
LLMs + CosyVoice实现有声电子书阅读

语音识别-SenseVoice模型: 在线官方体验网址
如果你想要快速体验语音识别SenseVoice模型的效果,你可以访问https://www.modelscope.cn/studios/iic/SenseVoice。在这里你可以体验到SenseVoice模型的语音识别和情感识别,其中界面如下: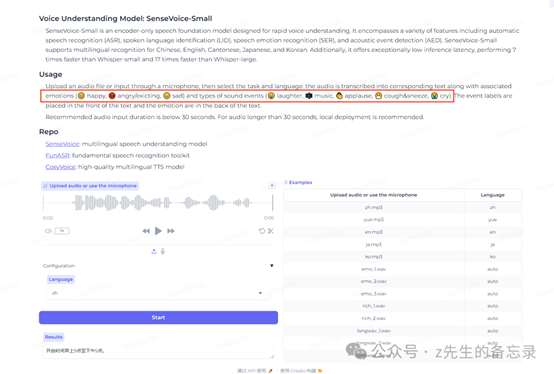
语音合成-CosyVoice模型: 在线官方体验网址
如果你想要快速体验语音合成CosyVoice模型的效果,你可以访https://www.modelscope.cn/studios/iic/CosyVoice-300M 在这里你可以体验到CosyVoice模型的三个版本对应的效果,其中界面如下:
实战篇: 语音识别模型SenseVoice模型-手把手实操部署权重推理
环境配置
这块环境配置简单了很多,对python版本要求在3.8以上,如下: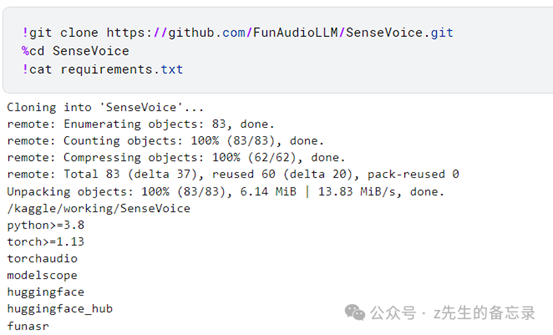 修改requirement.txt依赖文件:
修改requirement.txt依赖文件: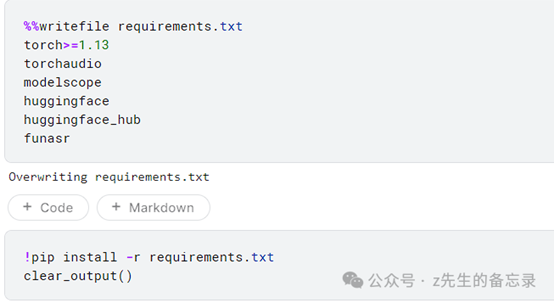
获得音频样本素材
!wget https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load("asr_example_zh.wav")
Audio(waveform, rate=sample_rate, autoplay=True)
SenceVoice音频素材,z先生的备忘录,5秒
下载模型权重
from model import SenseVoiceSmall
model_dir = "iic/SenseVoiceSmall"
m, kwargs = SenseVoiceSmall.from_pretrained(model=model_dir)
运行效果: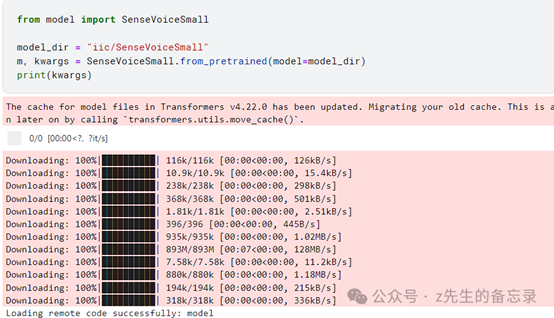
语音情感文字识别案例展示: 推理效果展示
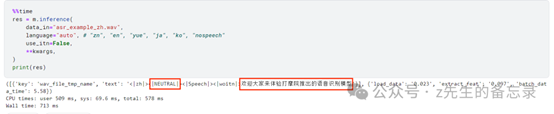 可以看出SenceVoice模型不仅能够准确识别语音文本内容,还能识别出对应说话人的情感。
可以看出SenceVoice模型不仅能够准确识别语音文本内容,还能识别出对应说话人的情感。
语音情感文字识别案例展示: 利用FunASR框架来加载推理
import funasr
print("funasr: ", funasr.__version__)
from funasr import AutoModel
model_dir = "iic/SenseVoiceSmall"
input_file = "asr_example_zh.wav"
model = AutoModel(model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
trust_remote_code=True, device="cuda:0")
 执行的效果:
执行的效果: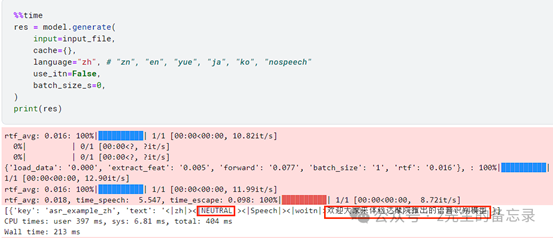
下面给大家介绍今天最核心、也是最难部署推理的语音合成CosyVoice模型对应的推理过程~
实战篇: 语音合成CosyVoice模型-手把手实操部署权重推理
下面代码全程都是在jupyter notbook中执行完成的。python环境限定在python3.8版本!!
环境部署
from IPython.display import Video,clear_output,Audio,Image
!git clone https://www.modelscope.cn/studios/iic/CosyVoice-300M.git
!git clone https://github.com/FunAudioLLM/CosyVoice.git
%cd CosyVoice-300M
!cp -r ../CosyVoice/*.wav ./
!sudo apt-get install sox libsox-dev -y
!ls
clear_output()
修改项目的requirements.txt配置依赖
%%writefile requirements.txt
--extra-index-url https://download.pytorch.org/whl/cu118
conformer
deepspeed==0.14.2
diffusers==0.27.2
gdown==5.1.0
grpcio==1.57.0
grpcio-tools==1.57.0
hydra-core
HyperPyYAML
inflect
librosa==0.10.2
lightning==2.2.4
matplotlib
modelscope
networkx==3.1
omegaconf
onnxruntime-gpu
openai-whisper==20231117
protobuf==4.25
pydantic==2.7.0
rich==13.7.1
soundfile==0.12.1
tensorboard
torch
torchaudio
pyarrow
wget
创建python3.8的虚拟环境
!conda create -y -n cosyvoice python=3.8
clear_output()
!source activate cosyvoice && pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
clear_output()
!git clone https://www.modelscope.cn/speech_tts/speech_kantts_ttsfrd.git ./speech_kantts_ttsfrd
!source activate cosyvoice && pip install ./speech_kantts_ttsfrd/ttsfrd-0.3.6-cp38-cp38-linux_x86_64.whl
clear_output()
!source activate cosyvoice &&pip list|grep torch
!source activate cosyvoice &&pip list|grep ttsfrd
!source activate cosyvoice &&pip list|grep onnxruntime
准备代合成的文本素材
当你压力大到快要崩溃的时候,不要跟别人讲,也不觉得自己委屈,没有人会心疼你。
要像余华说的那样:在夜深人静的时候,把心掏出来,自己缝缝补补,然后睡一觉醒来,又是信心百倍。
无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事情,而不是让烦恼和焦虑,毁掉你本就不多的热情和定力。
心可以碎,手不能停,该干什么干什么在崩溃中继续前行,这才是一个成年人的素养。
共计181个字。
中文女声案例展示: 对CosyVoice-300M-SFT模型推理生成音频效果展示
正入上面理论介绍所说,CosyVoice-300M-SFT版本已微调7位说话人的声音,分别是'中文女', '中文男', '日语男', '粤语女', '英文女', '英文男', '韩语女';
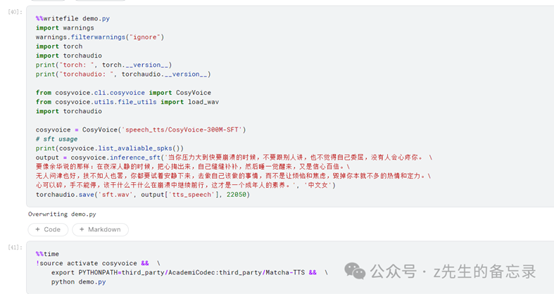 运行结果:
运行结果: 对应合成的音频效果展示:
对应合成的音频效果展示:
粤语女声案例展示: 对CosyVoice-300M-SFT模型推理生成音频效果展示
正入上面理论介绍所说,CosyVoice-300M-SFT版本已微调7位说话人的声音,分别是'中文女', '中文男', '日语男', '粤语女', '英文女', '英文男', '韩语女';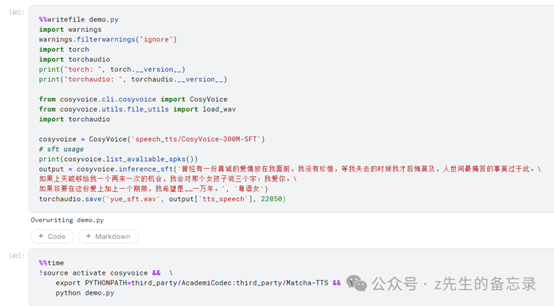 运行结果:
运行结果: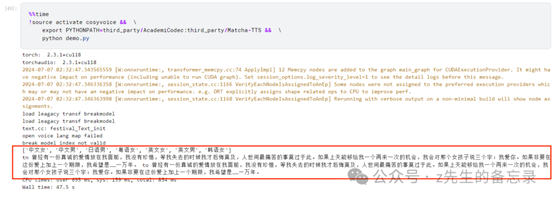 对应合成的粤语音频效果展示:
对应合成的粤语音频效果展示:
声音克隆案例展示: 对CosyVoice-300M模型零样本推理生成音频效果展示
首先我们准备音频素材,来自于CosyVoice-300M的github项目中的语音素材
import torchaudio
from IPython.display import Video,clear_output,Audio,Image
waveform, sample_rate = torchaudio.load("zero_shot_prompt.wav")
Audio(waveform, rate=sample_rate, autoplay=True)
对应的原音频素材效果如下:
编写代码进行推理
 运行的效果展示:
运行的效果展示: 对应合成的音频效果展示:
对应合成的音频效果展示:
同声翻译案例展示: 对CosyVoice-300M模型推理生成音频效果展示
首先我们准备音频素材,来自于CosyVoice-300M的官方github项目中的语音素材
import torchaudio
from IPython.display import Video,clear_output,Audio,Image
waveform, sample_rate = torchaudio.load("cross_lingual_prompt.wav")
Audio(waveform, rate=sample_rate, autoplay=True)
对应的原音频素材效果如下:
编写代码进行推理
运行的效果展示: 对应合成的音频效果展示:
对应合成的音频效果展示:
同声翻译-代码合成英文音频,z先生的备忘录,12秒
多情感细粒度展示: 对CosyVoice-300M-Instruct模型生成音频效果展示
CosyVoice-300M-Instruct模型支持的停顿词有
待合成的文本
在面对挑战时,他展现了非凡的<strong>勇气</strong>与<strong>智慧</strong>。\
他累计创造了23部恶作剧,让大家<laughter>忍俊不禁</laughter>。 \
那位喜剧演员真有才,[laughter]一开口就让全场观众爆笑。
进行推理展示
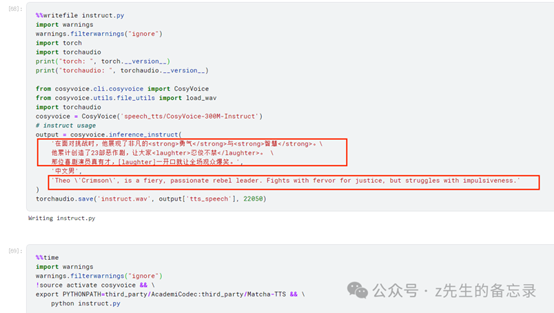 运行的效果展示
运行的效果展示
import torchaudio
from IPython.display import Video,clear_output,Audio,Image
waveform, sample_rate = torchaudio.load("instruct.wav")
Audio(waveform, rate=sample_rate, autoplay=True)
对应合成的音频效果展示:
instruct_多情感代码合成,z先生的备忘录,16秒
效果简直太哇塞啦!!跟官方展示demo效果表现几乎一致~
部署过程中常见的坑点汇总
部署遇到坑点一: 千万不要尝试除python3.8以外的python版本
刚开始我的环境版本是python3.10,开始部署CosyVoice模型,知道官方使用的是python3.8版本,结果在部署运行中花了接近4个小时,遇到各种各样的问题,果断放弃,转向搭建python3.8版本。
部署遇到坑点二:
ModuleNotFoundError: No module named 'matcha.models'
遇到这个原因主要是没有指定第三方包matcha对应的位置
%cd CosyVoice-300M # 进入项目环境
export PYTHONPATH=third_party/AcademiCodec:third_party/Matcha-TTS
#在执行对应的代码就可成功
部署遇到坑点三:
ModuleNotFoundError: No module named 'ttsfrd'
遇到这个原因主要是没有安装ttsfrd模块
!git clone https://www.modelscope.cn/speech_tts/speech_kantts_ttsfrd.git ./speech_kantts_ttsfrd
!source activate cosyvoice && pip install ./speech_kantts_ttsfrd/ttsfrd-0.3.6-cp38-cp38-linux_x86_64.whl
clear_output()
部署遇到坑点五:
Failed to load library libonnxruntime_providers_cuda.so xxx
这块主要问题是onnxruntime-gpu库的版本和cuda的依赖对不上;我在实操部署中没有指定对应的版本,最终代码运行成功对应的版本是1.8.1。
希望上面这些坑点,希望可以帮助到你~
原文:https://mp.weixin.qq.com/s/gQMgda_b7t0IL8oElMINdA