创新成果的腾讯云,了解了一下向量数据库以全新构建模式,作为AI知识库能为大模型等带来哪些收益?
向量数据库,已成大模型时代数据中枢
正如我们刚才提到的,RAG的重要组成部分就是外挂的专业知识库,因此这个知识库中需得涵盖能够精准回答问题所需要的专业知识和规则。
而要构建这个外挂知识库,常见的方法包括向量数据库、知识图谱,甚至也可以直接把ElasticSearch数据接入。
但由于向量数据库具备对高维向量的检索能力,能够跟大模型很好地匹配,效果也是较好的那个,所以成为了目前主流的形式。
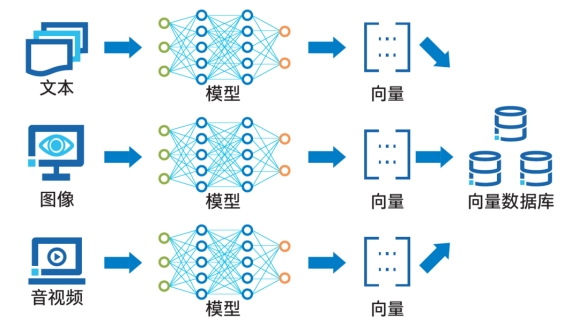 △各类数据转化为向量后存入向量数据库
△各类数据转化为向量后存入向量数据库
向量数据库可以对向量化后的数据进行高效的存储、处理与管理。
如上图展示的那样,数据向量化过程利用了诸如词向量模型和卷积神经网络等人工智能技术。
通过Embedding过程,这些技术能够将文本、图像、音视频等多种形式的数据转换成向量形式,并将其存储在向量数据库中。
至于向量数据库的查询功能,则是通过计算向量间的相似度来实现的。
而腾讯云的创新成果,就是腾讯云向量数据库(Tencent Cloud VectorDB),它能为多维向量数据提供高效的存储、检索和分析能力。
其主要特点包括:
§
Embedding功能:数据写入/检索自动向量化,无需关注向量生成过程,这意味着使用门槛被狠狠地打了下去。
§
§
高性能:单索引支持千亿级向量数据规模,可支持百万级 QPS 及毫秒级查询延迟。
§
§
低成本:只需简单操作就可以创建向量数据库实例,全流程平台托管,不需要额外的开销成本。
§
§
简单易用:不仅向量检索能力丰富,而且通过API就能快速操作和开发。
§
从这些特性不难看出,它恰好补齐了我们刚才提到的上下文窗口方式的一些短板。
也正是凭借这些优势,腾讯云向量数据库能够和大语言模型无缝对接:
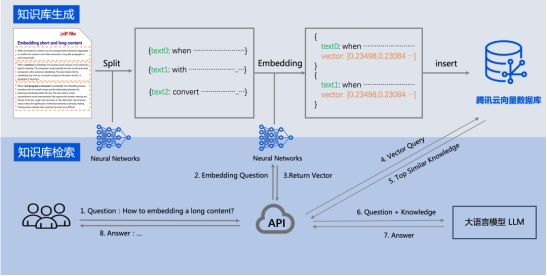
用户可以将私有数据经过文本处理和向量化后,存储至腾讯云向量数据库,从而创建一个定制化的外部知识库。
在后续的查询任务中,这个知识库也能为大模型提供必要的提示,从而辅助AGI和AIGC等应用产生更精确的输出。
由此可见,站在大模型时代之下,向量数据库已然不仅仅是一种技术工具,更是连接数据与AI的桥梁,是大模型时代的数据中枢,是整个AI平台不可或缺的一部分。
借助这一项项突破,腾讯云VectorDB不仅支持多种索引类型和相似度计算方法,还具有单索引支持千亿级向量规模、百万级每秒查询率(Queries-per-second,QPS)及毫秒级查询时延等优势。
不过这样的向量数据库又是如何搭建起来的呢?
腾讯云还有一个杀手锏——
与英特尔合作,以至强CPU平台为基础,通过软、硬件两方面的并行优化,为向量数据库提供显著的性能加速。
CPU,向量数据库的好搭档
向量数据库搭配CPU,其实不只是腾讯云一家的选择,而是整个行业现阶段的主流共识:
只有面临海量高并发需求时,使用GPU查询向量数据库才更划算。
究其原因,还要从向量数据库和CPU各自的特点,以及实际业务流程分开来看。
首先从向量数据库的角度分析,其原理上属于密集型计算负载,需要大量访问内存中加载的向量。
向量数据库与传统数据库最大的区别在于不是精确匹配,而是依靠各种相似度度量方法来找到与给定查询最相近的向量,这就涉及大量的相似度计算,如点积、欧式距离、余弦相似度等。
如此一来,除了运算速度之外,内存访问速度也很容易成为向量数据库运行中的瓶颈所在。
带着这个背景来看,CPU不但性能够用,还占据了内存访问快的优势。
对于中等或更少并发请求来说,虽然GPU单论运算速度更快,但CPU较低的内存访问时间足以抵消这个差距。
接下来,再从CPU的角度来看,它是如何来满足向量数据库运算性能需求的。
前面提到向量数据库属于密集型计算负载,谈到CPU上相关的加速技术,就不得不提我们的老朋友——从2017年第一代至强® 可扩展处理器开始就内置在这个CPU产品家族中的英特尔® AVX-512指令集。
这是一种单指令多数据(Single Instruction Multiple Data,SIMD)指令集,拥有512位的寄存器宽度,可以在一次操作中处理高维向量的所有数据。
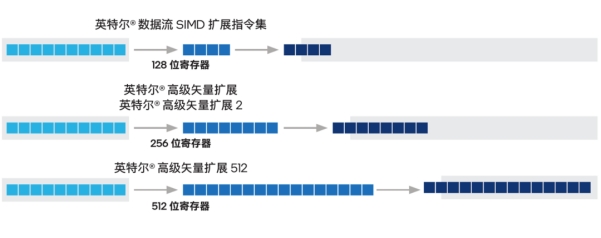 △英特尔® SSE、英特尔® AVX2和英特尔® AVX-512之间的寄存器大小和计算效率的差异说明
△英特尔® SSE、英特尔® AVX2和英特尔® AVX-512之间的寄存器大小和计算效率的差异说明
另一项可为向量数据库带来显著性能提升的是英特尔® AMX (高级矩阵扩展)加速引擎,它是从第四代至强® 可扩展处理器开始内置的加速技术,在刚刚发布的第五代至强® 可扩展处理器上也是加速器的“C位”,是大家熟悉的CPU用来加速AI应用,尤其是推理应用的核心技术。
AMX引入的用于矩阵处理的新框架,也能高效地处理向量数据库查询所需的矩阵乘法运算,并在单词运算中处理更大矩阵。
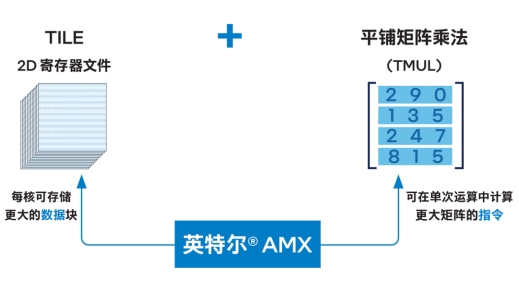
△英特尔® AMX 架构由2D 寄存器文件 (TILE) 和 TMUL 组成
在这基础上,英特尔还与腾讯云合作,针对腾讯云VectorDB常用的计算库做了专门的优化方案。
例如针对流行的FAISS相似度搜索(Facebook AI Similarity Search ),借助英特尔® AVX-512为其中不同的索引提出不同的优化方案,包括面向IVF- FLAT算法的ReadOnce(单次读取)和Discretization(离散化)两种优化思路,来执行用英特尔® AVX-512加速IVF- PQFastScan算法和IVF-SQ索引的优化方案。
针对另一种流行代码库HNSWlib,使用英特尔® AVX-512不仅能加速向量检索性能,同时还能使召回率保持平稳。
实地测试表明,在第三代至强® 可扩展处理器平台上启用英特尔® AVX-512优化后,相比没有启用优化时,使用IVF-PQFastScan算法执行向量检索时的QPS性能提升了约一倍;而把计算平台升级到目前最新的第五代至强® 可扩展处理器平台后,性能更是会提升2.3倍!
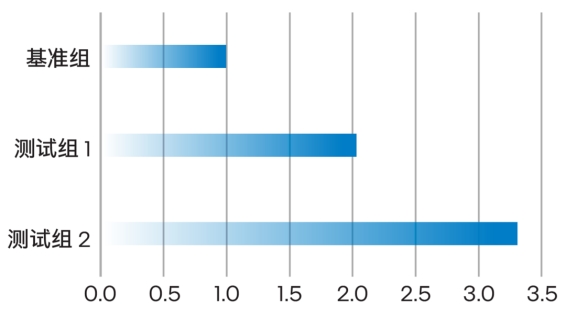
△英特尔软硬件产品与技术带来的性能提升(归一化)
还有,在使用第五代至强® 可扩展处理器的算力平台上,如果使用英特尔® AMX 加速数据格式为 INT8的测试场景,相比使用英特尔® AVX-512加速数据格式为 FP32的测试场景,性能提升可达约5.8倍。
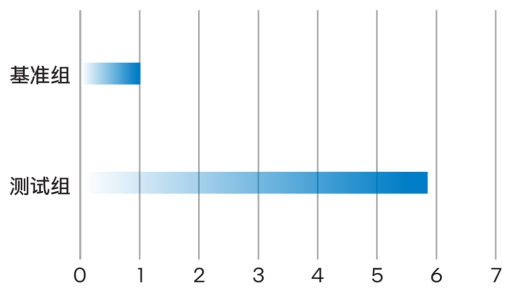
△英特尔® AMX 优化加速暴力检索的吞吐性能(归一化)
AI走向平台化,模型不是唯一主角
了解过腾讯云与英特尔的具体实践和优化成果,再来看我们最开始的讨论,答案也就明晰了。
即使AI模型能力不断加速进化,向量数据库以及整个RAG技术也没到消亡的时候。
究其原因,便是单纯的模型能力本身已经难以满足日益深入的应用落地需求,AI在落地时必须会走向复杂系统,或者说平台化。
向量数据库承载着外部知识,会在这个AI系统或平台时发挥自己的价值,但也只是其中的组件之一。
站在这个层面上看,AI系统或平台的综合能力已不只单看模型自身,还要与整个系统中其他组件相互配合。
AI系统或平台的性能效率也需要从整体考量,不仅仅取决于模型的准确性和速度。
在腾讯云VectorDB的业务实践中,最终能发现CPU是与向量数据库业务很契合,就综合性能、可扩展性、功耗、成本等因素而言是很登对的搭档,这就让CPU在直接加速一些AI应用之余,也能成为承载AI系统或平台中更多组件的基础。
这个故事的另一个主角英特尔,也在顺应这一趋势不断深入优化,既在微观上用一颗颗芯片给大模型加速,又在宏观上用CPU相关技术给整个AI系统或平台的落地、应用及实践加速。
更多CPU支持向量数据库的解决方案内容,请点击“阅读原文”获取。
参考链接:
[1]https://zilliz.com/blog/will-retrieval-augmented-generation-RAG-be-killed-by-long-context-LLMs
[2]https://www.reddit.com/r/hypeurls/comments/1b9dfo5/gemini_and_claudes_are_killing_rag/
[3]https://cloud.tencent.com/product/vdb
— 完 —
出自;https://mp.weixin.qq.com/s/VIeYOVB3_nu53KgUjIAb8A
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip