大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计
大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计(参考:需要多少GPU显存才能运行预训练大语言模型?大语言模型参数规模与显存大小的关系估算方法~:http://https//www.datalearner.com/blog/1051692326904222)。而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。

·
大模型显存计算工具Model Memory
Calculator简介
·
·
使用Model Memory
Calculator估算大模型显存的实测
·
·
大模型显存估计工具Model Memory
Calculator的本地部署
·
·
大模型显存估计工具Model Memory
Calculator的在线演示地址和其它注意
·
大模型显存计算工具Model Memory Calculator简介
Model Memory Calculator是HuggingFace的Accelerate推出的一个网页工具,你可以直接输入HuggingFace上某个模型地址,它就会估计这个模型运行所需要的显存大小,包括推理和使用Adam进行训练的显存估计。
这个工具估算大模型最小推荐显存资源的方式是用最大层的大小(the minimum recommended vRAM)来表示的。而训练这个模型所需的训练的显存大小,则是这个推理大小的4倍左右。
在许多深度学习模型中,尤其是Transformer类模型,层与层之间的操作往往需要在vRAM中存储中间计算结果,这些结果可能包括激活值、权重等。最大的一层可能需要最大的vRAM空间来存储这些中间结果,以进行前向和反向传播。
考虑到模型的反向传播需要存储前向传播中的激活值以计算梯度,这意味着在训练过程中需要为模型的每一层都存储其激活值。最大的层的激活值可能会占用最多的vRAM。因此,这样估计相对比较保险。
但是根据这样的计算应该也不是简单的直接拿最大层参数来计算。根据官方的说法,最准确的时候,这个工具估算出来的显存大小与实际估计的误差可能也就50MB左右(例如,bert-base-cased模型实际运行需要413.68MB,而这个工具估算的结果是413.18MB)。
使用Model
Memory Calculator估算大模型显存的实测
这个工具的使用非常简单,如下图所示,你只需要找到对应的模型所在的HuggingFace地址,直接输入到下面就可以计算了。还可以根据float32、float16、int8、int4量化结果估算。
下面我们使用这个工具估算一下清华大学ChatGLM-6B模型的结果(第一代的ChatGLM-6B模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/ChatGLM-6B )。
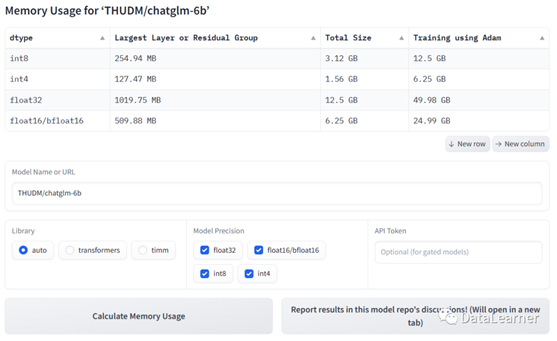
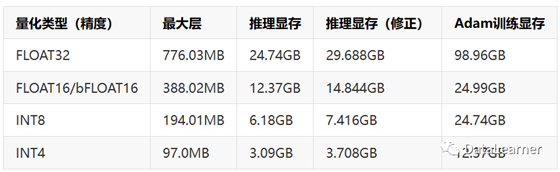
可以看到,该工具估算的ChatGLM-6B模型在不同精度下的训练和推理的显存需求结果如下:
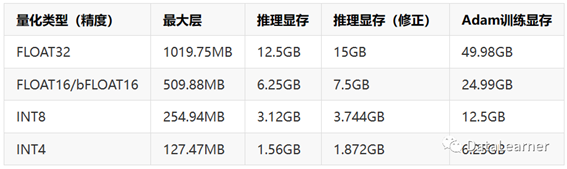
上图的第三列上图的第三列表示推理显存乘以1.2的结果。原因在于EleutherAI在曾经的技术分析中提到推理所需的实际显存可能要比计算结果高20%左右。下面我们看一下官方给的结果:
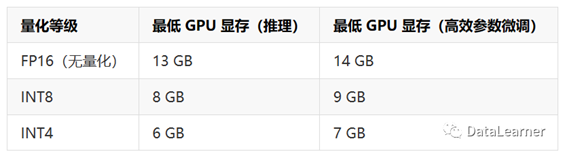
可以看到,该工具估算的显存大小与实际官方推荐的差别还是比较大的。但是,我们再估算一下MetaAI发布的LLaMA2-7B的结果,LaMA2-7B模型在不同精度下的训练和推理的显存需求结果如下:
而根据网络上大家讨论的内容,
llama-2-7b-chat载入大概需要15GB显存,这个应该是float16版本,与预估结果十分相似!
可以看到,不同的模型很多结果差异还是挺大的。但是,总体来说,还是很有参考价值的!
大模型显存估计工具Model Memory Calculator的本地部署
这个库也可以本地使用,使用过程应该还是需要联网才能估算(需要访问HuggingFace的模型配置文件)。
Model Memory Calculator的安装很简单。首先安装依赖的accelerate库:
1.
pip
install git+https://github.com/huggingface/accelerate.git
2.
需要注意的是,也要安装jaxlib:
1.
pip
install jaxlib
2.
如果提示jaxlib版本问题你可能要升级。
接下来先在本地输入自己的HuggingFace的密钥,首先需要在页面生成token:https://huggingface.co/settings/tokens
然后复制token后,运行如下命令配置:
1.
huggingface-cli
login
2.
如下图所示:
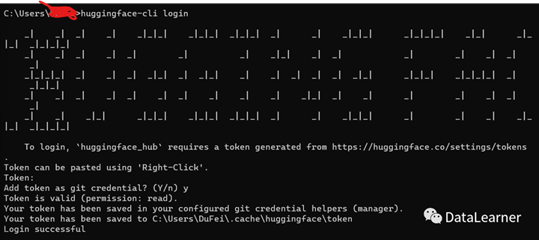
运行到这里的时候Token:输入上面你复制的token即可。接下来就可以直接运行了。
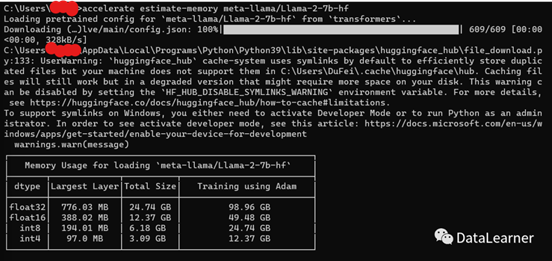
估算MetaAI的LLaMA2-7B-HF模型的显存大小:
1.
accelerate
estimate-memory
meta-llama/Llama-2-7b-hf
2.
结果如下所示:
在线演示地址和其它注意事项
大模型显存估计工具Model Memory
Calculator的使用地址参考原文末尾。
需要注意的是,该工具如果访问的是需要授权的页面,如上图所示的llama2-7b,是需要先用huggingface账户获取授权,然后获得你的token才能访问的。虽然上面演示页面提供了API Token的输入,但是是有问题的,这个部署不好。但是我们可以自己本地部署方式。
出自:https://mp.weixin.qq.com/s/YQ0xlpzXqYyERMKOdiCECQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip