本文介绍了大型神经网络模型在训练和推理阶段的显存使用情况。文章首先解释了模型参数的单位和精度,然后详细说明了如何计算模型推理和训练时的显存需求。以Llama-2-7b-hf模型为例,文章估算了不同精度下模型推理和训练所需的显存大小,并指出模型训练所需的显存远大于推理。文章还推荐了一些优化显存使用的策略,如量化、模型切分等。最后,文章给出了模型推理服务部署的GPU配置推荐。
在前面的文章中,我们介绍了大模型占用显卡空间的一些分析情况,这次我们继续来看看具体量化角度上的结论。
因此,本文来来介绍一个偏具体数值量化的工作。
随着各厂商相继发布大型模型,排行榜变化频繁,新旧交替,呈现出一片繁荣景象。有些技术爱好者也开始心痒难耐,萌生了构建一个庞大模型并进行训练的想法。每天都能看到各个厂家推出内测版本,这让人不禁思考:为何不在本地环境尝试一番呢?然而,当前手头仅有一块性能有限的老破小GPU显卡,这就引发了一个问题:如何在这样的条件下成功运行模型?本文将引领读者探索一个切实可行的解决方案,并提出一个关键问题:如何通过模型参数量粗略估算所拥有的GPU显存是否足够?
1.1 模型参数单位
"10b"、"13b"、"70b"等术语通常指的是大型神经网络模型的参数数量。其中的 "b" 代表 "billion",也就是十亿。表示模型中的参数量,每个参数用来存储模型的权重和偏差等信息。例如:
- "10b" 意味着模型有大约 100 亿个参数。
- "13b" 意味着模型有大约 130 亿个参数。
- "70b" 意味着模型有大约 700 亿个参数。
例如:Meta 开发并公开发布的 Llama 2 系列大型语言模型 (LLM),这是一组经过预训练和微调的生成文本模型,参数规模从 70 亿(7b)到 700 亿(70b)不等。经过微调的LLMs(称为 Llama-2-Chat)针对对话场景进行了优化。
- meta-llama/Llama-2-7b-hf
- meta-llama/Llama-2-13b-hf
- meta-llama/Llama-2-70b-hf
输入:仅输入文本
输出:仅生成文本
模型架构:Llama 2 是一种使用优化的 Transformer 架构的自回归语言模型。调整后的版本使用监督微调(SFT)和带有人类反馈的强化学习(RLHF)来适应人类对有用性和安全性的偏好。
1.2 模型参数精度
模型参数的精度通常指的是参数的数据类型,它决定了模型在内存中存储和计算参数时所使用的位数。以下是一些常见的模型参数精度及其含义,以及它们在内存中所占用的字节数:
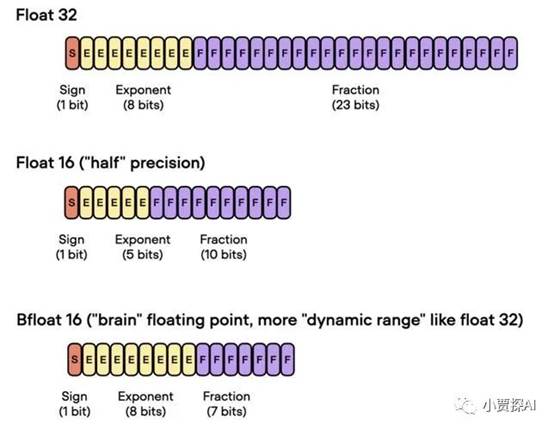
- 单精度浮点数 (32位) - float32:
- 含义:单精度浮点数用于表示实数,具有较高的精度,适用于大多数深度学习应用。
- 字节数:4字节(32位)
- 半精度浮点数 (16位) - float16:
- 含义:半精度浮点数用于表示实数,但相对于单精度浮点数,它的位数较少,因此精度稍低。然而,它可以在某些情况下显著减少内存占用并加速计算。
- 字节数:2字节(16位)
- 双精度浮点数 (64位) - float64:
- 含义:双精度浮点数提供更高的精度,适用于需要更高数值精度的应用,但会占用更多的内存。
- 字节数:8字节(64位)
- 整数 (通常为32位或64位) - int32, int64:
- 含义:整数用于表示离散的数值,可以是有符号或无符号的。在某些情况下,例如分类问题中的标签,可以使用整数数据类型来表示类别。
- 字节数:通常为4字节(32位)或8字节(64位)
注意: 模型参数精度的选择往往是一种权衡。使用更高精度的数据类型可以提供更高的数值精度,但会占用更多的内存并可能导致计算速度变慢。相反,使用较低精度的数据类型可以节省内存并加速计算,但可能会导致数值精度损失。在实际应用中,选择模型参数的精度需要根据具体任务、硬件设备和性能要求进行权衡考虑。
实际上,通常情况下并没有标准的整数数据类型为int4或int8,因为这些整数数据类型不太常见,且在大多数计算机体系结构中没有直接支持。在计算机中,整数通常以字节为单位进行存储,所以int4表示一个4位的整数,int8表示一个8位的整数。
然而,近年来在深度学习领域中,出于模型压缩和加速的考虑,研究人员开始尝试使用较低位数的整数来表示模型参数。例如,一些研究工作中使用的int4、int8等整数表示法是通过量化(quantization)技术来实现的。
在量化技术中,int4和int8分别表示4位和8位整数。这些整数用于表示模型参数,从而减少模型在存储和计算时所需的内存和计算资源。量化是一种模型压缩技术,通过将浮点数参数映射到较低位数的整数,从而在一定程度上降低了模型的计算和存储成本。以下是对这两种精度的解释以及它们在内存中占用的字节数:
- int4 (4位整数):
- 含义:int4使用4位二进制来表示整数。在量化过程中,浮点数参数将被映射到一个有限的范围内的整数,然后使用4位来存储这些整数。
- 字节数:由于一个字节是8位,具体占用位数而非字节数,通常使用位操作存储。
- int8 (8位整数):
- 含义:int8使用8位二进制来表示整数。在量化过程中,浮点数参数将被映射到一个有限的范围内的整数,然后使用8位来存储这些整数。
- 字节数:1字节(8位)
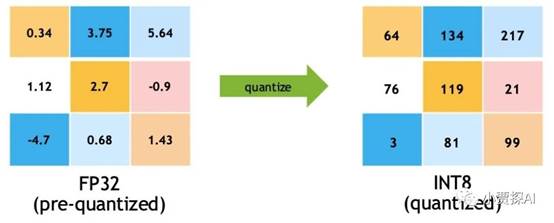
注意: 在量化过程中,模型参数的值被量化为最接近的可表示整数,这可能会导致一些信息损失。因此,在使用量化技术时,需要平衡压缩效果和模型性能之间的权衡,并根据具体任务的需求来选择合适的量化精度。
模型推理(inference)是指在已经训练好的模型上对新的数据进行预测或分类。推理阶段通常比训练阶段要求更低的显存,因为不涉及梯度计算和参数更新等大量计算。以下是计算模型推理时所需显存的一些关键因素:
- 模型结构: 模型的结构包括层数、每层的神经元数量、卷积核大小等。较深的模型通常需要更多的显存,因为每一层都会产生中间计算结果。
- 输入数据: 推理时所需的显存与输入数据的尺寸有关。更大尺寸的输入数据会占用更多的显存。
- 批处理大小BatchSize: 批处理大小是指一次推理中处理的样本数量。较大的批处理大小可能会增加显存使用,因为需要同时存储多个样本的计算结果。
- 数据类型DType: 使用的数据类型(如单精度浮点数、半精度浮点数)也会影响显存需求。较低精度的数据类型通常会减少显存需求。
- 中间计算: 在模型的推理过程中,可能会产生一些中间计算结果,这些中间结果也会占用一定的显存。
要估算模型推理时所需的显存,可以按照以下步骤:
- 模型加载: 计算模型中所有参数的大小,包括权重和偏差。
- 确定输入数据尺寸: 根据模型结构和输入数据大小,计算推理过程中每个中间计算结果的大小。
- 选择批次大小: 考虑批处理大小和数据类型对显存的影响。
- 计算显存大小: 将模型参数大小、中间计算结果大小和额外内存需求相加,以得出总显存需求或者使用合适的库或工具计算出推理过程中所需的显存。
通常情况下,现代深度学习框架(如TensorFlow、PyTorch等)提供了用于推理的工具和函数,可以帮助您估算和管理模型推理时的显存需求。
以 Llama-2-7b-hf 为例
- 因为全精度模型参数是float32类型, 占用4个字节,粗略计算:1b(10亿)个模型参数,约占用4G显存(实际大小:10^9 * 4 / 1024^3 ~= 3.725 GB),那么LLaMA的参数量为7b,那么加载模型参数需要的显存为:3.725 * 7 ~= 26.075 GB
- 如果您的显存不足32GB,那么可以设置半精度的FP16/BF16来加载,每个参数只占2个字节,所需显存就直接减半,只需要约13GB。虽然模型效果会因精度损失而略微降低,但一般在可接受范围。
- 如果您的显存不足16GB,那么可以采用int8量化后,显存再减半,只需要约6.5GB,但是模型效果会更差一些。
- 如果您的显存不足8GB,那么只能采用int4量化,显存再减半,只需要约3.26GB。
完美运行、成功上车。
注意: 上述是加载模型到显存所需大小,在模型的推理过程中,可能会产生一些中间计算结果,这些中间结果也会占用一定的显存,所以显存大小不能刚好是参数量的大小,不然就会OOM。
自我实践1:使用 RTX A6000 显卡(50GB显存)进行 70B 的 int4 量化模型部署,可正常运行。
模型训练(train)是指在给定训练数据集的基础上,通过优化算法调整模型的参数,使其能够更好地适应训练数据,并在未见过的数据上表现出良好的泛化能力。训练阶段通常比推理阶段要求更多的显存,因为涉及梯度计算和参数更新等大量计算。以下是计算模型推理时所需显存的一些关键因素:
1.模型权重
模型权重是模型参数中的一部分,通常是指神经网络中连接权重(weights)。这些权重决定了输入特征与网络层之间的连接强度,以及在前向传播过程中特征的传递方式。所以模型
2.梯度
在训练过程中,计算梯度用于更新模型参数。梯度与模型参数的维度相同。
3.优化器参数
一些优化算法(如带有动量的优化器)需要保存一些状态信息,以便在每次更新时进行调整。这些状态信息也会占用一定的显存。比如:
- 采用 AdamW 优化器:每个参数占用8个字节,需要维护两个状态。意味着优化器所使用的显存量是模型权重的 2 倍;
- 采用 经过
bitsandbytes 优化的 AdamW 优化器:每个参数占用2个字节,相当于权重的一半;
- 采用 SGD 优化器:占用显存和模型权重一样。
4.输入数据和标签
训练模型需要将输入数据和相应的标签加载到显存中。这些数据的大小取决于每个批次的样本数量以及每个样本的维度。
5.中间计算
在前向传播和反向传播过程中,可能需要存储一些中间计算结果,例如激活函数的输出、损失值等。
6.临时缓冲区
在计算过程中,可能需要一些临时缓冲区来存储临时数据,例如中间梯度计算结果等。减少中间变量也可以节省显存,这就体现出函数式编程语言的优势了。
7.硬件和依赖库的开销
显卡或其他硬件设备以及使用的深度学习框架在进行计算时也会占用一些显存。
以 Llama-2-7b-hf 为例
- 数据类型:Int8
- 模型参数: 7B * 1 bytes = 7GB
- 梯度:同上7GB
- 优化器参数: AdamW 2倍模型参数 7GB * 2 = 14GB
- LLaMA的架构(hidden_size= 4096,
intermediate_size=11008, num_hidden_lavers= 32, context.length = 2048),所以每个样本大小:(4096 + 11008) * 2048 * 32 * 1byte = 990MB
- A100 (80GB RAM)大概可以在int8精度下BatchSize设置为50
- 综上总现存大小:7GB + 7GB + 14GB + 990M *
50 ~= 77GB
Llama-2-7b-hf模型Int8推理由上个章节可得出现存大小6.5GB, 由此可见,模型训练需要的显存是至少推理的十几倍。
备注:模型训练所需GPU显存是本地笔记本所不能完成的,但是我们一般正常使用模型的预测推理服务还是没多大问题的
显存的总占用可以通过将上述各部分的大小相加来计算。在实际应用中,需要根据模型结构、数据批次大小、优化算法等因素来估计和管理显存的使用,以防止内存不足导致训练过程中断。使用一些工具和库(如TensorFlow、PyTorch等)可以帮助您监控和管理显存的使用情况。实际影响显存占用的因素还有很多,所以只能粗略估计个数量级。
监听显卡,每
1 秒刷新一次:watch
-n -1 -d nvidia-smi
模型推理服务部署GPU配置推荐如下:

了解了模型训练、模型推理时显存计算情况后,优化的思路方向也就有了,比如:使用当前比较主流的一些分布式计算框架 DeepSpeed、Megatron 等,都在降低显存方面做了很多优化工作,比如:量化、模型切分、混合精度计算、Memory Offload 等,后续再给大家分享,敬请期待~
https://discuss.huggingface.co/t/llama-7b-gpu-memory-requirement/34323/6
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip