在不久的将来,我们会看到:
每个数据库都会提供某种形式的向量搜索。
其中包括图数据库、关系数据库、文档数据库以及键值数据库,甚至还包括缓存。
在不久的将来,我们会看到:
每个数据库都会提供某种形式的向量搜索。
其中包括图数据库、关系数据库、文档数据库以及键值数据库,甚至还包括缓存。
向量数据库和其他数据库之间的边界会变得模糊。
目前被分类为“向量数据库”的产品,如Pinecone、Weaviate、Milvus等,不再有竞争优势,也不再有亮点。
现有的数据库产品会利用已有的负载和客户基础来获取新的RAG(检索增强生成)负载。
其结果是,我们有必要考虑“向量数据库”是否有必要作为单独的数据库分类存在,还是仅仅是一个任何数据库都能提供的特性。
随着生成式AI的飞速发展,很大一部分的查询会以“密集向量搜索”的方式执行。相信任何数据库公司都不会无视这种负载。因此,相信绝大多数能够存储文本的数据库都会提供向量搜索。
实际上,这种“数据库的向量数据库化”正在进行中。
直到2023年第二季度之前,“向量搜索”还主要存在于数据库初创公司,如Pinecone、Milvus、Weaviate等。但现有的数据库产品很快捕捉到了这个需求,如今所有云厂商都进入了“向量搜索”市场。就连原本不卖数据库的Cloudflare也进入了市场。这是因为任何“与数据有关”的公司都想从RAG负载中分一杯羹。
2023年9月27日,Cloudflare发布了vectorize。
2023年6月22日,MongoDB发布了Atlas Vector Search
2023年6月28日,Databricks宣布了新的生成式AI工具。
2023年第四季度,IBM发布了向量数据库的预览
当然,像Elastic、微软等公司早就提供了向量数据库。
但这并不仅仅是大公司们害怕自己错失良机。现有的数据库产品提供向量搜索是合理的选择,这样就不需要将数据库移动到专门的向量数据库。同一个数据库中同时搜索向量和原始文档也能降低延迟。因此,现有的数据库进入这个市场,对客户是有利的。
一般而言,独立的向量数据库会带来额外的开销和复杂性。假如你使用MongoDB,在多个地区的数据库中保存了几亿个文档。如果使用独立的向量数据库,比如Pinecone,就意味着可能要在两个数据库之间跨地区传递数十亿个嵌入。这部分成本非常高,更不用说额外的复杂性了,因为你还要自己生成嵌入。
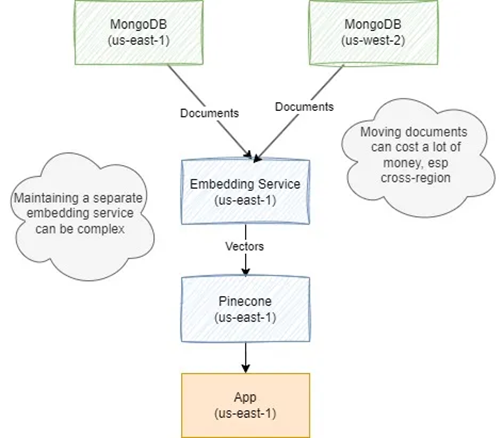
而使用一个支持向量搜索的数据库(比如Mongo或Elastic),就可以更快、更便宜、更简单。

当然,提供向量搜索也是一种防御措施。RAG是生成式AI最大的两种负载之一(另一种是推断)。不提供向量搜索意味着放弃RAG负载,就会导致客户迁移到其他数据库。这对于数据库公司是一种威胁。
现有的数据库会越来越多地支持RAG负载的整个生命周期,包括生成嵌入。
数据库会为嵌入提供越来越多的原生支持(即数据库用户只需插入文档,数据库将负责在向量存储中本地生成嵌入)。
甚至是端到端的RAG和重新排名都可能得到数据库的支持。
这种融合趋势将产生一些后果:
越来越多客户考虑使用专用的向量数据库,还是使用现有数据库的向量功能。
每个数据库都会试图介入生产中的RAG工作负载。
数据库和人工智能公司的路线图产生冲突的频率越来越高。
向量数据库初创公司的增长速度会放缓。直到2023年上半年,他们都在享受着企业购买者对于生成式AI负载不熟悉、犹豫不决而带来的红利。但是现在已经是2023年第四季度了,企业对于什么是向量搜索已经更加了解,他们更倾向于寻求与其当前数据基础设施无缝集成的解决方案。若论无缝衔接,还有比为当前数据库添加向量搜索功能更理想的方案吗?
出自:https://mp.weixin.qq.com/s/wPKKkBrAQ19naawwmAtYUw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip